【写在前面】 飞腾开发者平台是基于飞腾自身强大的技术基础和开放能力,聚合行业内优秀资源而打造的。该平台覆盖了操作系统、算法、数据库、安全、平台工具、虚拟化、存储、网络、固件等多个前沿技术领域,包含了应用使能套件、软件仓库、软件支持、软件适配认证四大板块,旨在共享尖端技术,为开发者提供一个涵盖多领域的开发平台和工具套件。 点击这里开始你的技术升级之旅吧
本文分享至飞腾开发者平台《飞腾平台Hadoop-3.2.2安装配置手册》
1 介绍
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。HDFS解决了超大数据存储问题。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
Hadoop的优点:
1)支持超大文件。HDFS存储的文件可以支持TB和PB级别的数据。
2)检测和快速应对硬件故障。数据备份机制,NameNode通过心跳机制来检测DataNode是否还存在。
3)高扩展性。可建构在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,NameNode也可以感知,将数据分发和备份到相应的节点上。
4)成熟的生态圈。借助开源的力量,围绕Hadoop衍生的一些小工具。
Hadoop的缺点:
1)不能做到低延迟。高数据吞吐量做了优化,牺牲了获取数据的延迟。
2)不适合大量的小文件存储。
3)文件修改效率低。HDFS适合一次写入,多次读取的场景。
2 环境要求
2.1 硬件要求
硬件要求如下表所示。
| 项目 | 说明 |
|---|---|
| CPU | FT-2000+/64服务器 |
| 网络 | 无要求 |
| 存储 | 无要求 |
| 内存 | 无要求 |
2.2 操作系统要求
操作系统要求如下表所示。
| 项目 | 说明 |
|---|---|
| CentOS | 8 |
| Kernel | 4.18.0-193.el8.aarch64 |
2.3 软件环境要求
软件环境要求如下表所示。
| 项目 | 说明 |
|---|---|
| JDK | 11.0.11 |
| Maven | 3.3.9 |
| Protpbuf | 2.6.1 |
3 安装与配置步骤
3.1 基本环境
在部署Hadoop前确保主机上有对应的JAVA环境,本文档使用的JDK版本是11.0.11
3.2 下载Hadoop压缩包
1)下载Hadoop安装包:
a)Index of /dist/hadoop/core/hadoop-3.2.2(apache.org) 官网
b)Index of /apache/hadoop/common/hadoop-3.2.2(tsinghua.edu.cn) 清华镜像网站
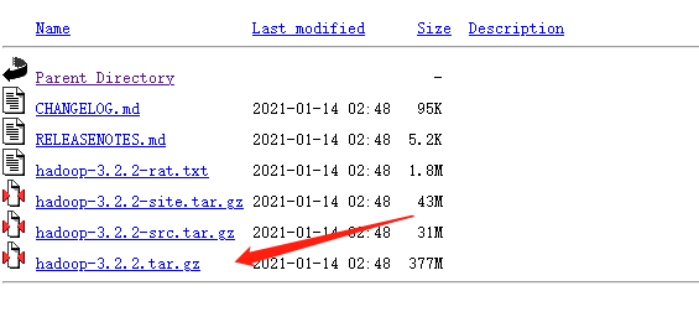
注*:在下载Hadoop安装包时,要选择编译好的,可以直接使用的压缩包,如下图所示:
2)解压压缩包
>>tar -zxvf hadoop-3.2.2.tar.gz3)查看解压后的文件,并查看Hadoop版本判断是否可用
![]()
>>bin/hadoop version3.3 将Hadoop添加至环境变量
编辑位于/etc目录下的profile文件
>> vim /etc/profile将以下代码追加至文件尾部
export HADOOP_HOME=/GSH/Hadoop-Hbase/hadoop-3.2.2
export PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$PATH保存后,执行命令:
>> source /etc/profile3.4 在Hadoop中配置JAVA_HOME
Hadoop相关的配置文档都存储在解压目录的etc/hadoop文件夹下
1)编辑位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop的hadoop-env.sh
>> vim hadoop-env.sh配置jdk路径:
export JAVA_HOME=/opt/jdk-11.0.11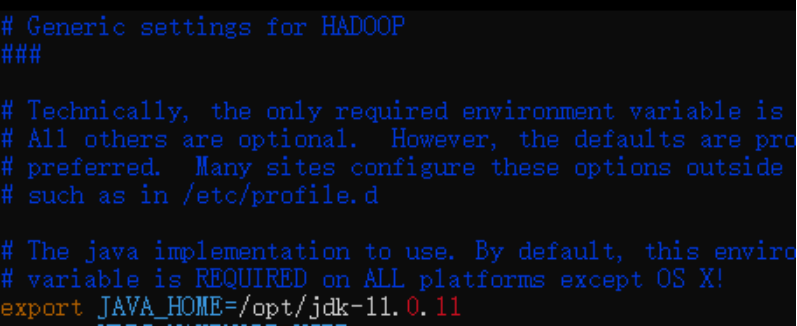
2)编辑位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/libexec的hadoop-config.sh
>> vim hadoop-config.sh配置jdk路径:
export JAVA_HOME=/opt/jdk-11.0.11
3.5 修改配置文件
3.5.1 core-site.xml
Hadoop的核心组件文件是core-site.xml,位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop目录下,用vim编辑core-site.xml:
>> vim core-site.xml将以下代码添加至<configuration> 和 </configuration>之间:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/GSH/Hadoop-Hbase/hadoop-3.2.2/tmp</value>
<description>用于存储数据的目录</description>
<description>tmp为目录名 可根据个人习惯命名</description>
</property>3.5.2 hdfs-site.xml
Hadoop的文件系统配置文件是hdfs-site.xml,位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop目录下,用vim编辑hdfs-site.xml:
>> vim hdfs-site.xml将以下代码添加至<configuration> 和 </configuration>之间:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/GSH/Hadoop-Hbase/hadoop-3.2.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.dir</name>
<value>/root/GSH/Hadoop-Hbase/hadoop-3.2.2/dfs/data</value>
<description>网上的一些教程中并没有配置namenode和datanode</description>
<description>建议添加,防止之后出错</description>
</property>Hadoop 的运行方式是由配置文件决定的(运行Hadoop时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除core-site.xml中的配置项。
伪分布式虽然只需要配置fs.defaultFS和dfs.replication就可以运行,不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为/tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行format才行。
3.5.3 yarn-site.xml
Yarn的站点配置文件是yarn-site.xml,位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop目录下,用vim编辑yarn-site.xml:
>> vim yarn-site.xml将以下代码添加至<configuration> 和 </configuration>之间:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:18088</value>
</property>注*:上述代码中多次出现的“hadoop01”为主机名,在本文档的后续部分介绍。
3.5.4 MapReduce
MapReduce是计算机框架文件,位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop目录下,用vim编辑mapred-site.xml文件:
>> vim mapred-site.xml在<configuration>和</configuration>之间加入代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>对于相对较旧的hadoop版本,在hadoop-x.x.x/etc/hadoop子目录下可能已经有一个mapred-site.xml.template文件,需要将其复制并改名:
>> cp mapred-site.xml.template mapred-site.xml3.6 更改主机hosts文件
hosts文件一般位于/etc目录下(此etc并不是解压hadoop安装包后出现的etc目录)。使用vim编辑hosts文件:
>> vim hosts将ip主机名添加进去,如:
172.16.32.201 hadoop01名称可根据习惯修改,为了方便之后创建多集群,可修改成master,slave01等等。
3.7 格式化文件系统
格式化namenode,在/root/GSH/Hadoop-Hbase/hadoop-3.2.2下操作,执行命令:
>> bin/hdfs namenode -format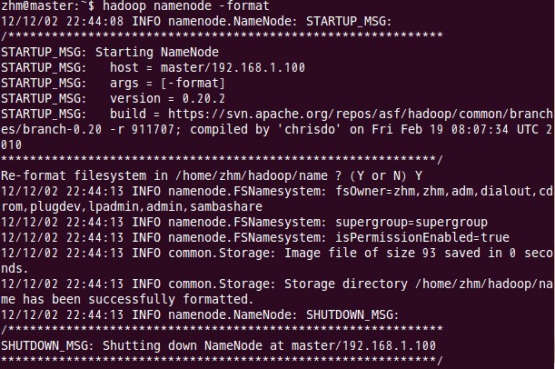
只要出现“Storage directory has been successfully formatted”就说明初始化成功了。
4 启动Hadoop
为了尽可能的避免报错,回到hadoop-3.2.2目录下启动hadoop:
>> start-all .sh对于版本相对旧一点的hadoop版本,执行命令后可能会成功启动,但是对于3.2.2版本hadoop来说,执行命令后会显示如图3.6所示的信息:
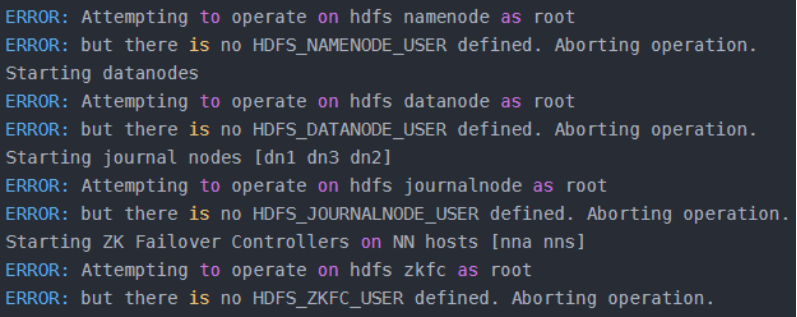
通过查询hadoop-env.sh文件描述可知,这是为了防止发生意外,仅(部分)锁定shell命令以仅允许某些用户执行某些子命令。
解决方案:编辑位于/root/GSH/Hadoop-Hbase/hadoop-3.2.2/etc/hadoop目录下的hadoop-env.sh文件
>> vim hadoop-env.sh将以下代码添加到文档中:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root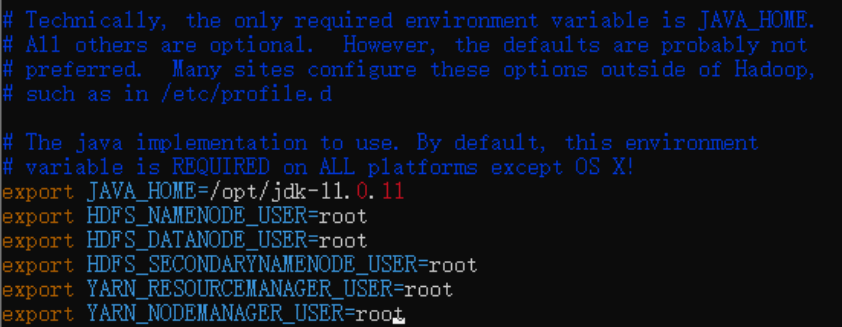
保存退出后,执行命令:
>> source hadoop-env.sh重新尝试启动hadoop
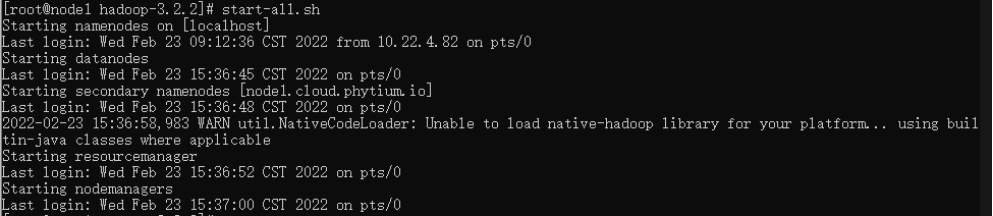
>> start-all.sh4.1 查看Hadoop是否启动成功
执行启动命令后,出现如图3.7所示输出信息说明启动成功:
也可以使用jps命令查看是否启动成功:
>> jps出现NameNode, NodeManager等进程说明启动成功,如下图所示
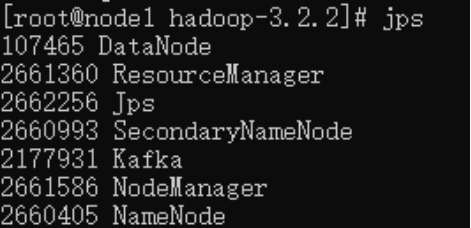
4.2 关闭Hadoop
>> stop-all.sh推荐阅读
- 基于飞腾平台的Hbase的安装配置
- 基于飞腾平台的Kafka移植与安装
欢迎广大开发者来飞腾开发者平台获取更多前沿技术文档及资料
如开发者在使用飞腾产品有任何问题可通过在线工单联系我们
版权所有。飞腾信息技术有限公司 2023。保留所有权利。
未经本公司同意,任何单位、公司或个人不得擅自复制,翻译,摘抄本文档内容的部分或全部,不得以任何方式或途径进行传播和宣传。
商标声明
Phytium和其他飞腾商标均为飞腾信息技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
本文档的内容视为飞腾的保密信息,您应当严格遵守保密任务;未经飞腾事先书面同意,您不得向任何第三方披露本文档内容或提供给任何第三方使用。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,飞腾在现有技术的基础上尽最大努力提供相应的介绍及操作指引,但飞腾在此明确声明对本文档内容的准确性、完整性、适用性、可靠性的等不作任何明示或暗示的保证。
本文档中所有内容,包括但不限于图片、架构设计、页面布局、文字描述,均由飞腾和/或其关联公司依法拥有其知识产权,包括但不限于商标权、专利权、著作权等。非经飞腾和/或其关联公司书面同意,任何人不得擅自使用、修改,复制上述内容。


















