关联比赛: 第二届海南大数据创新应用大赛 - 智能算法赛
第二届海南大数据创新应用大赛 - 算法赛道冠军比赛攻略
首先很幸运能拿到这次初赛冠军,本着积极学习和提升自我的态度,团队成员通力合作是获胜关键,再次感谢。
赛题背景分析和理解
本次大赛是海南省大数据管理局成立后,联合阿里天池举办的比赛,旨在提升海南大数据应用水平和支撑海南自由贸易港建设。大赛提供了2000份脱敏之后的中文人才简历数据和标注数据,参赛选手通过人工智能技术构建预测模型预测简历中涉及的18个标注类别字段。即给定PDF格式的简历标注出涉及标注类别字段的内容。
看了赛题描述,称构建以人为主题的人才知识图谱库,形成人与人、人与企业、人与学校等之间的关联关系,一开始以为是知识图谱,其实这是一道信息抽取ERE的问题。ERE是个级联任务,主要分为实体抽取和关系抽取两个子任务,从样本分析可以看出一个类别多实体的问题,可以将其转换成联合抽取实体+关系的”三元组”信息抽取,即“一对多”抽取+分类任务。
提供数据
几类常见非标准简历格式模板的人工构造数据,共2000份训练数据。
标注类别包括:姓名、出生年月、性别、电话、最高学历、籍贯、落户市县、政治面貌、毕业院校、工作单位、工作内容、职务、项目名称、项目责任、学位、毕业时间、工作时间、项目时间共18个字段。
18个字段共分为三类,分别是:
普通字段: 姓名、出生年月、性别、电话、最高学历、籍贯、落户市县、政治面貌;
普通列表字段: 学位、毕业时间、工作时间、项目时间;
字符级列表字段: 毕业院校、工作单位、工作内容、职务、项目名称、项目责任;
评估指标:Macro Weighted F1
$$ P_i=\frac{TP_i}{TP_i+FP_i} $$
$$ P_{weighted}=\sum\limits_{i={1}}^{n}P_i×ω_i $$
$$ R_i=\frac{TP_i}{TP_i+FN_i} $$
$$ R_{weighted}=\sum\limits_{i={1}}^{n}R_i×ω_i $$
$$ MacroWeighted F1=\frac{2×P_{weighted}×R_{weighted}}{P_{weighted}+R_{weighted}} $$
普通字段和普通列表字段均使用字段级别的F1值;字符级列表字段使用字符级别的F1值进行计算,会首先依据最长公共子序列与真实label进行匹配,再进行F1值的计算。所有字符串均会去除空格后与标准答案进行比对。
样本特点
通过人工观察样本情况,发现特点如下:
-
从一份PDF简历中抽取关于18个类别的内容,且只处理抽取任务,不做推理,不额外添加信息;关于简历中出现的单个“男”“女”依然认为是性别的有效信息;考虑从三元组入手处理,每份简历中s为姓名,p为18个类别,o为内容。
-
样本中列表的抽取结果是“一个s、多个(p, o)”的形式,比如(李冠光,毕业院校,北京师范大学),(李冠光,毕业院校,北京林业大学)。
-
通过观察样本PDF包含的几种常见非标准简历格式,发现折行和竖排问题,需要从PDF中抽取正确的文本顺序,才能保证后面的抽取任务的准确度。
核心思路
从样本特点可以看出,除了要正确处理PDF内容,其它为信息抽取任务的常见特点,通过简单的调研PDF抽取工具和信息抽取模型、方法,我们设计PDF抽取。
PDF折行和竖排问题
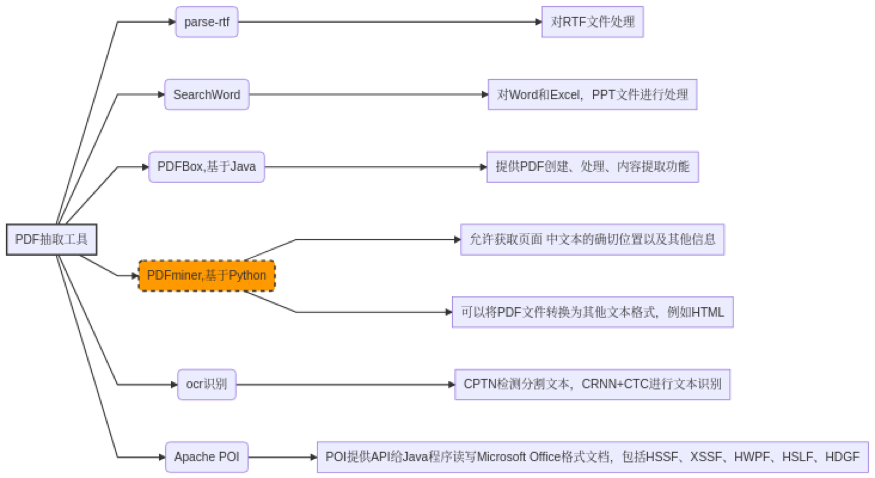
模型训练和预测有时间限制,为保证效率,我们使用PDFminer提取出文本坐标,并根据以下算法进行抽取:
- 先根据文本中的划线分隔符,区分文本是左右结构还是非左右结构。先使当前Y坐标大于当前行的Y坐标,然后重新遍历每个字到当前字的位置止,找出X最大坐标的字,判断当前的字的X坐标是否大于X最大坐标字的X坐标;
- 对于非左右结构的文本,则以从左到右、从上到下的方式进行遍历;
- 对于左右结构的文本,则先对左边的文本以非左右结构的方式进行遍历,并判断当前字是否在块内,遍历完左边块之后,再以相同的方式遍历右边块内容;
- 在遍历的过程中同样需要判断前后字是否在同一行,即判断当前的Y坐标是否和上一个Y坐标相同,相同即同行,不相同则看后面的字的Y坐标是否相同,相同同行,如果还是不相同,则看后面字的Y坐标在当前行Y坐标和当前字的Y坐标区间内,且后面字的Y坐标和行坐标是否差10个点行间距,反之不同行。
抽取出正确顺序的文本,可以进入正常的信息抽取环节了。
整体思路
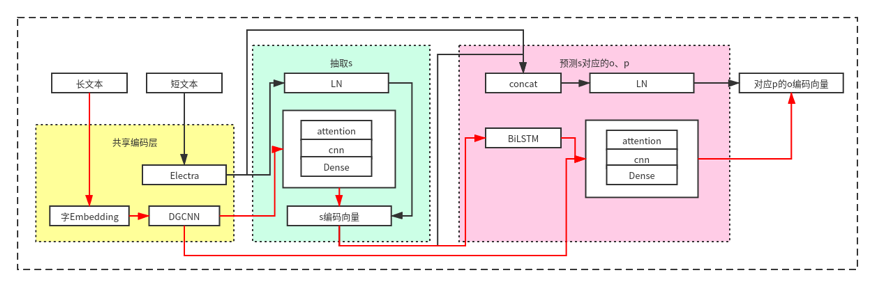
模型设计
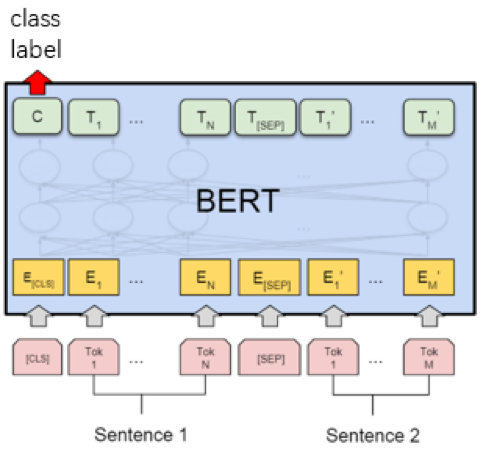
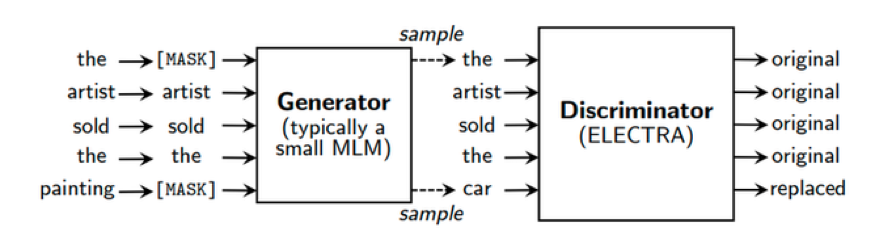
目前BERT大热,效果惊人,所以这次比赛中我们也没有过多的思考,直接选BERT。只是因为BERT处理长度受限于512个字节,对于长文本的处理,最终还需借助CNN+Attention结构。在比赛群里交流,发现一个有意思的现象,大家线下都是验证集99%的准确率,线上就翻车了,开始我们也遇到这个问题,主要原因还是训练数据集是官方造的几种类型的简历模板,线下过拟合了,线上测试还存在550余份真实简历数据,也就是说在测试集会出现unseen的样本。针对这种情况,我们引入外部简历数据采用半监督和对抗训练的方式,进行了一些实体替换增强。我们还尝试切分不同训练集对模型进行加权融合,线上效果没有得到提升。刚好比赛结束前几天,Electra模型发布,基于硬件限制,我们最终将模型换成Electra模型,性能提升1%左右。
Trick
-
此次比赛任务提分的一个关键是需要解决PDF竖排和折行问题。大道至简,我们通过引入是否左右结构和是否位于同一行的判断,解决了这个问题。
-
针对较长文本,借助半标注-半指针模型完成信息对症抽取。
-
引入外部数据半监督学习增加训练数据量,通过前程无忧爬取、从公司HR手上收集到的简历,使用比赛中的原始数据构建筛选模型(Bert+Dense),然后对外部简历数据进行预测,针对p关系的o编码向量位置替换实体。这里我们还通过PDF文本坐标信息进行了规则修正。
-
引入对抗训练。
目标:
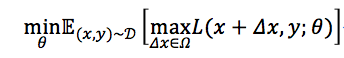
D代表训练集,x代表输入,y代表标签,θ是模型参数,L(x,y;θ)是单个样本的loss,Δx是对抗扰动,Ω是扰动空间。这个统一的格式首先由论文[《Towards Deep Learning Models Resistant to Adversarial Attacks》提出。
-
保证“看起来一样的结果”下,L(x+Δx,y;θ)越大越好,尽可能让现有模型的预测出错。
-
针对这种对抗方式找到最小化loss去更新θ,也就是找到最鲁棒的模型参数去防御。
Fast Gradient Method(FGM):

《对抗训练浅谈:意义、方法和思考(附Keras实现) 》[Blog post]. Retrieved from 对抗训练浅谈:意义、方法和思考(附Keras实现) - 科学空间|Scientific Spaces
-
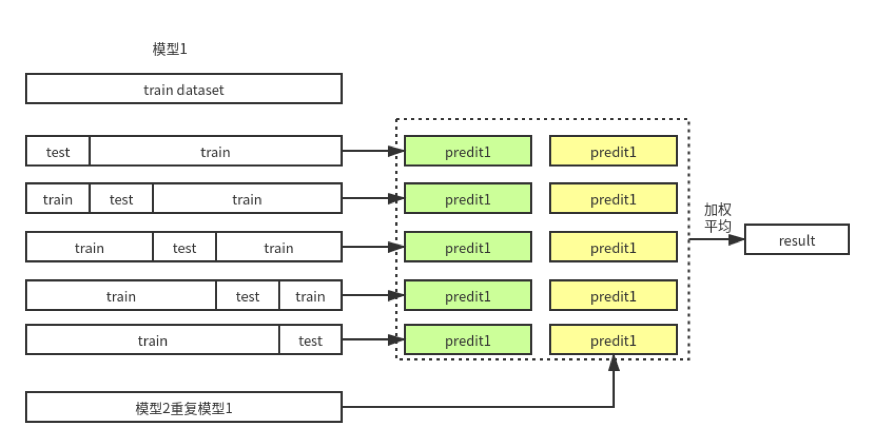
多模型融合,通过训练集五折交叉验证两个BERT模型,进行加权求平均。
-
引入轻量预训练模型,将共享编码层Bert模型更换成Electra模型,准确度提升1%左右。
比赛经验总结和感想
- 此次比赛任务解决PDF竖排和折行问题后,使用普通的BERT预训练模型便可达到78+的准确度量级,并且该算法迁移到其它项目中同样具有落地性。
- 数据增强和模型融合是有效的提升手段,模型融合这块线下预测acc有提高,线上预测性能没有提升,还需进一步探究。
- 准确度和时间复杂度不可兼得,如何满足现实中速度和性能的平衡,还需进一步探究。
- 作为海南本土的互联网企业,抱着积极学习和提升自我的态度,希望能在比赛中将公司多年积累的技术经验运用在人才数据智能服务体系的实际项目中,验证其落地性和实用性。希望可以为海南自由贸易港的快速发展、全省信息化大数据的创新建设贡献一份力量。
查看更多内容,欢迎访问天池技术圈官方地址:第二届海南大数据创新应用大赛 - 算法赛道冠军比赛攻略_海南新境界队_天池技术圈-阿里云天池