《Python神经网络编程》是一本非常优秀的神经网络入门编程书,作者手把手从安装环境开始,每一行代码都是在树莓派上就能运行的,甚至可以说不需要什么第三方库,仅仅用了矩阵的优雅和力量,就能够在树莓派上顺利的运行。
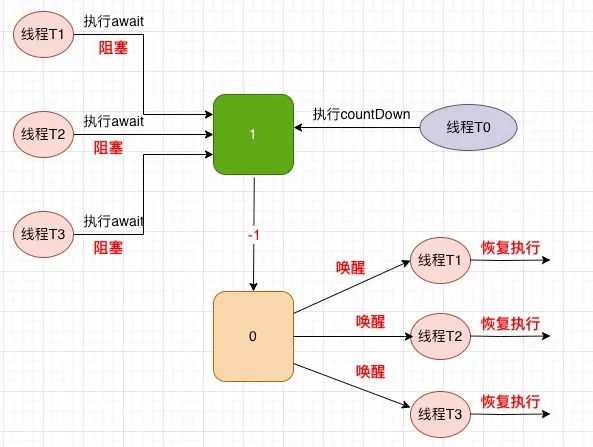
仅仅是这样简单的代码实现,就实现了神经网络的前馈信号计算、误差反向传播、并且通过梯度下降优化链接权重。
正如作者所说,如此少的的隐藏层节点和学习场所。就达到这样的效果,充分的展示了矩阵和神经网络的优雅与力量。

宇宙的神奇美妙之处正在于这里,神经元的闽值机制,就像量子,只有在特定能级之间,达到特定能量才能跃迁。激活函数消除了信号较弱的噪声,从而过滤了数据中的杂音。
正因为如此,信息本身需要用大量样本数据去噪,通过正则化和丢弃、残差等方法处理信号,可以优化过拟合和梯度相关的问题。
一个很明显的关于噪声和数据的例子是,MNIST数据集本身就是消除了各种噪声的数据,因此小的网络层数和节点数,就足以有效识别信号。
真正比较耳目一新的,是作者对神经网络运行原理的解释,激活函数通过阈值过滤噪声,从前馈信号中计算和反向传播误差时的矩阵乘法;如何更新权重和设置初始值也是很直观的。虽然这本书没有实现一个框架或者复杂的注意力机制,还是麻雀虽小,五脏俱全。
我在想,人脑目前在智能上的优势至少有一点,是人的大脑神经元和连接的数量,是可以随着学习过程此消彼长,动态演化的,一个特定神经网络的节点数和网络层数、学习率一开始就是固定的,只能通过随机过程调优成另外一个网络。
计算机的优势是像时间机器一样,不知疲倦,可以通过人类的所有能源技术和计算技术,短时间内处理巨大的数据量。
另外关于数据,至少在这一点上,工程化也是类似的,要完美的测试软件,对于业务越复杂的系统,比代码越难维护的,反而是数据,尤其是随时能反映系统和业务变化的数据的维护。