💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

推荐:Linux运维老纪的首页,持续学习,不断总结,共同进步,活到老学到老
导航剑指大厂系列:全面总结 运维核心技术:系统基础、数据库、网路技术、系统安全、自动化运维、容器技术、监控工具、脚本编程、云服务等。
常用运维工具系列:常用的运维开发工具, zabbix、nagios、docker、k8s、puppet、ansible等
数据库系列:详细总结了常用数据库 mysql、Redis、MongoDB、oracle 技术点,以及工作中遇到的 mysql 问题等
懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
nosql---Redis三主三从集群部
一、案例概述
1.1 单节点Redis服务器带来的问题
单点故障,服务不可用
无法处理大量的并发数据请求
数据丢书一大灾难
1.2 解决方法
搭建Redis集群
二、案例前置知识点
2.1 Redis集群介绍
Redis集群是一个提供在多个Redis间节点间共享数据的程序集(路由)
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误
Redis集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下可继续处理命令
2.2 Redis集群的优势
自动分割数据到不同的节点上
整个集群的部分节点失败或者不可达的情况下能够继续处理命令
2.3 Redis集群的实现方法
有客户端分片
在这里插入图片描述
代理分片
在这里插入图片描述
服务器端分片
在这里插入图片描述
Redis群集:去中心化模式——>区块链用的多
2.4 Redis-Cluster数据分片
Redis集群没有使用一致性hash,而是引入了哈希槽概念
Redis集群有16384个哈希槽
每个key通过CRC16校验后对16384取模来决定放置槽
集群的每个节点负责一部分哈希槽
以3个节点组成的集群为例
节点A包含0到5500号到哈希槽
节点B包含5501到11000号哈希槽
节点C包含11001到16384号哈希槽
支持添加或者删除节点
添加删除节点无需停止服务
例如
如果想新添加节点D,需要移动节点A、B、C中的部分槽到D上
如果想移除节点A,需要将A中的槽移到B和C节点上,再将没有任何槽的A节点从集群中移除
2.5 Redis-Cluster的主从复制模型
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会缺少5501-11000这个范围的槽而不可用
为每个节点添加一个从节点A1,B1,C1,整个集群便有三个master节点和三个slave节点组成,在节点B失败后,集群便会选举B1成为新的主节点继续服务
当B和B1都失败后,集群将不可用
三.redis集群部署
安装依赖包
yum -y install gcc gcc-c++
解压安装包并进入
make MALLOC=libc
make install PREFIX=/usr/local/redis
在安装目录下创建配置文件目录
mkdir /usr/local/redis/etc
cp /tools/redis-5.0.0/redis.conf /usr/local/redis/etc
为了后续redis的配置,可将/tools/redis-5.0.0/src/下的可执行脚本复制到/usr/local/redis/bin下面
配置 redis.conf
开机自启动
daemonize yes
允许远程连接
这里bind的意思是,允许从本地的那个接口来接入redis,假如是127.0.0.1,那当然就只有本地能接入了。但是假设服务器有三个ip,这里写入ip1的话,就表示可以通过这个ip来连接redis
因此,这里的意思并不是说开放哪个网段可以连接进来,而是允许外部通过本地的那个接口进来。假如在这里配置一个非本服务器的ip,那么很遗憾,redis连启动都启动不了,他会报错。
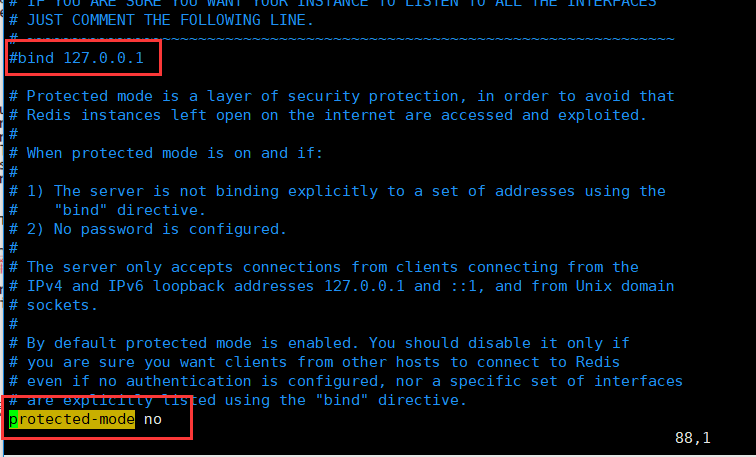
注释掉bind
#bind 127.0.0.1
关闭保护模式
protected-mode no
开发防火墙
firewall-cmd --add-port=6379/tcp --permanent
firewall-cmd --reload
配置环境变量
vim /etc/profile
PATH=$PATH:/usr/local/redis/bin
export PATH
启动redis
redis-server /usr/local/redis/etc/redis.conf
测试连接
redis-cli -h 127.0.0.1 -p 6379 ping
进入redis
redis-cli -h 127.0.0.1 -p 6379
停止redis
redis-cli -h 127.0.0.1 -p 6379 shutdown 又或者你可暴力杀掉
redis集群部署
环境:
master1:172.16.1.31:8000
master2:172.16.1.32:8000
master3:172.16.1.33:8000
slave1:172.16.1.34:8000
slave2:172.16.1.35:8000
slave3:172.16.1.36:8000
官方推荐redis集群至少拥有6个节点 3主3从
集群建立后,往集群插入数据的时候,会经过插槽运算去给数据分配一个插槽(slots),其插槽可以是集群上插槽的任意一个,也就是说,可能是在三台主redis的任意一台上的一个插槽。
备份redis会备份好主redis上的数据,当主redis故障或者down机的时候,备redis就是将自身状态切换到主redis。
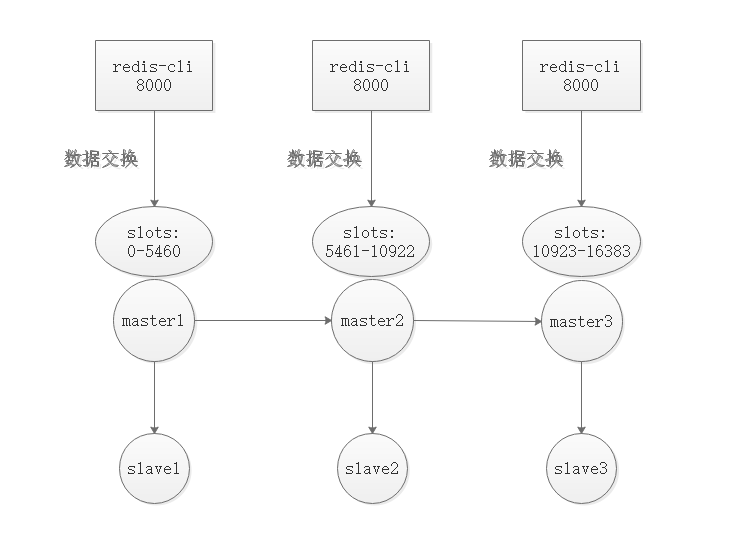
配置redis(所有节点)
vim /usr/local/redis/etc/redis.conf
port 8000 #启动端口
pidfile /var/run/redis_8000.pid #pid文件
dir /usr/local/redis/etc/ #生产文件默认路径
cluster-enabled yes #开启集群
cluster-config-file nodes_8000.conf #集群节点配置文件
appendonly yes #开启AOF持久化
requirepass tqw961110 #设置密码
masterauth tqw961110 #这个配置需要在从服务器上加上,不然当主redis坏掉的时候,slave不能自动切换成master
旧版本会使用redis-trib.rb这个脚本,但是新版本将该脚本的命令全部移动到redis-cli下面了
格式为redis-cli --cluster 加上下图的参数
redis-cli --cluster help 可以看到--cluster参数的所有用法
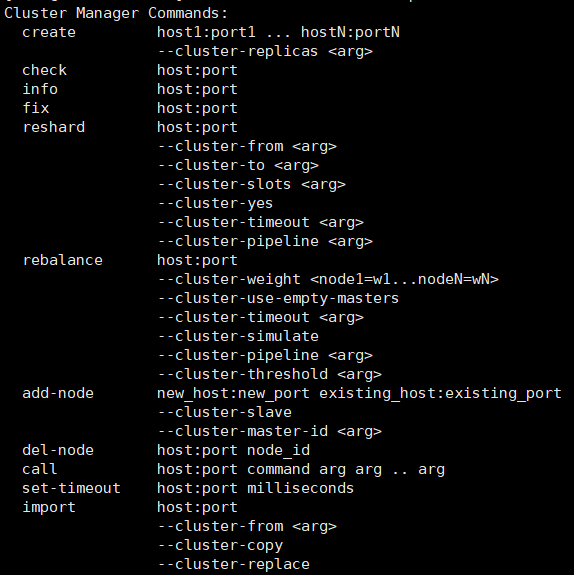
--cluster-replicas 1 的意思是集群中一个主对于一个从
./redis-cli --cluster create 172.16.1.31:8000 172.16.1.32:8000 172.16.1.33:8000 172.16.1.34:8000 172.16.1.35:8000 172.16.1.36:8000 --cluster-replicas 1 -a tqw961110
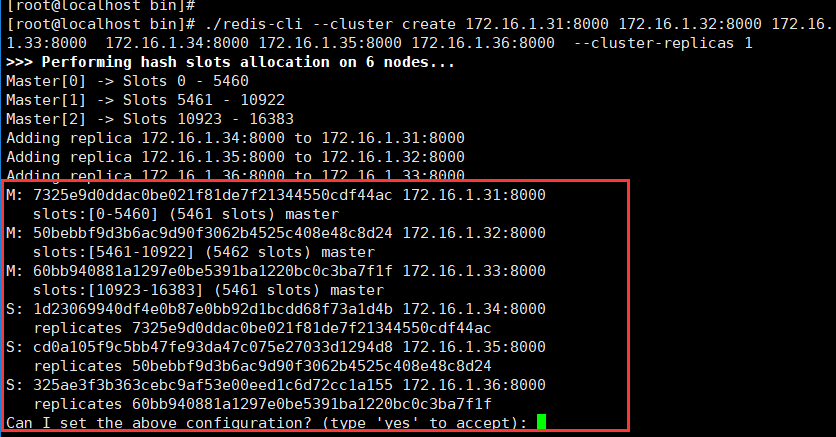
执行命令后如果出现 Waiting for the cluster to join 并一直处于等待状态没有反应。
redis集群不仅需要开通redis客户端连接的端口,而且需要开通集群总线端口
集群总线端口为redis客户端连接的端口 + 10000
如redis端口为8000
则集群总线端口为18000
故,所有服务器的点需要开通redis的客户端连接端口和集群总线端口
firewall-cmd --add-port=8000/tcp --permanent
firewall-cmd --add-port=18000/tcp --permanent
firewall-cmd --reload
查看集群状态
redis-cli -c -p 8000 -a tqw961110 cluster nodes
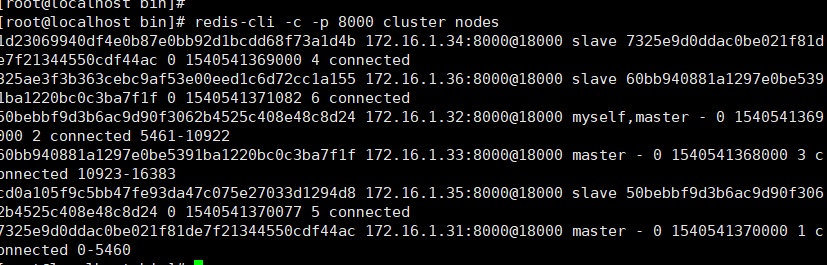
测试
建立集群后,必须通过集群模式连接redis,也就是加入-c参数,不然后报错。
在31上插入数据
redis-cli -c -h 172.16.1.31 -p 8000 -a tqw961110
>set name1 aaaa

可以看到数据插入到12933这个slots里面,对应的主redis是33节点的redis
在32上插入数据
redis-cli -c -h 172.16.1.32 -p 8000 -a tqw961110
>set name2 bbbb

可以看到数据插入到742这个slots里面,对应的主redis是31节点的redis
由此可见,证明了上文所述的,插入数据时候,会根据插槽算法去分配数据究竟分配在哪个slots里面。
在31节点上查看数据
redis-cli -c -h 172.16.1.31 -p 8000
>get name1
>get name2
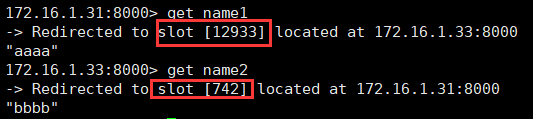
可以看到,31节点上的redis可以查询到刚才在32上插入的数据,证明集群的建立是成功的。
而查询数据是根据对应的slots去匹配的。
增加集群节点
增加主节点
redis-cli --cluster add-node 172.16.1.37:8000 172.16.1.31:8000 -a tqw961110 (增加节点ip:端口 已有节点ip:端口)
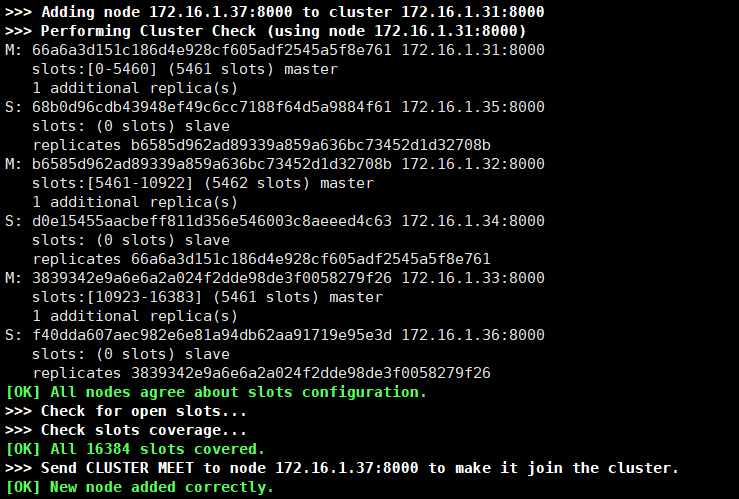
系统提示节点已经添加成功。
查看一下集群的状态。
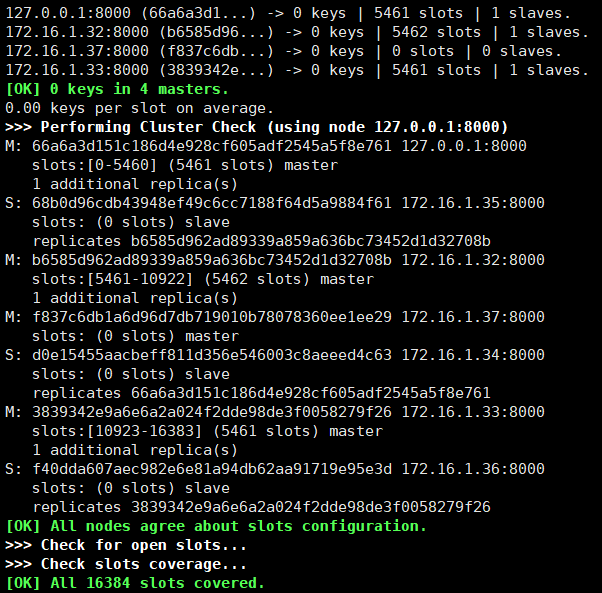
可以发现37节点目前还没有分配slots,因此他现在还不能插入数据。
因此需要从别的节点上迁移数据过来。
我们从33节点上将数据迁移过来
redis-cli --cluster reshard 127.0.0.1:8000 --cluster-from 3839342e9a6e6a2a024f2dde98de3f0058279f26 -a tqw961110

他会问需要迁移多少个,我们选择2000个

他会询问这些数据需要那个节点来接收,这里我们输入37节点的id
然后会询问是否按照原本的计划迁移数据,这里我们选择yes即可。

短暂的等待后,数据迁移完毕,这时查看集群的状态。
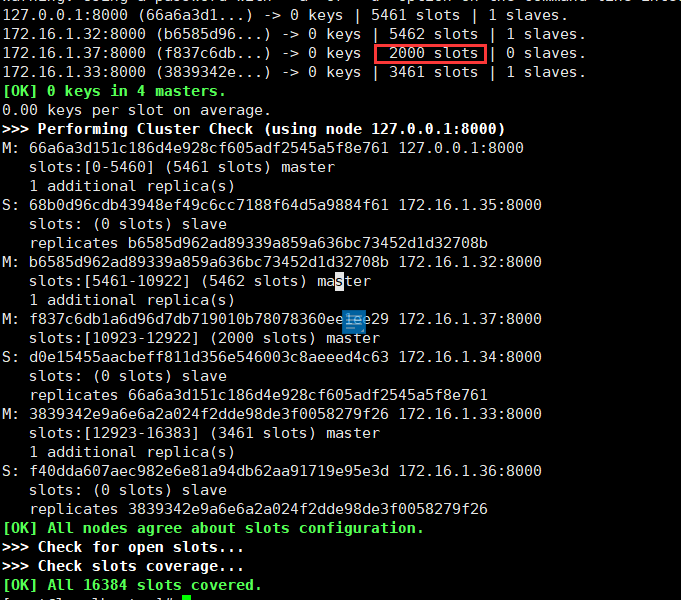
可以看到37节点上已经有2000个slots,这个时候就可以插入数据。
增加从节点
在增加完主节点后,我们还需要为其增加一个从节点,以实现高可用。
redis-cli --cluster add-node 172.16.1.38:8000 172.16.1.37:8000 --cluster-slave --cluster-master-id f837c6db1a6d96d7db719010b78078360ee1ee29 -a tqw961110 (知道添加的节点为从节点,并且知道其master的id。)
再查看一下集群的状态
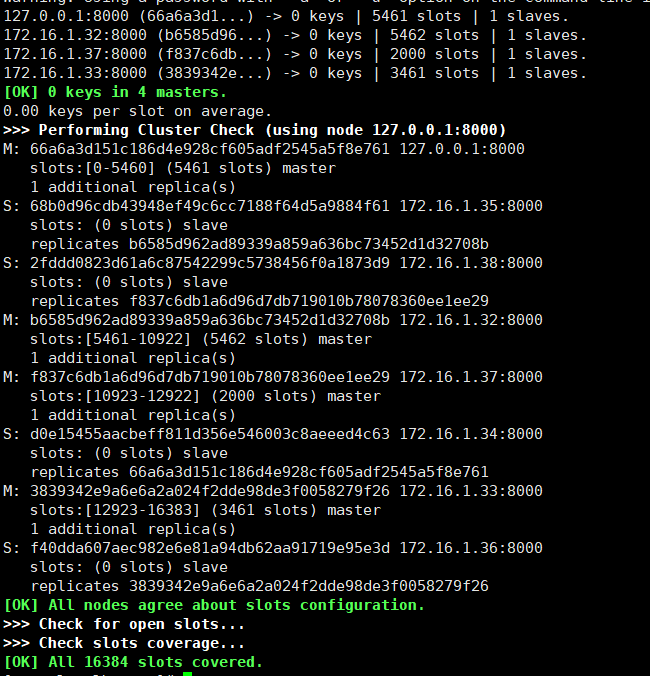
可以看到,37、38两个节点已经添加进集群中,并处于主从同步状态。
删除集群节点
redis-cli --cluster del-node ip:端口 node_id -a 密码
对于从节点,可以直接用上述命令删除,但是对于主节点,必须要先把主节点上的数据迁移到别的节点上,不然会报下列错误

因此,我们可以按下列步骤把数据迁移到其他节点
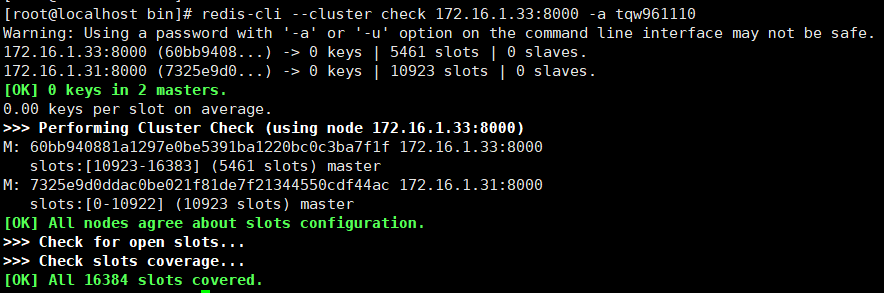
查看主节点当前状态,查看其对应的id和分配到的slots的数量
redis-cli --cluster check 172.16.1.33:8000 -a tqw961110
迁移数据
redis-cli --cluster reshard 127.0.0.1:8000 --cluster-from 删除数据的节点的id -a tqw961110

这里问我们要迁移多少个slot,我们上面看到当前节点一共有5461个slots,因此这里我们输入5461。

然后系统会问我们获取接受这些slots的节点id,这里我们选择本地节点的id。
![]()
这里选择yes
当slots数量比较多的时候,这里可能需要等一两分钟。
redis-cli --cluster check 172.16.1.33:8000 -a tqw961110
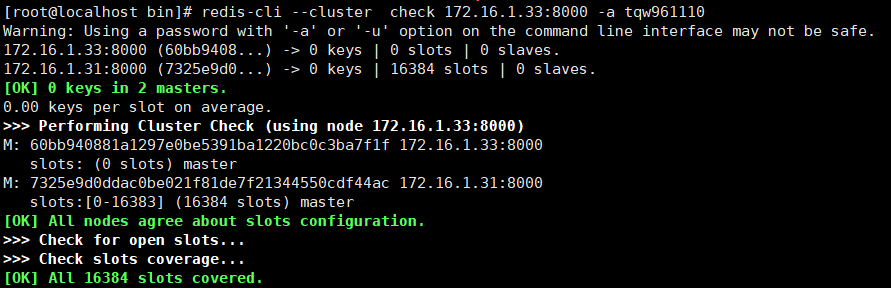
可以看到,33节点上的slots数量已经变成0
这时候就可以删除节点了
redis-cli --cluster del-node 172.16.1.33:8000 60bb940881a1297e0be5391ba1220bc0c3ba7f1f -a tqw961110

查看集群中是否还有该节点

已经只剩下本地的节点了
这个时候还没完,因为集群建立的时候会在本地新建.aof,.rdb,还有集群对应的.conf文件。
先把redis停掉,再把这三个文件删除,然后重启,这样才算完全清除了集群配置。

故障测试
测试一下一台master故障的down掉的时候,他对应的从服务器是否会自动切换到master的角色。
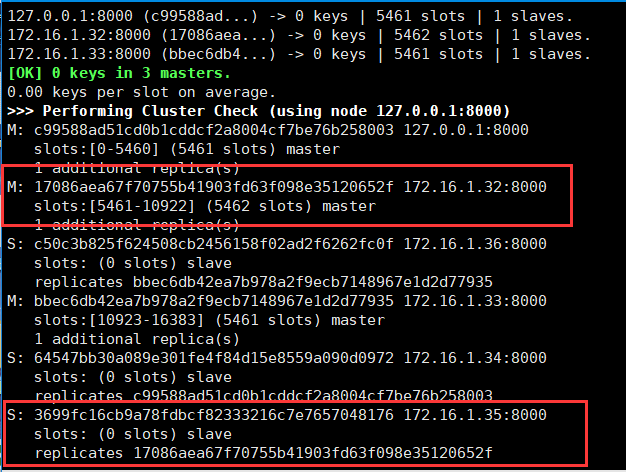
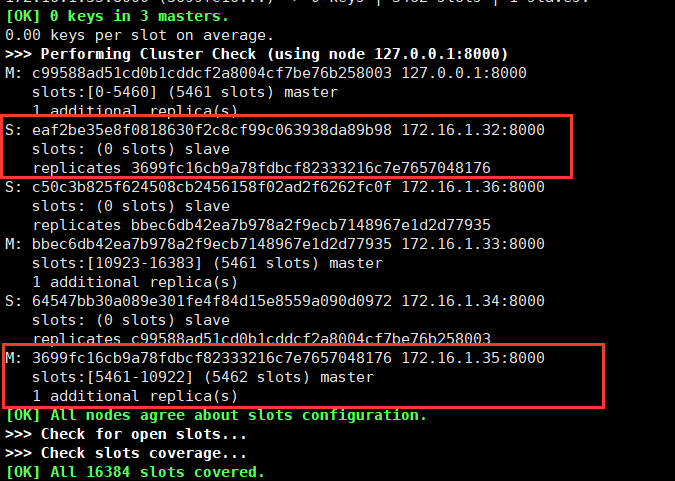
上图32节点为主redis,35为其对应的slave,先把32的redis停掉。
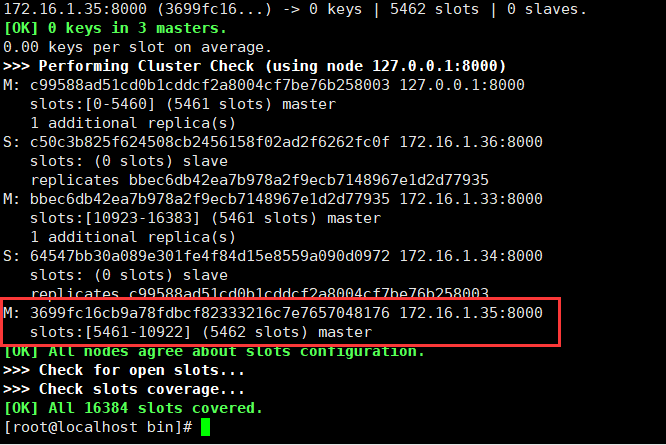

一定的时间后,可以看到32节点已经退出集群,并且经过·选举,35成为了新的master。
这个时候我们可以对32服务器的redis进行抢救
抢救完成后,先把它的集群配置文件备份然后删掉。
这是由于业务的数据已经增加了,所以32的redis需要作为slave从新加进集群里面,这样就可以同步到主redis上的业务数据。

重启redis,然后执行如下命令(新的节点ip:端口 已有的节点ip:端口 --cluster-slave --cluster-master-id 主redis的id )
redis-cli --cluster add-node 172.16.1.32:8000 172.16.1.35:8000 --cluster-slave --cluster-master-id 3699fc16cb9a78fdbcf82333216c7e7657048176 -a tqw961110
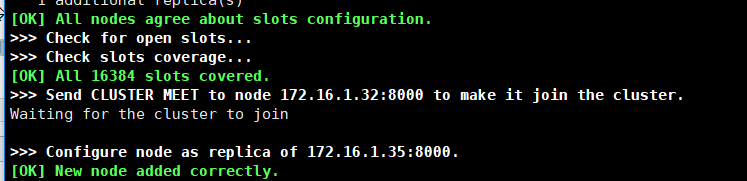
看到上述提示,则证明节点添加成功。
再查看一下集群状态