近日,阿里云人工智能平台PAI与华南理工大学金连文教授团队合作,在自然语言处理顶级会议 ACL 2024 上发表论文《DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation. ACL 2024》。DiffChat算法是一个文到文的多轮生成模型,可以根据用户的需求指令对原始提示词进行适当的修改,得到新的提示词来使得文到图生成模型能够生成更美观且符合指令的图像。整个过程做到了用户和文图生成模型的迭代交互,最终完成用户的创作需求。
背景
基于扩散模型的文图生成模型(如Stable Diffusion)的效果有时会受到输入文本即提示词撰写的影响。当用户对创作的图像有特定需求或者希望执行特定的内容修改时,通常需要进行反复多次的提示词修改,且每次尝试的结果都是不可预期的。 这造成了不可忽略的时间和计算资源的耗费。基于这一问题,我们希望设计出自动的可以根据用户的需求指令对原始提示词进行适当修改的方法。
自动化数据收集方案
DiffChat模型的目标是在给定原始提示词/图像和用户指令的情况下,生成用于互动式图像创建的目标提示词。为了实现这一点,我们首先需要构建一个高度相关的数据集。为了解决这个问题,我们首先创建了一个提示词美化模型。我们从开源资源中收集了大量的真实世界高质量提示词。接下来,我们请求ChatGPT将这些高质量提示词总结为简化的提示词。通过这种方法,我们获得了大量的<简化,高质量>提示词对,这些将被用来微调一个BLOOM-1.1B模型而作为我们的提示词美化模型。

如上图所示,我们的InstructPE数据集的收集过程即可以开始进行。基于InstructPix2Pix数据集,我们做出如下处理:将InstructPix2Pix的原始提示词和目标提示词
分别送到我们的提示词美化模型,以生成美化后的
和
。接下来,由于提示词美化模型在生成过程中不可避免地会面临丢失关键词的风险,我们根据(
–>
)或(
–>
)哪一组保留了更多关键词来决定是使用模板
还是
与ChatGPT进行下一步的互动。这样操作的原因是我们希望尽可能保持修改后的提示词与原始提示词之间的一致性。例如,如果(
–>
)保留的关键词比(
–>
)多,我们将设置
为已知参考,并让ChatGPT生成
,反之亦然。接着,给定
或
以及指令
,我们利用提示词工程技术请求ChatGPT写出另一个(
或
)。最终,我们的InstructPE数据集组织形式为(
)。
通过以上这种方法,我们就获得了大量的三元组数据。此外,我们对其进行进一步的数据清理和过滤。首先过滤掉非英语和包含色情、政治敏感等不适合工作场景的数据,并对图片的美观值进行了筛选。我们最终收集了234,786个三元组作为训练集,5,582个三元组作为测试集。我们将其命名为InstructPE数据集。
算法架构
给定包含输入提示词、指令和目标提示词的InstructPE数据集三元组,我们微调一个解码器结构的语言模型,以输出高质量提示词。我们使用自回归语言建模目标来最大化以下似然函数:
其中是一个模板,用于将
和
组织成前缀句子。
由于收集到的数据集不可避免地含有噪声,例如目标提示词并不严格遵循相应的输入提示词和指令,因此微调后的模型的性能可能不足以令人满意。为了进一步发展,我们使用强化学习算法进一步增强模型表现。在基于近端策略优化(PPO)的强化学习算法中,代理模型需要从环境中获取奖励反馈,以便朝着期望的方向更新其策略。 而在我们的任务中,奖励必须反映用户对于图像创作所关心的问题。
对此,我们设计了三个用户所关注的标准:
(1)美学。它代表了所创建图像的美学评价。
(2)偏好。它表示用户对指定图像相对于其他图像的偏好程度。
(3)内容完整性。它评估了目标提示词中包含的关键内容的完整性。
我们旨在使用现有的AI模型以及自设计的启发式规则来对生成的图像结果自动打分,从而避免昂贵的人工标注成本。具体而言,我们使用aesthetic score和PickScore分别作为我们的美学和偏好标准指标。 此外,我们还自行设计了内容完整性评分,它启发式地提取出提示词和指令中的关键信息,然后根据目标提示词对这些关键信息的包含度和完整性是否达到阈值来决定是否给予奖励。


实验结果
我们基于BLOOM-1.1B进行实验,作为DiffChat的主干网络。选择这个相对较小的版本是为了确保高推理效率,以支持现实世界的应用。我们的方法不依赖于特定模型的选择。
系统地评估提示词生成模型的优劣是一项具有挑战性的任务。其中最直接的方法之一就是自动化地评估使用模型产生的提示词所生成的图像。我们使用了Stable Diffusion 1.5, Deliberate, Dreamlike, Realistic, Stable Diffusion XL 1.0等模型来验证结果。如下表所示:
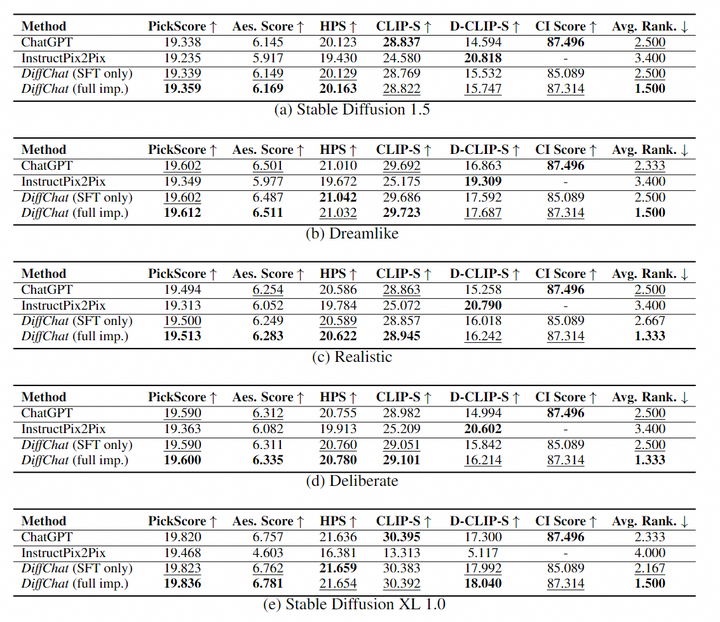
我们可以看出,我们的算法能够与现有的多个文生图模型进行协作以实现更高图像质量的创作,这证明了DiffChat算法的优越性。一些和InstructPix2Pix对比的例子如下所示:

参考文献
-
Tim Brooks, Aleksander Holynski, and Alexei A Efros. 2023. InstructPix2Pix: Learning to follow image editing instructions. In CVPR, pages 18392–18402..
-
Tingfeng Cao, Chengyu Wang, Bingyan Liu, Ziheng Wu, Jinhui Zhu, and Jun Huang. 2023. BeautifulPrompt: Towards automatic prompt engineering for text-to-image synthesis. In EMNLP, pages 1–11.
-
Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cotterell. 2023. Locally typical sampling. Transactions of the Association for Computational Linguistics, 11:102–121.
-
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman ´ Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. BLOOM: A 176b parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
-
Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, and Wei Lin. 2022. EasyNLP: A comprehensive and easy-to-use toolkit for natural language processing. In EMNLP, pages 22–29.
论文信息
论文名字:DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
论文作者:汪嘉鹏、汪诚愚、曹庭锋、黄俊、金连文
论文pdf链接:https://arxiv.org/abs/2403.04997
阿里云人工智能平台PAI长期招聘研究实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态AIGC大模型的应用算法研究和应用。简历投递和咨询:chengyu.wcy@alibaba-inc.com。










![[书生大模型实战营][L0][Task2] Python 开发前置知识](https://i-blog.csdnimg.cn/direct/1bde2408daaa41c888065d06d9cccc70.png#pic_center)