前沿科技速递🚀
在人工智能领域,语言模型已经成为推动自然语言处理(NLP)进步的关键力量。然而,随着模型规模的不断扩大,训练和部署这些大型语言模型(LLM)的资源成本也在急剧增加。为了应对这一挑战,全球AI领导者英伟达(NVIDIA)近日开源了其最新的小型语言模型 Nemotron-4-Minitron-4B-Base。这一新模型在保留强大性能的同时,大幅降低了计算资源的消耗,为AI开发者和研究人员带来了新的可能。
来源:传神社区
01 模型简介
Nemotron-4-Minitron-4B-Base 是英伟达开发的一款小型语言模型,拥有 40 亿参数(4B)。它基于 Meta 开源的 Llama-3.1 8B 模型,通过结构化剪枝和知识蒸馏技术进行了优化。这款模型不仅具备出色的语言理解能力,还大大减少了计算资源和训练数据的需求,成为开发者在资源有限的环境中进行高效AI应用的理想选择。Nemotron-4-Minitron-4B-Base 适用于翻译、情感分析、对话系统等多种自然语言处理任务。

02 核心技术
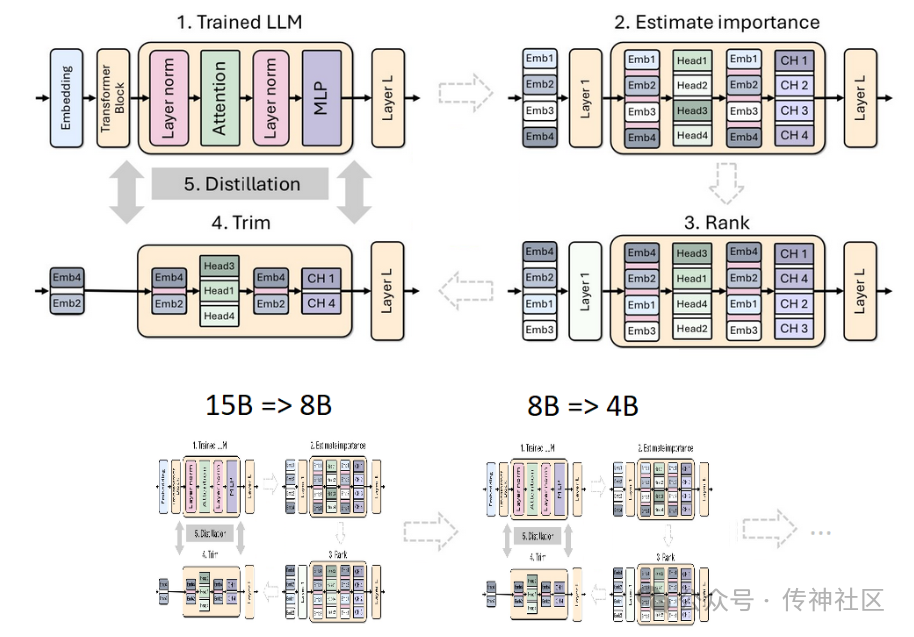
Nemotron-4-Minitron-4B-Base 模型的成功,离不开英伟达在模型压缩和优化领域的创新技术:结构化剪枝和知识蒸馏。两者的结合不仅显著减小了模型规模,还保留了卓越的性能,使得这款新模型在多个任务中表现出色。
-
结构化剪枝:剪枝技术的核心是去除模型中不必要的部分,以减小模型的复杂性和计算需求。传统的剪枝方法通常是随机地移除权重矩阵中的单个元素,而英伟达的结构化剪枝则更为智能。通过移除整个神经元、注意力头或卷积滤波器,英伟达在减小模型体积的同时,最大程度地保持了模型的结构完整性。这不仅降低了内存占用,还提升了训练速度,使模型在资源有限的环境中也能高效运行。
-
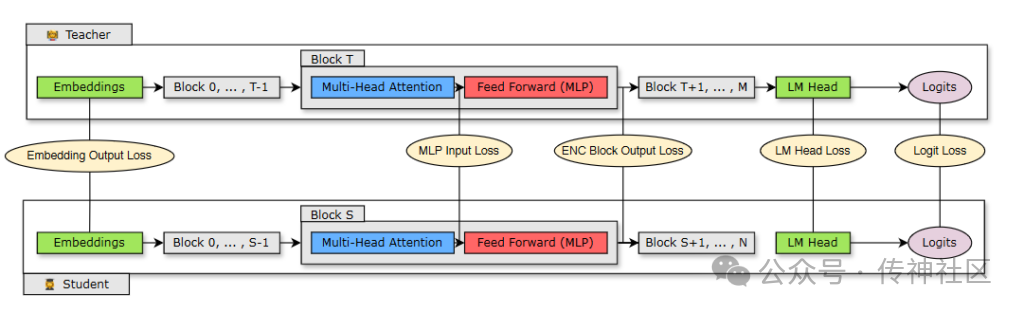
知识蒸馏:剪枝后的模型通常需要重新训练,以恢复其性能。知识蒸馏在这一过程中起到了关键作用。通过让“学生模型”模仿“教师模型”的行为,英伟达团队在极少量训练数据的情况下,显著提升了剪枝模型的表现。尤其是在模型深度大幅减少的情况下,结合使用 logits 层和中间状态的蒸馏策略,能够最大限度地恢复模型的预测准确性。
03 性能表现
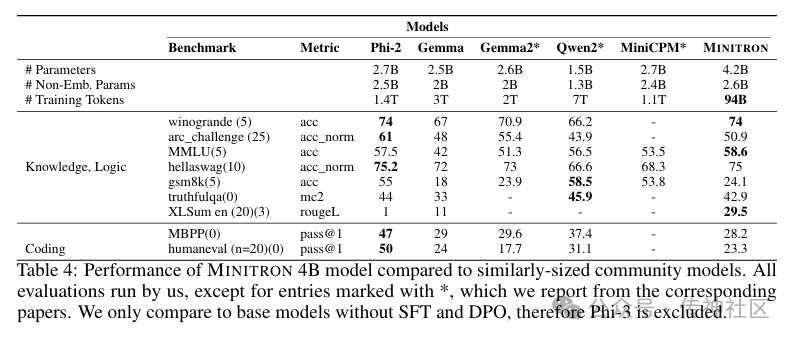
Nemotron-4-Minitron-4B 模型的表现令人瞩目。在英伟达的实验中,团队发现该模型不仅在多个基准测试中表现出色,还在实际应用中展现了卓越的性能:
-
训练数据减少:与传统模型相比,Nemotron-4-Minitron-4B 所需的训练数据量减少了 40 倍,仅需大约 1000 亿个 token。这意味着更多的开发者可以在有限的资源下训练出强大的语言模型。
-
算力成本节省:通过剪枝和蒸馏技术,英伟达成功地将模型的算力成本降低了 1.8 倍。这一成就为大规模部署 AI 技术铺平了道路。
-
性能媲美大型模型:尽管体积缩小,Nemotron-4-Minitron-4B 仍然在多个基准测试中与 Mistral 7B 和 Llama-3 8B 等知名模型相媲美,甚至在某些任务上表现更佳。
04 典型示例
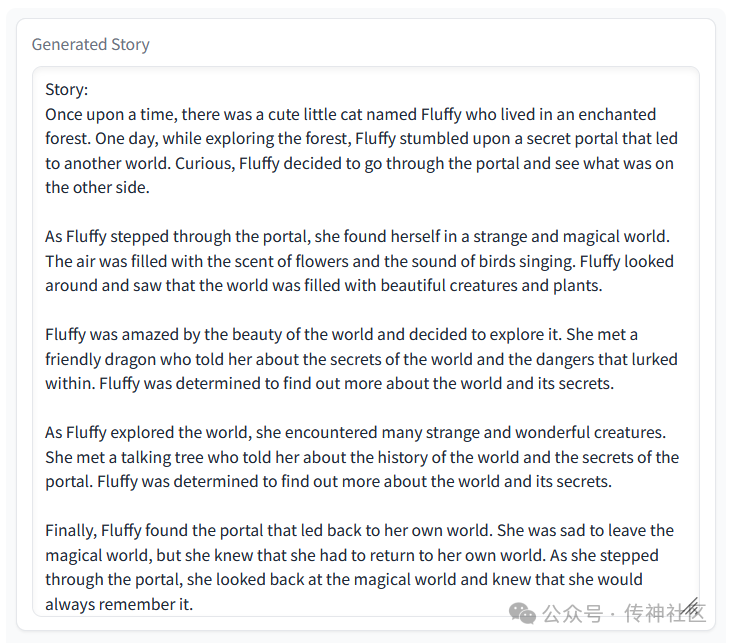
小编使用生成了一个小故事,我们一起来看看吧!
05 模型下载
传神社区:https://opencsg.com/models/nvidia/Nemotron-4-Minitron-4B-Base
blog:https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model/
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区