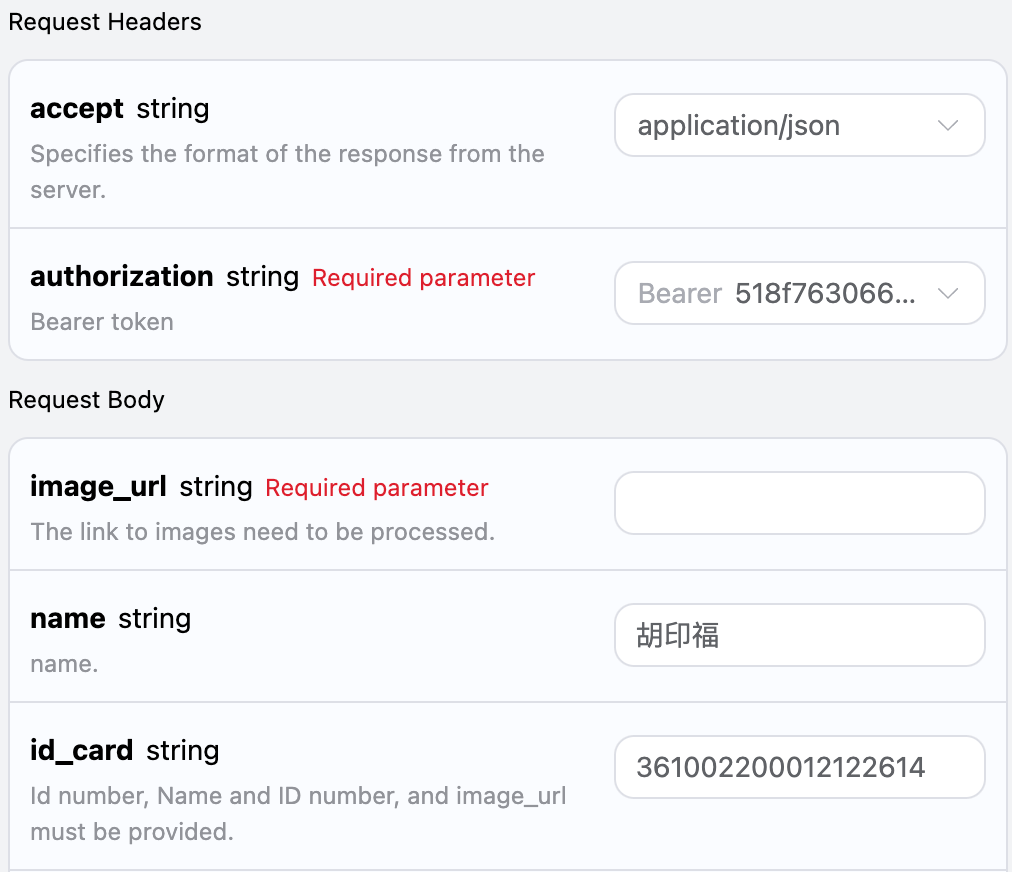
我们在上一节已经简单的介绍了一下 Netty 的事件调度,可以说 Netty 高性能的奥秘主要就在于其核心的事件循环和任务处理引擎,那么它究竟是如何实现的呢?这一节我们来详细探讨一下
Reactor 线程模型
在解释 Netty 事件循环的实现原理前,我们需要先了解一下 Reactor 线程模型。在早期的网络服务端,一般都采用阻塞式 IO 模型,为每个新连接都分配一个独立的线程去处理,由于线程需要消耗不小的系统资源,所以阻塞式 IO 模型没办法支撑大量的网络连接,但在这种模型下,线程实际上大量的时间都消耗在等待 IO 上,实际上有效工作的时间很短。(如果想详细了解这一部分,可以参考 深度解析响应式编程 )
为了节约系统资源,提升处理效率,后来又提出了IO 多路复用的概念,其核心思想就是仅用一个单独的线程去检查网络连接的 IO 状态,仅当连接的 IO 处于就绪状态时才会通知应用程序进行相应的处理,这样就可以极大的减少处理大量网络连接时所需要的线程数。目前主流的操作系统都有自己的 IO 多路复用的实现,包括 select,kqueue,epoll 等。
有了 IO 多路复用的技术之后,那么 Reactor 线程模型就可以正式登场了。Reactor 实际上是一种事件驱动的设计模式,它的核心思想在于将将事件的检测和处理分离,而事件的检测(这里主要指 IO 事件)就是依赖于 操作系统提供的 IO 多路复用技术。最早提到 Reactor 模型的是 Doug Lea 的《Scalable IO in Java》,里面介绍了 Reactor 模式的三种线程模型:单线程,多线程和主从 Reactor 模型,我们分别来看一下:
单线程模型

在 Reactor 单线程模型中,所有 I/O 操作(包括连接建立、数据读写、事件分发等),都是由一个线程完成的。单线程模型逻辑简单,缺陷也十分明显:
- 一个线程支持处理的连接数非常有限,CPU 很容易打满,性能方面有明显瓶颈;
- 当多个事件被同时触发时,只要有一个事件没有处理完,其他后面的事件就无法执行,这就会造成消息积压及请求超时;
- 线程在处理 I/O 事件时,无法同时处理连接建立、事件分发等操作;
单线程模型太过简陋,基本不会用于生产环境,除非事前就能够确定服务端仅需要支持极少量的连接。
多线程模型

在多线程模型下,Reactor 运行在一个独立的线程中(非 Thread Pool 中的线程),主要负责响应 IO 事件,把事件分发给相应的处理代码 (Acceptor,Handler)。
Acceptor : 用以接受客户端的连接请求,然后创建 Handler 对连接进行后续的处理(读取,处理,发送数据),与 Reactor 运行于同一线程。
Handler : 事件处理类,用以实现具体的业务逻辑。图中 read,decode,compute,encode 和 send 都是由 handler 实现的。
Thread Pool : Thread Pool 中的 thread 被称作 worker thread。Handler 中的 decode,compute 和 encode 是用 worker thread 执行的。值得注意的是 Handler 中的 read 和 send 方法是在 Reactor 线程而不是 worker thread 中执行的。这意味着对 socket 数据的读取发送数据和对数据的处理是在不同的线程中进行的.
多线程模型相对于单线程模型,提升是十分明显的,但仍然存在一些缺陷:
-
read 和 send 会影响接受客户端连接的性能:前面分析过 read 和 send 是在 Reactor 线程中执行的,接受客户端的连接请求也是在 Reactor 线程中执行。这使得如果有 read 或者 send 耗时较长,会影响其他客户端连接的速度。
-
线程带来额外开销:前面提到的处理客户端请求的步骤依次是 read,decode,process,encode,send。由于 read 和 send 是在 Reactor 线程中执行,而 decode,process 和 encode 是在 worker thread 线程中执行,引入了额外的线程切换开销,这种开销在高并发的时候会体现出来。
主从 Reactor 多线程模型

主从多线程模型由多个 Reactor 线程组成,MainReactor 仅负责处理客户端连接的 Accept 事件,只有一个。由于 MainReactor 仅处理连接事件,不再受到 read,send 事件的干扰,也就避免了上面提到的第一条缺陷。
而连接建立成功后 MainReactor 会将新创建的连接对象注册至 某个 SubReactor,并将其与线程池中的 I/O 线程绑定,它将负责连接生命周期内所有的 I/O 事件。在这种模型下,SubReactor 可以有多个,每个 SubReactor 绑定一个独立线程,而每个网络连接绑定到唯一一个 SubReactor,这样同一个连接的 read,decode,process,encode,send 等操作都是在同一个线程中进行处理,避免上下文切换,也就解决了上面提到的第二种缺陷。
事件循环
从上面的三种 Reactor 模型我们可以抽象出 Reactor 工作的一般流程,分别为连接注册、事件轮询、事件分发、任务处理,如下图所示:

- 连接注册:连接 建立后,注册至 Reactor 线程中的 Selector 选择器。
- 事件轮询:轮询 Selector 选择器中已注册的所有 Channel 的 I/O 事件。
- 事件分发:为准备就绪的 I/O 事件分配相应的处理线程。
- 任务处理:Reactor 线程还需要负责任务队列中的非 I/O 任务的处理,比如连接状态检查,定时任务处理等。
Netty 的 EventLoop(事件循环)就可以看作是对 Reactor 模型的一种实现,所以它也会遵循 Reactor 的一般处理流程,我们以最常用的 NioEventLoop 为例,看一下它核心的 run 方法的源码:
protected void run() {
for (;;) {
try {
int strategy;
try {
strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());
switch (strategy) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
case SelectStrategy.SELECT:
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
curDeadlineNanos = NONE; // nothing on the calendar
}
nextWakeupNanos.set(curDeadlineNanos);
try {
if (!hasTasks()) {
// 轮询 I/O 事件
strategy = select(curDeadlineNanos);
}
} finally {
......
}
// fall through
default:
}
} catch (IOException e) {
......
}
cancelledKeys = 0;
final int ioRatio = this.ioRatio;
boolean ranTasks;
if (ioRatio == 100) {
try {
if (strategy > 0) {
processSelectedKeys();
}
} finally {
// Ensure we always run tasks.
ranTasks = runAllTasks();
}
} else if (strategy > 0) {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys();
} finally {
// Ensure we always run tasks.
final long ioTime = System.nanoTime() - ioStartTime;
ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
} else {
ranTasks = runAllTasks(0); // This will run the minimum number of tasks
}
......
} catch (CancelledKeyException e) {
} catch (Error e) {
throw e;
} catch (Throwable t) {
handleLoopException(t);
} finally {
}
}
}
上述源码的结构比较清晰,NioEventLoop 每次循环的处理流程都包含事件轮询 select、事件处理 processSelectedKeys、任务处理 runAllTasks 几个步骤,是典型的 Reactor 线程模型的运行机制。而且 Netty 提供了一个参数 ioRatio,可以调整 I/O 事件处理和任务处理的时间比例。
上一节说到的Reactor的三种线程模型,其实也都可以在创建ServerBootstrap时,通过配置的方式来指定具体使用哪种线程模型:
单线程
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup)
.channel(NioServerSocketChannel.class)
...
bossGroup将线程数指定为1,且不指定workerGroup(默认和bossGroup使用同一个),就是典型的单线程reactor。
多线程
EventLoopGroup bossGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup)
.channel(NioServerSocketChannel.class)
...
bossGroup将线程数使用默认值(根据CPU核数自动确定),Boss 和 Worker 仍然使用同一个EventLoopGroup。
主从多线程
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
...
Boss 是主 Reactor,Worker 是从 Reactor,它们分别使用不同的 EventLoopGroup,主 Reactor 负责新的网络连接 Channel 创建,然后把 Channel 注册到从 Reactor,这也是Netty推荐使用的方式。在此种模式下,netty的事件分派流程如下图:

从上图能够清晰的看出Netty的事件处理机制采用的是无锁串行化的设计思路,确保了同一个Channel的相关IO事件都会在同一个线程中进行处理,避免了上下文切换的开销。
最佳实践
结合上面解释的Netty EventLoop的相关设计原理,我们可以总结出一些在实际开发中使用EventLoop的最佳实践:
-
使用ServerBootstrap时,尽可能采用主从Reactor的模式,这样能够让bossGroup专注于连接的创建,能够承载更高的并发连接数。
-
由于一个Channel的ChannelHandler都运行在单线程中,因此不适合处理一些耗时较长的任务(比如数据库操作,接口调用之类的),如果确实有这样的需要,应该创建一个独立的业务线程池,并将任务提交到业务线程池进行异步处理,避免阻塞Channel所绑定的EventLoop。
-
如果只是耗时较短的操作,那么可以直接在ChannelHandler中处理,同样也是为了避免多线程的复杂性,同时减少线程上下文的切换。

欢迎关注我的公号—飞空之羽的技术手札,有深度的技术好文~