( 于景鑫 国家农业信息化工程技术研究中心 )农业大数据是农业智能化的基石,其共享与开放是发掘数据价值、驱动农业变革的关键。然而,数据隐私与安全问题如同数据共享之路上的一道坎,牵制着农业大数据的流动与融合。联邦学习作为一种颠覆性的分布式机器学习范式,犹如一把打开数据共享之锁的钥匙,为构建农业大数据共享的隐私保护堡垒提供了新的思路和方法。本文将从联邦学习的原理入手,剖析其在农业大数据共享中的关键技术、应用实践和发展展望,为破解数据共享困局、重塑农业数字生态提供新的视角。
图片来源:https://www.geeksforgeeks.org/collaborative-learning-federated-learning/
一、数据共享之困:农业大数据面临的隐私挑战
农业大数据蕴藏着丰富的智慧和价值,其覆盖了农业生产、经营、管理、服务等各个环节,涉及气象、环境、土壤、作物、病虫害、市场等多个维度。通过数据汇聚和分析,可以洞见农业生产规律、优化资源配置决策、创新农业服务模式,为农业插上腾飞的翅膀。然而,农业大数据呈现出分散多元的特点,数据掌握在政府、企业、农户、第三方等不同主体手中,形成了一个个"数据孤岛"。打通数据壁垒,实现数据共享,是发掘农业大数据价值的必由之路。
但现实是,数据共享之路荆棘丛生。一个核心问题是,农业数据中往往包含了各主体的隐私信息,如农户的个人信息、企业的商业机密等。一旦这些隐私数据在共享过程中发生泄露,将给相关主体带来难以估量的损失,甚至引发法律和信任危机。而传统的数据脱敏技术,如数据加密、匿名化等,虽然在一定程度上保护了隐私,但也削弱了数据的价值,限制了数据分析的空间。如何在保护隐私的同时,实现数据共享和价值挖掘,成为一个世界性难题。
图片来源:https://www.sciencedirect.com/science/article/pii/S0743731522000570
二、联邦学习:数据共享的隐私保护利器
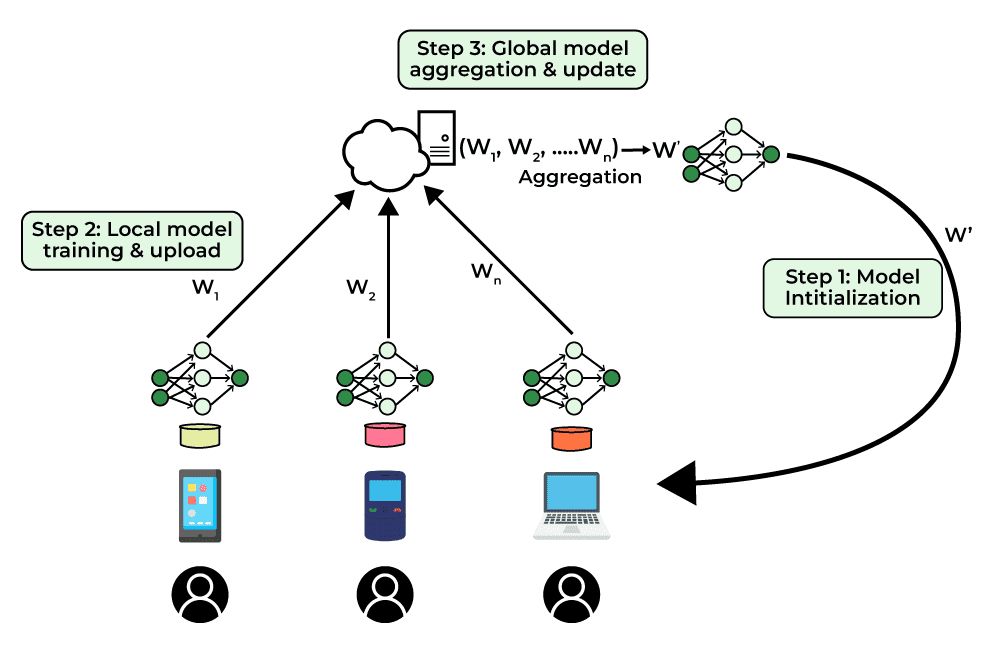
联邦学习(Federated Learning)为破解数据共享困局提供了一种全新思路。它是由谷歌提出的一种分布式机器学习框架,允许多个参与方在不直接共享原始数据的情况下,协同训练一个机器学习模型。其基本原理是,各参与方在本地利用自己的数据训练局部模型,然后通过安全的通信协议,如加密通信、差分隐私等,将局部模型的参数或梯度上传到中心服务器进行聚合,得到全局模型,再将全局模型分发给各参与方,进行新一轮的本地训练。如此迭代,直至全局模型收敛。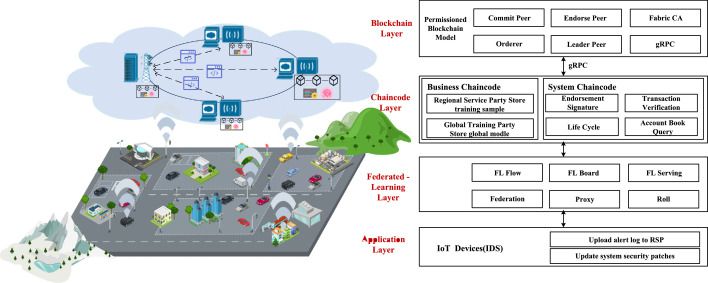
图片来源:https://www.sciencedirect.com/science/article/pii/S0167404820303060
联邦学习巧妙地实现了"数据不动,模型动",在保护数据隐私的同时,充分利用了多方数据的价值。其优势主要体现在:
1. 隐私保护:联邦学习通过加密通信、差分隐私等技术,确保参与方的原始数据不会被其他方直接获取,有效保护了数据隐私。
2. 数据安全:数据始终存储在参与方本地,不必上传到中心服务器,避免了数据集中存储带来的安全风险。
3. 数据异构:联邦学习允许参与方使用不同格式、不同分布的数据进行训练,克服了数据孤岛问题,实现了异构数据的融合。
4. 模型性能:通过多方协作训练,联邦学习可以利用更多的数据和算力,提高模型的泛化能力和鲁棒性。
5. 激励机制:联邦学习尊重数据所有权,参与方对自己的数据拥有完全控制权,有利于调动各方参与数据共享的积极性。
三、联邦学习在农业大数据共享中的关键技术
联邦学习要在农业大数据共享中发挥隐私保护作用,需要一系列关键技术的支撑。
1. 梯度聚合算法:梯度聚合是联邦学习的核心操作,其目标是将各参与方上传的局部梯度聚合为全局梯度,用于更新全局模型。经典的梯度聚合算法包括FedAvg、FedProx等。FedAvg采用简单平均的方式对局部梯度进行聚合,而FedProx在此基础上引入了正则化项,增强了全局模型的鲁棒性。近年来,一些改进算法如FedNova、FedOpt等被提出,通过自适应学习率、动量梯度等机制,加速了全局模型的收敛。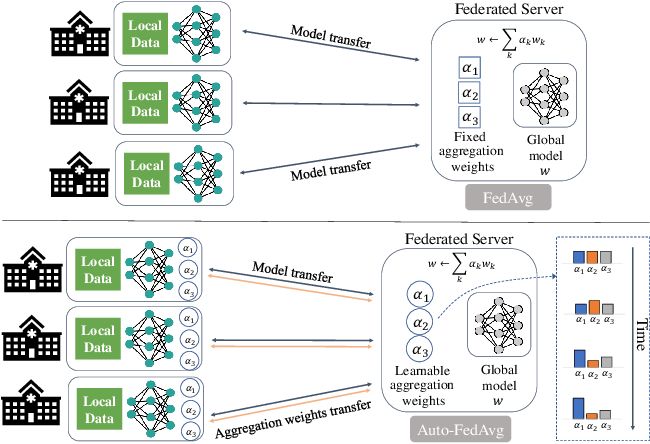
图片来源:Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
2. 差分隐私算法:差分隐私是一种严格的隐私保护框架,其核心思想是在数据发布或分析过程中引入随机噪声,使得攻击者无法从结果中推断出个体的隐私信息。在联邦学习中,可以对局部梯度应用差分隐私算法,如DP-SGD、PATE等,防止梯度反推攻击。DP-SGD通过在局部梯度中添加高斯噪声,实现了(ε,δ)-差分隐私。而PATE利用教师-学生模型,在教师模型中引入高斯噪声,学生模型通过标签投票机制学习隐私保护后的知识。
3. 同态加密:同态加密是一种允许在密文上进行计算的加密技术,即对密文的计算结果解密后,与对应明文的计算结果相同。在联邦学习中,可以利用同态加密实现梯度的加密聚合,避免中心服务器窥探局部梯度。常用的同态加密算法包括Paillier、BFV等。但同态加密通常计算复杂度高,如何设计高效的同态加密算法是一个挑战。
4. 区块链激励:联邦学习需要多方积极参与,而合理的激励机制可以调动各方的积极性。区块链技术为构建去中心化的激励机制提供了新的思路。可以将参与方的贡献度(如数据量、模型质量等)记录在区块链上,并以此发放代币奖励。区块链的不可篡改性和智能合约机制,确保了激励过程的公平和透明。联邦学习与区块链的结合,将催生出新的数据经济生态。
5. 安全多方计算:安全多方计算(MPC)允许多方在不泄露隐私数据的前提下,共同计算某个函数。在联邦学习中,可以利用MPC实现梯度聚合、模型评估等敏感计算,防止中间结果泄露。秘密共享、不经意传输等是常用的MPC协议。近年来,一些高效的MPC协议如ABY3、SPDZ等被提出,大大提高了MPC的实用性。
四、联邦学习驱动农业大数据共享的实践探索
联邦学习(FL)正在成为农业大数据共享领域的一种变革性方法,旨在应对与数据隐私、安全和所有权相关的关键挑战。这种去中心化的机器学习模式允许多个利益相关者协作训练模型,而无需共享原始数据,从而保护隐私并遵守监管要求。
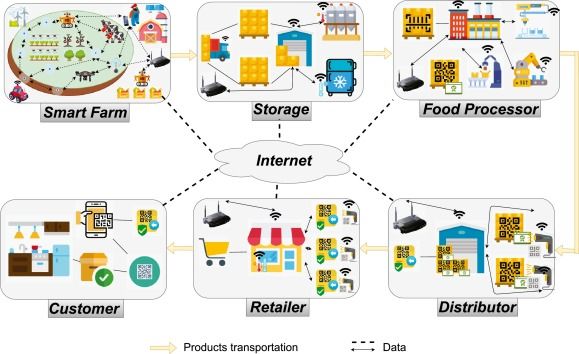
在农业大数据背景下,FL已应用于各个领域,包括食品供应链管理和作物病害检测。例如,Gavai等人演示了使用FL来打击复杂食品供应链中的食品欺诈。通过采用贝叶斯网络模型,他们整合了来自供应链中不同参与者的数据,而数据不会离开所有者的数据库,从而维护了数据隐私和安全,同时增强了有关食品欺诈控制的决策能力 [1]。 同样,FL 已在精准农业中有效用于农作物疾病检测。Aggarwal 等人应用联邦迁移学习进行稻叶病分类,在确保多个客户数据隐私的同时,实现了高准确性。他们的方法通过在IID和非IID数据集中保持高精度和低损耗,证明了FL相对于传统集中式模型的优势,尤其是在资源受限的环境中 [3]。Kabala等人通过图像分析进一步探讨了FL在作物病害分类方面的潜力,强调了FL在克服与集中数据收集相关的挑战(例如隐私问题和传输成本)方面的潜力。他们的研究发现,像ResNet50这样的模型在联邦学习场景中表现最佳,这突显了模型选择在FL应用程序中的重要性[8]。
FL 在农业中的应用并非没有挑战。杨等人讨论了由于不同的监管要求和数据共享机构之间的信任问题而实施FL的复杂性。他们强调需要强大的合规性、安全性和信任机制,以促进FL的有效部署 [4]。Wilgenbusch等人强调了农业大数据中更广泛的挑战,例如数据所有权和隐私,佛罗里达州有可能通过实现安全高效的数据共享和分析来应对这些挑战 [6]。 此外,Vimalajeewa等人提出了智能农业的联合FL模型,专门用于牛奶质量分析,这表明FL可以在提供及时分析的同时优化资源消耗。这种方法突显了佛罗里达州利用分布式数据分析提高农业实践效率和可持续性的潜力 [7]。
五、农业大数据共享的未来:联邦学习+
联邦学习为农业大数据共享开辟了一条可信的道路,但其潜力远未被充分发掘。未来,联邦学习将与其他前沿技术进行更深度的融合,激发出更大的想象空间。
1. 联邦学习+区块链:利用区块链构建农业数据共享的激励和信任机制,用联邦学习确保数据隐私,二者协同构建一个安全、可信、可持续的农业数据经济生态。
2. 联邦学习+边缘计算:将联邦学习的执行环境从云端延伸到边缘端,利用物联网设备就地进行本地训练和推理,实现农业数据智能处理的实时响应。
3. 联邦学习+知识图谱:利用知识图谱对农业领域知识进行结构化表示,用联邦学习实现跨数据源、跨领域的知识融合,构建一个全域认知的农业智能系统。
4. 联邦学习+隐私计算:将联邦学习与同态加密、安全多方计算、可信执行环境等隐私计算技术深度融合,构建一个"零信任"的农业数据共享架构。
5. 联邦学习+Few-shot Learning:农业数据标注成本较高,尤其是一些小众作物或罕见病虫害,样本稀缺。利用联邦学习实现跨区域、跨作物的少样本知识迁移,提高小样本条件下农业智能模型的泛化性能。
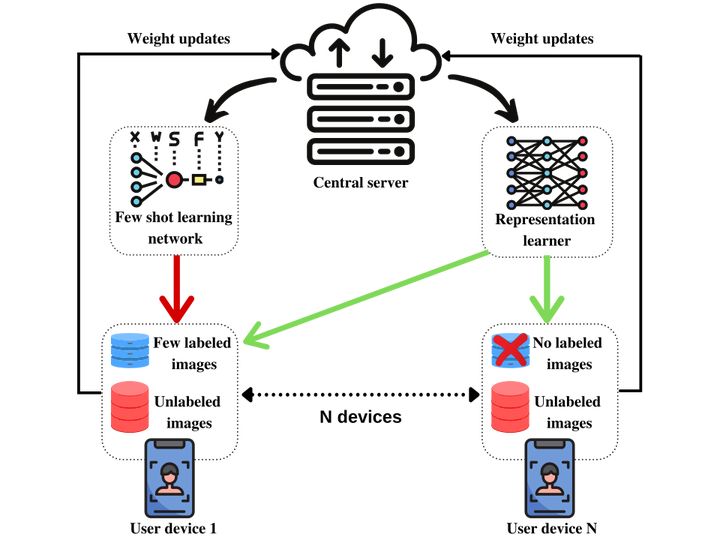
图片来源:FedAffect: Few-Shot Federated Learning for Facial Expression RecognitionHow Meta built a model that really can Segment Anything
六、挑战与展望:迈向农业数据共享的新时代
联邦学习虽然为农业数据共享带来了新的曙光,但在实际落地中仍面临着诸多挑战:
1. 数据标准不一:农业数据种类繁多,格式各异,缺乏统一的数据标准和接口规范,给联邦学习的数据处理带来困难。亟需制定农业数据共享的标准规范,实现数据的无缝衔接。
2. 模型安全隐患:虽然联邦学习不直接共享原始数据,但仍存在模型反推、成员推理等安全隐患。需要借鉴密码学、差分隐私等技术,构建更安全的联邦学习框架。
3. 系统设计复杂:农业场景复杂多变,数据分布不平衡,网络条件有限,对联邦学习系统的设计提出了更高要求。需要在效率、公平性、容错性等方面进行深入优化。
4. 法律政策滞后:数据共享涉及数据产权、隐私保护等法律问题,现有的法律政策还不够完善。需要加快数据共享的立法进程,为联邦学习的应用扫清障碍。
5. 商业模式创新:如何将联邦学习转化为可持续的商业模式,激发各方参与的内生动力,是一个亟待探索的问题。需要创新数据确权、定价、交易等机制,构建共赢的数据经济生态。 展望未来,联邦学习正在为农业大数据共享开启一个全新的时代。随着5G、物联网等新一代信息技术的加速渗透,农业数据将呈现出爆发式增长。联邦学习将成为农业数据共享的重要范式,推动海量异构数据的全面融合和深度协同。在数据要素驱动下,农业生产、经营、管理、服务等环节将实现全面智能化,农业产业链将被重塑,农业生态系统将被重构。
展望未来,联邦学习正在为农业大数据共享开启一个全新的时代。随着5G、物联网等新一代信息技术的加速渗透,农业数据将呈现出爆发式增长。联邦学习将成为农业数据共享的重要范式,推动海量异构数据的全面融合和深度协同。在数据要素驱动下,农业生产、经营、管理、服务等环节将实现全面智能化,农业产业链将被重塑,农业生态系统将被重构。
参考文献:
Federated learning based futuristic biomedical big-data analysis and standardization
The foundations of big data sharing: A CGIAR international research organization perspective
FAIR degree assessment in agriculture datasets using the F-UJI tool
The role of cross-silo federated learning in facilitating data sharing in the agri-food sector
Agroecosystem research with big data and a modified scientific method using machine learning concepts
Image-based crop disease detection with federated learning
A Service-based Joint Model Used for Distributed Learning: Application for Smart Agriculture
Applying federated learning to combat food fraud in food supply chains
Research of Federated Learning Application Methods and Social Responsibility
Big data promises and obstacles: Agricultural data ownership and privacy
Federated Transfer Learning for Rice-Leaf Disease Classification across Multiclient Cross-Silo Datasets