文章目录
- opencv介绍与安装
- KNN算法中opencv的运用
- 1.数据介绍
- 2.图片处理
- 3.图像切分与重组
- 4.分配标签
- 5.模型构建与训练
- 6.预测结果
- 7.模拟测试
- 8.代码及详注
opencv介绍与安装
OpenCV(Open Source Computer Vision Library,开源计算机视觉库)是一个跨平台的计算机视觉库,它主要关注实时的图像处理和计算机视觉任务。OpenCV由Intel在1999年发起,并由Willow Garage和其他贡献者继续维护。现在,OpenCV已经发展成为一个功能强大、易于使用的库,广泛应用于图像处理、视频分析、机器学习、物体检测、人脸识别、运动跟踪等领域。
opencv-python是OpenCV的Python接口,它允许Python开发者使用OpenCV的强大功能。opencv-python通过Python的pip包管理工具可以轻松安装,使得Python程序员能够方便地在Python程序中调用OpenCV的函数和类,进行图像处理和计算机视觉相关的开发。
在Python环境中安装opencv-python非常简单,只需要使用pip命令即可:
pip install opencv-python
KNN算法中opencv的运用
1.数据介绍
这里我们通过运用opencv来实现一个简单的图像数字识别,这里我们选取一张像素为1000*2000,行为50,列为100的图像来识别,具体如下图:

2.图片处理
这里我们需要将图片进行初步处理,即图片读取与灰度图转换,读取图片的步骤是图像处理和分析的基础,它允许程序访问和操作图像的像素数据。灰度图转换的步骤通常用于图像预处理,因为它简化了图像,去除了颜色信息,使得后续的图像处理任务(如边缘检测、特征提取、图像分割等)更加容易和高效。
import cv2
import numpy as np
img = cv2.imread('digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
3.图像切分与重组
将所得灰度图按照垂直轴分割成50份,再沿水平轴切分100份,这样我们就得到了大小为2020的5000份独立的数字,并将数据装入array,再将所得数据按照比例1:1分为训练集与测试集, 将数据构造为符合KNN的输入,将每个数字的尺寸由2020调整为1*400
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
x = np.array(cells)
train = x[:, :50]
test = x[:, 50:100]
train_new = train.reshape(-1, 400).astype(np.float32)
test_new = test.reshape(-1, 400).astype(np.float32)
4.分配标签
创建一个包含0~9的数组,并将数组的每一个元素重复250次,通过使用np.newaxis,在labels数组上增加了一个新的维度,将原本形状为(2500,)的一维数组转换为了形状为(2500, 1)的二维数组。
k = np.arange(10)
labels = np.repeat(k, 250)
train_labels = labels[:, np.newaxis]
test_labels = np.repeat(k, 250)[:, np.newaxis]
5.模型构建与训练
通过cv2.ml.KNearest_create()函数创建一个KNN模型的实例,通过knn.train()方法来训练模型,每个测试数据集中的每个样本都被预测为其最近的3个邻居中多数所属的类别。
knn = cv2.ml.KNearest_create()
knn.train(train_new, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test_new, k=3)
6.预测结果
通过比较KNN模型预测的类别标签索引(result)与真实的测试标签(test_labels)是否相等,然后计算数据中非0的个数与总数的比重来计算模型的准确率。
matches = result == test_labels
correct = np.count_nonzero(matches)
accuracy = correct * 100.0 / result.size
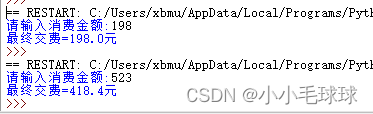
print("当前使用KNN识别手写数字的准确率为:", accuracy)
这里最终的得到的准确率结果为91.64%
7.模拟测试
这里我们又手动添加了两个数字来进行检验,查看最终得出结果是否与所写数字结果一致,来判断准确性。这里我们添加了数字3和9进行检验。


img_9 = cv2.imread('9.png')
img_3 = cv2.imread('3.png')
gray1 = cv2.cvtColor(img_9, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img_3, cv2.COLOR_BGR2GRAY)
x1 = np.array(gray1)
x2 = np.array(gray2)
test_9 = x1.reshape(-1, 400).astype(np.float32)
test_3 = x2.reshape(-1, 400).astype(np.float32)
ret1, result1, neighbours1, dist1 = knn.findNearest(test_9, k=3)
ret2, result2, neighbours2, dist2 = knn.findNearest(test_3, k=3)
print(result1, "\n", result2)
#输出结果:
[[1.]]
[[3.]]
这里结果输出为1和3,其中数字9检验出现问题,证明准确性确实存在一定问题。(注意:该两组图片大小均为20*20,所有不需要切分。)
8.代码及详注
import cv2
import numpy as np
img = cv2.imread('digits.png') # 读取图片
img_9 = cv2.imread('9.png')
img_3 = cv2.imread('3.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图转换
gray1 = cv2.cvtColor(img_9, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img_3, cv2.COLOR_BGR2GRAY)
# 将数据划分成独立的数字,每个数字大小20*20,共计5000个
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
# 将数据装进array,形状(50,100,20,20),50行,50列,图像大小20*20
x = np.array(cells)
x1 = np.array(gray1)
x2 = np.array(gray2)
train = x[:, :50] # 划分训练集与测试集,比例各一半
test = x[:, 50:100]
# 将数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400
train_new = train.reshape(-1, 400).astype(np.float32)
test_new = test.reshape(-1, 400).astype(np.float32)
test_9 = x1.reshape(-1, 400).astype(np.float32)
test_3 = x2.reshape(-1, 400).astype(np.float32)
# 分配标签:分别为训练数据、测试数据分配标签
k = np.arange(10)
labels = np.repeat(k, 250) # 重复数组中的元素,每个元素重复250次
train_labels = labels[:, np.newaxis] # np.newaxis是Numpy库中的一个特殊对象,用于在数组中增加一个新的维度
test_labels = np.repeat(k, 250)[:, np.newaxis]
# 模型构建+训练
knn = cv2.ml.KNearest_create() # 通过cv2创建一个knn模型
knn.train(train_new, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test_new, k=3)
ret1, result1, neighbours1, dist1 = knn.findNearest(test_9, k=3)
ret2, result2, neighbours2, dist2 = knn.findNearest(test_3, k=3)
# ret:表示查找是否成功。
# result:浮点数数组,表示测试样本的预测标签。
# neighbours:这是一个整数数组,表示与测试样本最近的k个邻居的索引,这些索引对应于训练集中的样本,可以用来检查哪些训练样本对预测结果产生了影响。
# dist:浮点数数组,表示测试样本与每个最近邻居之间的距离,这些距离可以帮助理解预测结果的置信度:距离越近,预测通常越可靠。
print(result1, "\n", result2)
# 通过比较KNN模型预测的类别标签索引(result)与真实的测试标签(test_labels)来计算模型的准确率。
matches = result == test_labels # 判断标签索引(result)与真实的测试标签(test_labels)是否相等
correct = np.count_nonzero(matches) # 数取matches中非0的个数
accuracy = correct * 100.0 / result.size # 通过计算非0个数与总数的比值得出准确率
print("当前使用KNN识别手写数字的准确率为:", accuracy)
本代码通过opencv来建立KNN模型来训练算法,并通过比较类别标签索引(result)与真实的测试标签(test_labels)来计算模型的准确率。最终得到准确率为91.64,虽然简单直观,但通过调整k值能获取不同的准确率,选取不恰当时可能会造成较大影响。