前言
我们在前面讲解 GraphRag 从原始文本中提取知识图谱和构建图结构的时候,最后存储的文件是parquet 格式,文件存储在下面文件夹:
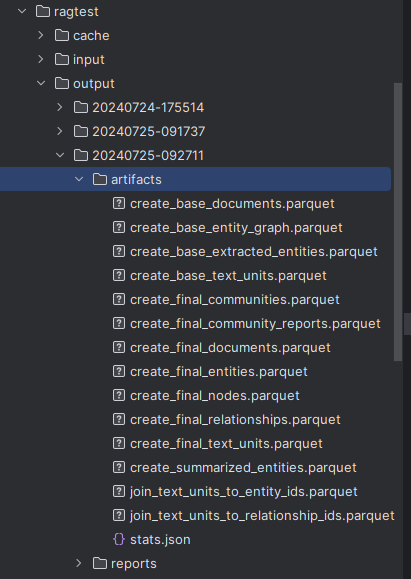
这节我们就探索一下怎么将我们生成好的图谱文件导入到我们的 Neo4j 图数据库,最后进行可视化分析,也能和我们之前的项目混合检索结合起来。
一、准备工作
新建一个 python 脚本文件,比如 graphrag_import.py 可以放在项目的根目录,这里可以随便选择,然后设置我们GraphRAG 生成的图谱文件目录:
GRAPHRAG_FOLDER="artifacts"
安装 neo4j ,如果前面安装过,可以忽略:
pip install --upgrade --quiet neo4j
导入我们需要的库:
import pandas as pd
from neo4j import GraphDatabase
import time
设置我们的 Neo4j 图库地址,账户密码,以及要导入的数据库名字:
NEO4J_URI="bolt://********:7687"
NEO4J_USERNAME="neo****"
NEO4J_PASSWORD="*****"
NEO4J_DATABASE="****"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
下载一个语料数据集,https://www.gutenberg.org/cache/epub/24022/pg24022.txt 。
根目录新建 /ragtest/input 空文件,然后把下载好的语料文件放入 input 下面。
二、创建约束
定义一个批处理方法, 使用批处理方法将数据导入 Neo4j 。
参数:statement 是要执行的 Cypher 查询,df 是要导入的数据框,batch_size 是每批要导入的行数。
def batched_import(statement, df, batch_size=1000):
total = len(df)
start_s = time.time()
for start in range(0,total, batch_size):
batch = df.iloc[start: min(start+batch_size,total)]
result = driver.execute_query("UNWIND $rows AS value " + statement,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary