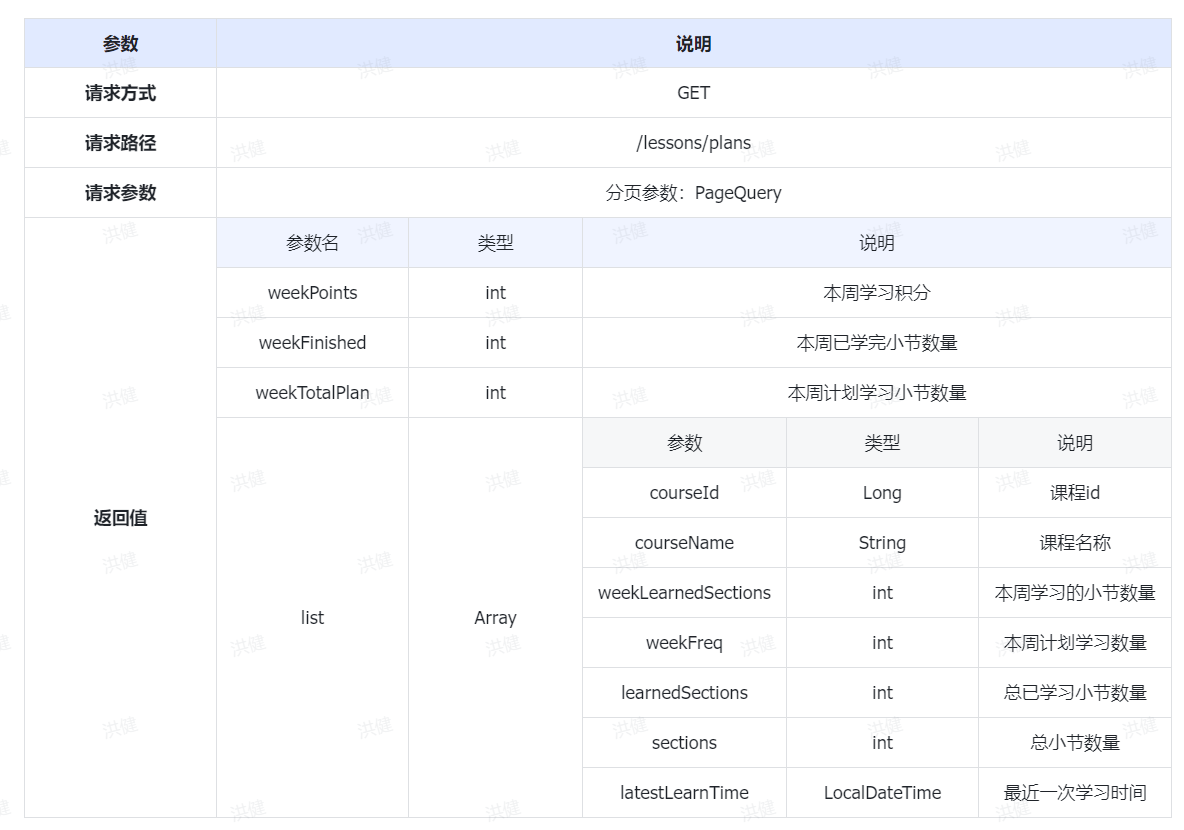
1、BIOS参数调优
| BIOS选项 | 设置值 |
| Power Policy | Performance |
| Stream Write Mode | Allocate share LLC |
| CPU Prefetching Configuration | Enabled |
| Custom Refresh Rate | 64ms |
| Die Interleaving | Disabled |
| NUMA | Enable |
| SSBS Support | Disabled |
2、benchmark参数调优
主要调整HPL.dat配置文件内容
HPLinpack benchmark input file
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any)
6 device out (6=stdout,7=stderr,file)
1 # of problems sizes (N)
234320 Ns
1 # of NBs
232 NBs
0 PMAP process mapping (0=Row-,1=Column-major)
3 # of process grids (P x Q)
4 8 16 Ps
32 16 8 Qs
16.0 threshold
1 # of panel fact
2 PFACTs (0=left, 1=Crout, 2=Right)
1 # of recursive stopping criterium
4 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
1 RFACTs (0=left, 1=Crout, 2=Right)
1 # of broadcast
1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
1 # of lookahead depth
1 DEPTHs (>=0)
2 SWAP (0=bin-exch,1=long,2=mix)
64 swapping threshold
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
1 Equilibration (0=no,1=yes)
8 memory alignment in double (> 0)
第5-6行:
矩阵规模的数量和大小,如果第5行大于1,第6行可以设置多个数值,代表不同的规模大小,测试时会遍历运行;矩阵规模越大使用的内存越多,如果超过服务器的内存总容量,就会使用到SWAP空间,性能会急剧下降影响测试结果,所以矩阵规模的大小建议使用系统内存总容量的80%-90%,换算公式为:N^2 * 8 = memory_size(Bytes) * 90%
也可以通过网站https://www.advancedclustering.com/act_kb/tune-hpl-dat-file/进行DAT文件自动设置,输入服务器的信息即可生成推荐的配置。
第7-8行:
求解矩阵过程中矩阵分块的大小。分块大小对性能有很大的影响,NB的选择和软硬件许多因素密切相关。NB值的选择主要是通过实际测试得出最优值,一般遵循以下规律:
- NB不能太大或太小,一般小于384。
- NB×8一定是缓存行的倍数。
- NB的大小和通信方式、矩阵规模、网络、处理器速度等有关系。一般通过单节点或单CPU测试可以得到几个较好的NB值,但当系统规模增加、问题规模变大,有些NB取值所得性能会下降。因此建议在小规模测试时选择3个性能不错的NB值,再通过大规模测试检验这些选择。
第10-12行:
P表示水平方向处理器个数,Q表示垂直方向处理器个数。P×Q表示二维处理器网格。P×Q=系统CPU数=进程数。一般情况下一个进程对应一个CPU,可以得到最佳性能。对于Intel和AMD等支持HT的处理器,关闭超线程可以提高HPL性能。P和Q的取值一般遵循以下规律:
- P≤Q,一般情况下P的取值小于Q,因为列向通信量(通信次数和通信数据量)要远大于横向通信。
- P建议选择2的幂。HPL中水平方向通信采用二元交换法(Binary Exchange),当水平方向处理器个数P为2的幂时性能最优。
3、参考示例
针对鲲鹏920s,32核处理器,内存64GB,可以修改HPL.dat文件如下