前言
手部姿态估计、手势识别和手部动作识别等任务时,可以转化为对手部关键点的分布状态和运动状态的估计问题。本文主要给出手部关键点数据集获取的方式。
总共获取三个数据集:
handpose_v2:训练集35W张,验证集2.85W张;
HaGRID-pose:训练集15.3W(7.66W原始+7.66W旋转),验证集2.1W张(1.05W原始+1.05旋转);
hand_keypoint_26K:训练集3W张,验证集1.08W张。
正样本总计:593,661张图片(53.33W张用于训练,6.04W张用于验证和测试)。
1.相关项目
[1] Google Mediapipe Hand landmarks detection guide
[2] Openpose-Hand-Detection
主要是Google的Mediapipe和CMU的Openpose,二者关键点标注一样,如下图:

2.手部关键点数据集1:handpose_datasets_v2
2.1 原始数据集获取
项目地址:GitHub - XIAN-HHappy/handpose_x: 手部21个关键点检测,二维手势姿态,手势识别,pytorch,handpose
下载地址:该项目用到的制作数据集下载地址(百度网盘 Password: ara8 )
如下图,该数据集只有手部关键点:

YOLOv8-pose的标签格式是:[cls, xcn, ycn, wn, hn, xkp1n, ykp1, ...],需要bbox,当然也可以把bbox设置为[0.5, 0.5, 1.0, 1.0],但是这样会引入过多背景,影响训练。
2.2 获取bbox
原始JSON数据中,一张图片的标签:
{
'maker': 'Eric.Lee',
'date': '2022-04',
'info': [{'handType': 'Left',
'bbox': [0, 0, 0, 0],
'pts': {'0': {'x': 205, 'y': 53}, '1': {'x': 176, 'y': 37}, '2': {'x': 144, 'y': 40},
'3': {'x': 120, 'y': 46}, '4': {'x': 96, 'y': 44}, '5': {'x': 146, 'y': 55},
'6': {'x': 104, 'y': 70}, '7': {'x': 80, 'y': 79}, '8': {'x': 56, 'y': 90},
'9': {'x': 159, 'y': 77}, '10': {'x': 112, 'y': 95}, '11': {'x': 116, 'y': 82},
'12': {'x': 135, 'y': 70}, '13': {'x': 172, 'y': 95}, '14': {'x': 128, 'y': 111},
'15': {'x': 133, 'y': 98}, '16': {'x': 149, 'y': 87}, '17': {'x': 183, 'y': 109},
'18': {'x': 149, 'y': 121}, '19': {'x': 152, 'y': 110}, '20': {'x': 166, 'y': 102}
}
}]
}
如下图,利用最左、最右、最上和最下的四个点(红色双下划线),计算四个点的最大最小xy作为xyxy,然后再转换为xywhn。

利用关键点提取bbox的关键代码如下:
keypoints_list = [] # 提取关键点坐标,需要进行归一化
x_min, y_min, x_max, y_max = 1e6, 1e6, 0, 0 # 初始化bbox的初始值
for i in range(21):
kp = keypoints_dict.get(str(i), {'x': 0, 'y': 0}) # YOLOv8的二维关键点:不可见/不存在的点坐标置为(0, 0)
if 0 < kp['x'] < shape[1] and 0 < kp['y'] < shape[0]:
normalized_x = kp['x'] / shape[1] # 归一化 x 坐标
normalized_y = kp['y'] / shape[0] # 归一化 y 坐标
keypoints_list.extend([normalized_x, normalized_y])
x_min = min(2, x_min, kp['x'])
y_min = min(2, y_min, kp['y'])
x_max = max(w - 2, x_max, kp['x'])
y_max = max(h - 2, y_max, kp['y'])
else:
keypoints_list.extend([0, 0])如下图,需要注意边界处理,否则坐标为负值,训练加载会被作废:

多可视化一些图片,不难发现:数据集是作者先用手部检测模型获取手部bbox,然后将该bbox扩大一定比例,再用手部关键点检测模型进行自动化标注获得的。因此,使用该数据集训练yolov8-pose时,不能关闭马赛克增强。

再观察一下生成的bbox,不难发现:bbox的xcn和ycn为0.5、0.5,wn和hn为0.6和0.6,即作者将bbox的宽高wh放大了2/3:
0.5 0.5 0.5886524822695035 0.5887850467289719
0.5121951219512195 0.502127659574468 0.6132404181184669 0.5872340425531914
0.5160550458715596 0.49477351916376305 0.6192660550458715 0.5993031358885017
0.49823321554770317 0.5110294117647058 0.6148409893992933 0.6102941176470589
0.4909365558912387 0.5126050420168067 0.6132930513595166 0.60504201680672262.3 数据清洗
原数据有37W张,随机选取32000张作为验证集。
原始数据包含类似以下的低质量图片,需要删掉:

本人选取两个标准:验证集上将尺寸小于100的删除(约2000张),训练集上将尺寸小于75的删除(理论有1.1w张,程序没运行完电脑重启了,结果只删了8000张)。
使用原始handpose_dataset_v2训练的测试结果:
TEST IN ORIGIN HAND_POSE_v2:
Model Size imsize Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95):
m-70 640 >0 all 32000 32000 0.999 0.999 0.995 0.981 0.916 0.896 0.930 0.713
s-300 480 >0 all 41810 32000 1 1 0.995 0.988 0.936 0.923 0.951 0.776
s-300 480 <=75 all 955 955 0.995 0.986 0.995 0.918 0.701 0.554 0.606 0.348
s-300 480 75-100 all 2483 2483 0.998 1 0.995 0.965 0.814 0.760 0.821 0.525
s-300 480 >100 all 28562 28562 1 1 0.995 0.989 0.949 0.942 0.963 0.797
m-70 640 >100 all 28562 28562 0.999 1 0.995 0.984 0.930 0.920 0.945 0.737
m-70-1 480 >100 all 28562 28562 1 1 0.995 0.983 0.936 0.925 0.944 0.725
m-70:yolov8-m-pose训练70轮测试结果;s-300:yolov8-s-pose训练300轮测试结果。s-70-1:使用m-70预训练模型,再最终所有整理好的数据集上微调1轮的测试结果。
由上表知尺寸<=75的图片的测试结果很低,这说明小尺寸和大尺寸图片的预测分布相差较大,所以删除是可行的。(实际上,小尺寸图片大部分是被截断的,关键点就是填满bbox的一条线。)
还可以利用IoU排除预测错误图片,计算图片标准框(原始框的3/5部分)和关键点获取的bbox的重合度,排除低重合度的。但这样做太耗时了,我就没做。
3.手部关键点数据集2:HaGRID-pose
3.1 原始数据集获取
项目地址:GitHub - hukenovs/hagrid: HAnd Gesture Recognition Image Dataset
下载地址:HaGRID 512px - lightweight version of the full dataset with min_side = 512p 26.4 GB
该数据具体介绍过:基于YOLOv8的手部检测(1)- 手部数据集获取(数据集下载、数据清洗、处理与增强)
该数据是用来做手部检测的,但可以利用mediapipe自动标注。
3.2 关键点标注
已知bbox,那只需要获取bbox里的关键点即可。直接使用mediapipe不一定能获取最佳预测结果,有些图片可以扩大检测框获得:

一个好的标注的示例:
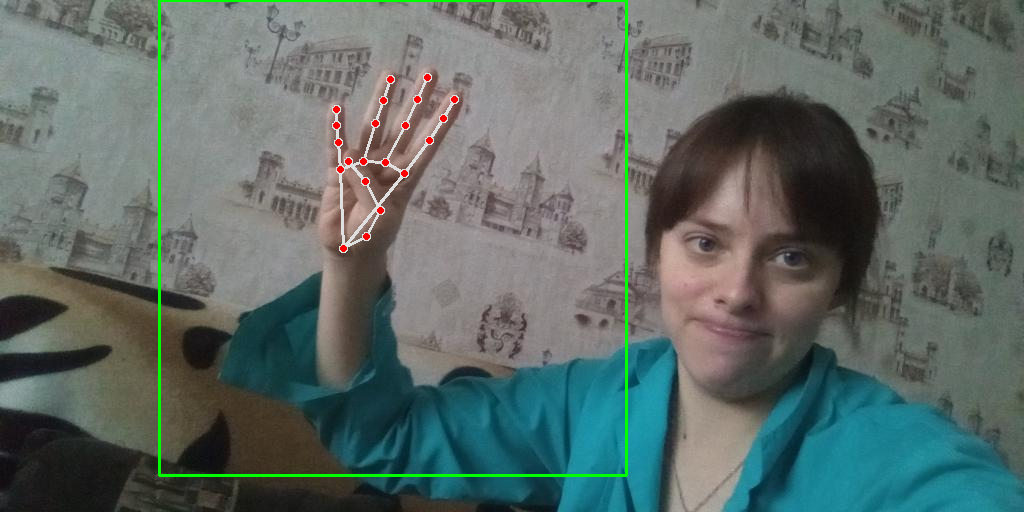
放大带来的问题,导致框内有多只手:

可以控制缩放方式,本人设置放大倍数为enlarge=1.5+0.5n(n=0,1,2...5),最多放大6次,放大到4倍。如下图所示:

检测的区域,可视化到图上就是:

但并不是,放的越大越好:

上图,开始小拇指没检测出,放大到第6和第7次就检测出来了,但第8次又没检测出来,第9次直接检测不出了。
同时,每次都检测6次(或者更多),一张图片就要被mediapipe推理好多次,其本身推理又很慢,处理55W图片必然十分耗时。所以用以下算法流程来实现这个标注过程:
1.初始化bbox参数:扩大系数 a_start=1.5, 迭代轮次 n=0, 迭代增量 p=0.5
2.最佳iou_best=0.0
3.初始检测框bbox
4.当前扩大系数 a_now = a + n * p
5.计算得到扩大的框bbox_enlarge
6.同2.2,利用关键点计算关键点的框bbox_kp
7.计算iou_now=compute_iou(bbox, bbox_kp)
8.i如果iou_now < iou_best: 停止迭代
9.n++
10.n>5就停止,否则跳转到第4步
11.如果iou_best>0.65(一个阈值,越大越匹配),就返回关键点;否则作废
12.矫正关键点
解释:放大框是绿色框,目标框是淡蓝色框,关键点框是红色框,二者的IoU可以直观反映二者的匹配度。在iou_best超过阈值后,并没有立即停止,因为下一次可能更好;而下一次没有更好,则停止,认为当前就是最佳。这样做可以减少检测次数,并最大限度获取最好的检测结果。(最终花了八小时推理完55W张图片,获取17W多张带关键点标签的图片)。

检测框放大bbox_enlarge获取的代码如下:
def process_hagrid_bbox(xc, yc, w, h, w_img, h_img, base_factor=1.2, expand_factor=0.4, iter_num=1, offset=(0, 0)):
"""
将原始的手部目标框区域进行放大。
Args:
xc: 检测框中心点横坐标
yc: 检测框中心点纵坐标
w: 检测框的宽度
h: 检测框的高度
w_img: 图片的宽度
h_img: 图片的高度
base_factor: 基本放大系数
expand_factor: 递增放大系数
iter_num: 放大次数
offset: x和y的平移量。
Returns:
放大后的检测框坐标xyxy
"""
w_new = w * (base_factor + expand_factor * iter_num)
h_new = h * (base_factor + expand_factor * iter_num)
x_min_new = int(max(2, xc - w_new / 2 + offset[0]))
y_min_new = int(max(2, yc - h_new / 2 + offset[1]))
x_max_new = int(min(w_img - 3, xc + w_new / 2 + offset[0]))
y_max_new = int(min(h_img - 3, yc + h_new / 2 + offset[1]))
return np.array([x_min_new, y_min_new, x_max_new, y_max_new], dtype=np.float32)关键点框bbox_kp获取的代码如下:
def process_mp_result(results, region_h, region_w, offset=(0, 0)):
"""
处理mediapipe对手部关键点的预测结果。
Args:
results: mp_hands.Hands.process(img)的结果。
region_h: 手部区域的高度。
region_w: 手部区域的宽度。
offset: 偏移量,为手部区域在实际图片左上角点的(x, y)。
Returns:
xyxy,keypoints:原图中刚好能包住手部区域的矩形框,原图中的关键点。
"""
if results.multi_hand_landmarks is not None:
list_lms = [] # 采集所有关键点坐标
x_min, y_min, x_max, y_max = 1e6, 1e6, 0, 0 # 初始化bbox的初始值
hand = results.multi_hand_landmarks[0]
for i in range(21):
# 获取手部区域的坐标(限制在该区域内),并映射回原始图片
pos_x = min(max(2, int(hand.landmark[i].x * region_w)), int(region_w) - 2) + int(offset[0])
pos_y = min(max(2, int(hand.landmark[i].y * region_h)), int(region_h) - 2) + int(offset[1])
# 保留全部点
list_lms.append((pos_x, pos_y))
# 获取边界框
x_min = min(x_min, pos_x)
y_min = min(y_min, pos_y)
x_max = max(x_max, pos_x)
y_max = max(y_max, pos_y)
return (np.array([x_min - 1, y_min - 1, x_max + 1, y_max + 1], dtype=np.float32),
np.array(list_lms, dtype=np.float32))
return np.empty((0, 4), dtype=np.dtype), np.empty((0, 2), dtype=np.float32)关键点矫正:因为获取的点在检测框外(检测框是手工标注的,以其为标准),将点强制位移到框内,代码如下:
def rectify_keypoints(keypoints, w, h, offset=(0, 0), norm=False):
Args:
keypoints: 关键点
w: 实际检测框的宽度
h: 实际检测框的高度
offset: x,y (高和宽)上的偏移量
norm: 进行归一化
Returns:
校正后的关键点。
keypoints[:, 0] -= int(offset[0])
keypoints[:, 1] -= int(offset[1])
v1 = keypoints[:, 0]
v2 = keypoints[:, 1]
# 预先创建全零数组并使用布尔索引进行条件修改,可以减少重复计算。将边缘、图片外点的值置为0。
# Apply conditions for v1
v1_mod = np.zeros_like(v1)
mask1 = (v1 >= 1) & (v1 <= w - 2)
mask2 = (v1 > w - 2) & (v1 < w + 15)
mask3 = (v1 > -16) & (v1 < 1)
v1_mod[mask1] = v1[mask1]
v1_mod[mask2] = int(w - 2)
v1_mod[mask3] = 1
# Apply conditions for v2
v2_mod = np.zeros_like(v2)
mask1 = (v2 >= 1) & (v2 <= h - 2)
mask2 = (v2 > h - 2) & (v2 < h + 15)
mask3 = (v2 > -16) & (v2 < 1)
v2_mod[mask1] = v2[mask1]
v2_mod[mask2] = int(h - 2)
v2_mod[mask3] = 1
# 更新数组
if norm:
keypoints[:, 0] = v1_mod / w
keypoints[:, 1] = v2_mod / h
else:
keypoints[:, 0] = v1_mod
keypoints[:, 1] = v2_mod
# 如果第 1 维度的第一个或第二个值为 0,则将两个数值都修改为 0
mask = (keypoints[:, 0] == 0) | (keypoints[:, 1] == 0)
keypoints[mask] = 0
return keypoints3.3 标签获取
最终获取的bbox还需要扩大2/3(兼容handpose_v2),并随机增加都动(防止bbox的数据都相同)。具体做法,将bbox_large获取的bbox_kp映射回原图为bbox_mp,再放大2/3,并在每一条边上随机抖动5个像素,最终获取的标签如下:
0.5 0.4868913857677903 0.6288659793814433 0.6217228464419475
0.49059561128526646 0.4925373134328358 0.6300940438871473 0.6069651741293532
0.4894366197183099 0.49053627760252366 0.6126760563380281 0.6088328075709779
上述标签几乎与handpose_v2一致,做可视化:

3.4 增加旋转
增加顺时针旋转90度。因为只有patch,所增加旋转是有意义的,比如下图第一个框,可以看做是躺在“床”上的手势。不用YOLOv8-pose自带旋转的原因:会旋转小于90度,导致检测框变大。

3.5 仅获取手部区域
如下图,我也获取了手部区域用来训练,结果表明非常容易过拟合。

此外,手部关键点检测还依赖手部检测,如果手部检测被截断,会影响手部分析,如下图,手指被截断,导致原本“指”的手势被误认为“拳头”:

同时兼顾到HRNet等其他算法,最终选择扩大2/3的区域用于关键点训练,不过仅手部的关键点数据可以用于姿态分析的网络训练。
3.6 无标签图片的手部关键点获取
和上述步骤仅在手部框上的区别,需要引入手部框的置信度判断,再矫正关键点的时候,也不再强制位移,而是根据框和关键点的置信度,选择较低的进行位移。
3.7 handpose_v2预训练测试结果
旋转数据集相对较难识别:
TEST IN HAGRID:
Model Size Rotate Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95):
m-70 640 True all 14086 14086 1 0.999 0.995 0.870 0.828 0.826 0.802 0.574
s-300 480 True all 14086 14086 1 0.998 0.995 0.872 0.931 0.927 0.939 0.683
m-70-1 480 True all 14086 14086 1 1 0.995 0.955 0.997 0.997 0.995 0.923
m-70 640 False all 14086 14086 1 1 0.995 0.873 0.993 0.992 0.994 0.823
s-300 480 False all 14086 14086 1 1 0.995 0.871 0.993 0.992 0.994 0.832
m-70-1 480 False all 14086 14086 1 1 0.995 0.953 0.998 0.998 0.995 0.9414.手部关键点数据集3:hand_keypoint_26k
4.1 原始数据集获取
下载地址:https://www.kaggle.com/datasets/riondsilva21/hand-keypoint-dataset-26k
相关项目:https://sites.google.com/view/11khands
https://www.kaggle.com/datasets/ritikagiridhar/2000-hand-gestures
https://www.kaggle.com/datasets/imsparsh/gesture-recognition
下面也介绍过:
基于YOLOv8的手部检测(1)- 手部数据集获取(数据集下载、数据清洗、处理与增强)
4.2 数据集可视化
简单的数据集,只需要筛一下图片。这里仅做可视化:

4.3 handpose_v2预训练测试结果
简单图片也预测不好,说明肯定没训练好,所以加入训练,一轮训练就可以学习好:
TEST IN HAND_KEYPOINT_26K:
Model Size Rotate Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95):
m-70 640 True all 10852 10852 0.562 0.569 0.44 0.164 0.578 0.569 0.446 0.210
s-300 480 True all 10852 10852 0.610 0.528 0.46 0.187 0.539 0.478 0.374 0.171
m-70-1 480 True all 10852 10852 0.989 0.989 0.994 0.884 0.947 0.930 0.952 0.796
m-70-1 480 True all 3636 3636 0.988 0.991 0.995 0.886 0.944 0.932 0.954 0.8015.其他手部关键点数据集
Kaggle上有一些,但质量比较低,需要自己筛选;还有非真实的数据集,和一些3D姿态估计的也可以用:
https://github.com/guiggh/hand_pose_action
http://www.victoria.ac.nz/llc/llc_resources/nzsl/
A. Memo, L. Minto, P. Zanuttigh, "Exploiting Silhouette Descriptors and Synthetic Data for Hand Gesture Recognition", STAG: Smart Tools & Apps for Graphics, 2015.
6.负样本数据集
同:
基于YOLOv8的手部检测(1)- 手部数据集获取(数据集下载、数据清洗、处理与增强)
7.最终用于训练的数据集
训练集总共681,590张(533,291张正样本,148,299张负样本);
验证集总共70,180张(60,370张正样本,9,810张负样本):
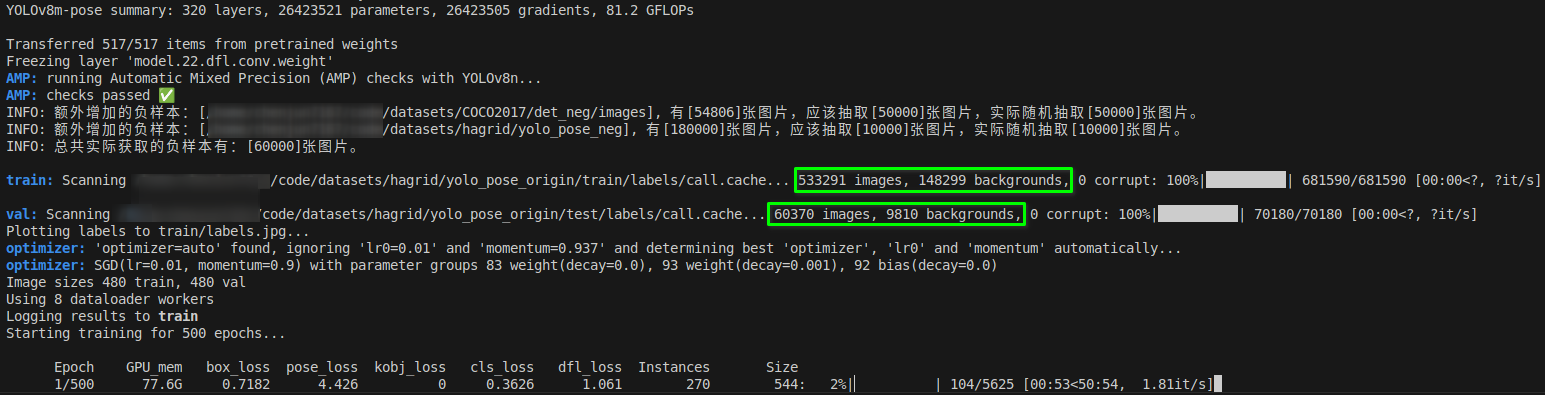
YOLOv8-pose的data.yaml
# path: ../datasets/coco-pose # dataset root dir
train: ['./datasets/handpose_v2/yolov8_pose/train/images',
'./datasets/hagrid/yolo_pose_origin/train/images',
'./datasets/hagrid/yolo_pose_origin/val/images',
'./datasets/hagrid/yolo_pose_rotate/train/images',
'./datasets/hagrid/yolo_pose_rotate/val/images',
'./datasets/hand_keypoint_26k/yolo_pose/train/images',
'./datasets/negative_dataset/neg_hand/train']
val: ['./datasets/handpose_v2/yolov8_pose/val/images',
'./datasets/hagrid/yolo_pose_origin/test/images',
'./datasets/hagrid/yolo_pose_rotate/test/images',
'./datasets/hand_keypoint_26k/yolo_pose/val/images',
'./datasets/negative_dataset/neg_hand/val']
# Keypoints
kpt_shape: [21, 2] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 ,13 ,14, 15, 16, 17, 18, 19, 20]
# Add negative image --------------------------------------------------------------------
negative_setting:
neg_ratio: 0 # 小于等于0时,按原始官方配置训练,大于0时,控制正负样本。
use_extra_neg: True
extra_neg_sources: {"./datasets/COCO2017/det_neg/images" : 50000,
"./datasets/hagrid/yolo_pose_neg": 10000,
} # 数据集字符串或列表(图片路径或图片列表)
fix_dataset_length: 0 # 720000 # 是否自定义每轮参与训练的图片数量
# Classes
names:
0: hand