小罗碎碎念
这一期推文,跟你们分享一些比较底层,并且顶刊中不会涉及但是又至关重要的内容。
我们在做任何一个病理AI的项目前,有两样东西是一定会拿到手的——切片&对应的临床基线表。(如果做多组学/多模态的项目,还会拿到测序数据和影像数据,但是如果单病理的你都处理不好,扩大队列你更懵)
前两天有篇推文讲了,我们对于临床基线表的很多信息都没有挖掘出来。

所以我也准备了一期推文,试图梳理拿到基线表以后的一个标准流程,目前还在筹划中。

今天这期的推文想讲的是另一个东西——切片的导出&处理
病理切片的存储格式很多种,不同公司扫描仪导出的片子格式也不同,江丰的是kfb,蔡司的是czi。
我们处理片子的时候,用的是openslide包,而恰好这两种格式都不能直接用它打开,因此我们需要借助程序来转换格式。
在正式介绍如何转换格式之前,我会先介绍病理图像常用的常用存储格式以及超高分辨率数字图像的金字塔结构,最后再介绍如何转换WSI的格式。
一、病理图像的常用存储格式
1-1:TIFF格式
病理图像,特别是全切片病理图像(Whole Slide Images, WSI),可以采用多种存储格式。这里着重介绍一下TIFF格式。
标签图像文件格式(TIFF,Tagged Image File Format)是一种广泛使用的位图图像格式,以其灵活性和对高分辨率图像的支持而受到青睐。
在病理学领域,TIFF格式尤其重要,因为病理图像通常包含大量的细节,尺寸巨大,如CMU-1.tiff示例图像,其分辨率高达46000x32914像素,这对计算机内存和处理能力提出了很高的要求。
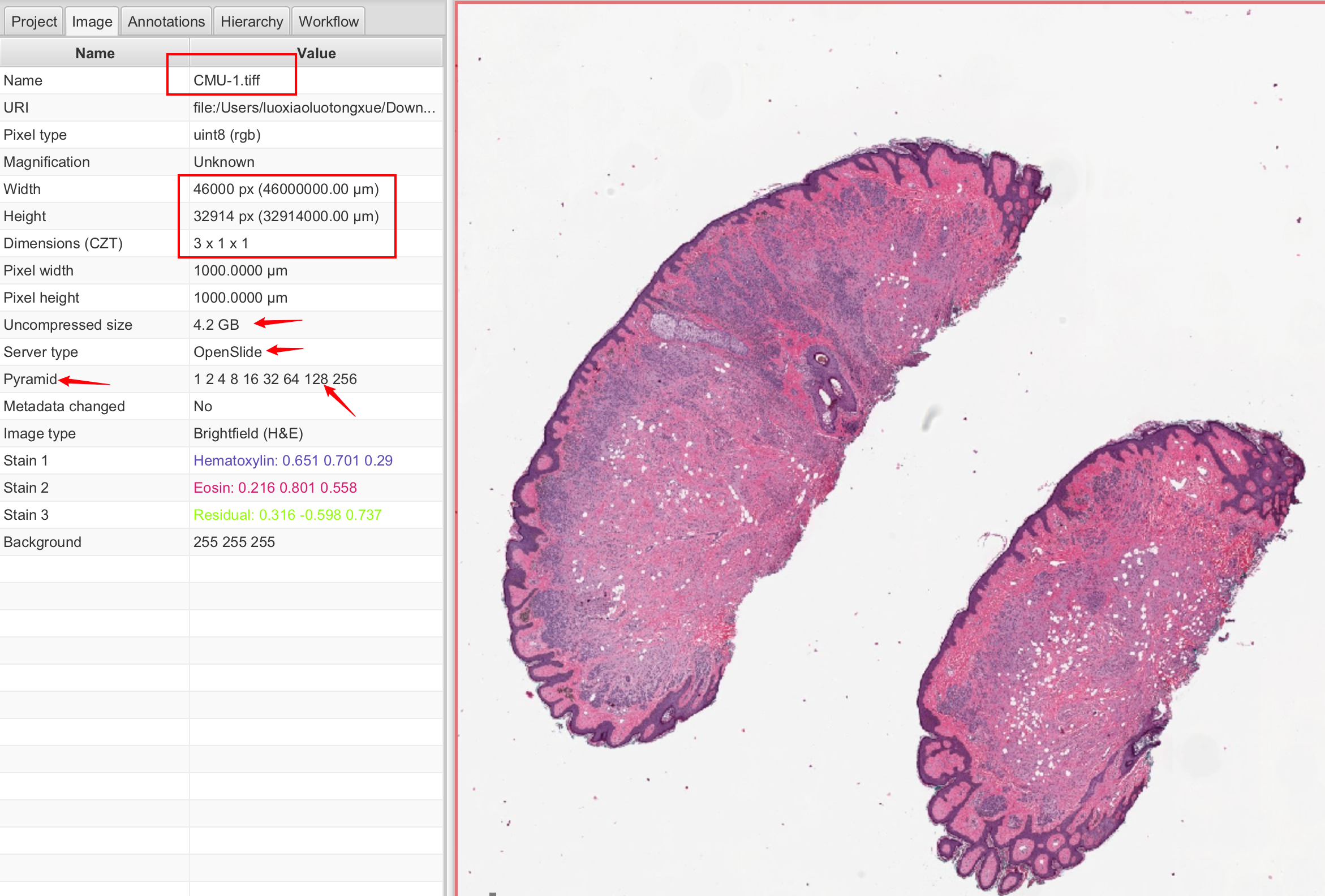
为了有效处理这些大型图像,图像平铺(tiling)和缩放金字塔(pyramid)技术被广泛应用。平铺技术涉及将大图像分割成小块(tile),每块通常为256x256像素。这样,只有当前需要显示或处理的图像块会被加载到内存中,而不是整个图像,这大大减少了内存的使用并提高了处理效率。
此外,这些tile可以使用不同的编码技术进行压缩,以进一步减少存储需求和提高加载速度。在TIFF格式中,LZW(Lempel-Ziv-Welch)和JPEG是常用的压缩编码。
缩放金字塔技术则是在图像的原始分辨率基础上创建多个分辨率逐渐降低的副本,形成一个金字塔结构。这些副本可以按照2的幂次(例如,1/2,1/4,1/8,1/16原图尺寸)进行下采样。在图像处理或分析时,可以根据需要选择适当的分辨率级别,从而在不同的尺度上进行操作,这在进行图像特征提取或模式识别时非常有用。
尽管TIFF格式本身不强制要求图像必须是平铺或金字塔结构,但在病理图像分析中,某些库如OpenSlide要求TIFF图像必须是平铺的,以便能够正确读取和处理。如果一个TIFF图像没有按照这些要求进行配置,OpenSlide可能会报告格式不支持的错误。因此,为了确保与这些工具的兼容性,病理图像的TIFF格式通常需要进行特定的预处理,以满足平铺和金字塔结构的要求。
总之,TIFF格式及其相关的平铺和缩放金字塔技术为病理图像的存储、传输和分析提供了有效的解决方案,使得在有限的计算资源下处理大规模图像成为可能。
1-2:其余常见的病理图像存储格式及其特点
- SVS格式:SVS(Supported Vector Graphics format)是一种Tiled TIFF图像,用于存储高分辨率的病理图像。SVS格式支持金字塔结构,可以存储不同放大倍数下的图像信息,便于病理学家进行详细观察。SVS文件通常包含主图像和附加页面,如标签、概览图像以及缩放的副本。
- DICOM格式:DICOM(Digital Imaging and Communications in Medicine)是医学图像和相关信息的国际标准。虽然DICOM最初主要用于放射医疗图像,但它也支持存储病理图像。DICOM文件包含丰富的元数据,如患者信息和扫描参数,适合在不同设备和系统之间传输和共享。
- NIFTI格式:NIFTI(Neuroimaging Informatics Technology Initiative)格式最初用于存储神经影像数据,但也适用于存储3D医学图像。NIFTI文件包含图像数据和头部信息,后者描述了图像的元数据,如像素大小和图像方向。
- Analyze格式:Analyze格式包含两个文件:一个头文件(.hdr)包含图像的元数据,一个数据文件(.img)包含图像数据。这种格式常用于医学图像处理软件。
- PAR/REC格式:这是飞利浦MRI扫描设备使用的数据格式,PAR文件包含扫描参数,REC文件包含原始图像数据。
- NRRD格式:NRRD(Nearly Raw Raster Data)是一种用于存储多维数组数据的格式,特别适用于医学图像。它支持任意维度的数据,并可以包含与数据相关的元数据。
这些格式中,SVS和TIFF是病理图像中最常用的两种格式,它们能够有效地存储和处理高分辨率的病理图像数据。DICOM格式因其标准化和互操作性,在医学影像领域得到广泛应用,包括病理图像的存储和传输。
二、图像金字塔
病理图为金字塔结构,level_count属性是获取svs有多少层。在svs中存储了每一层采样的tiles。一般情况下Level0为原图,也就是highest resolution,然后每一级进行下采样,level_count -1为lowest resolution。

图像金字塔是一种在图像处理和计算机视觉中常用的数据结构,它为同一张图像的不同层级提供了不同分辨率的视图。
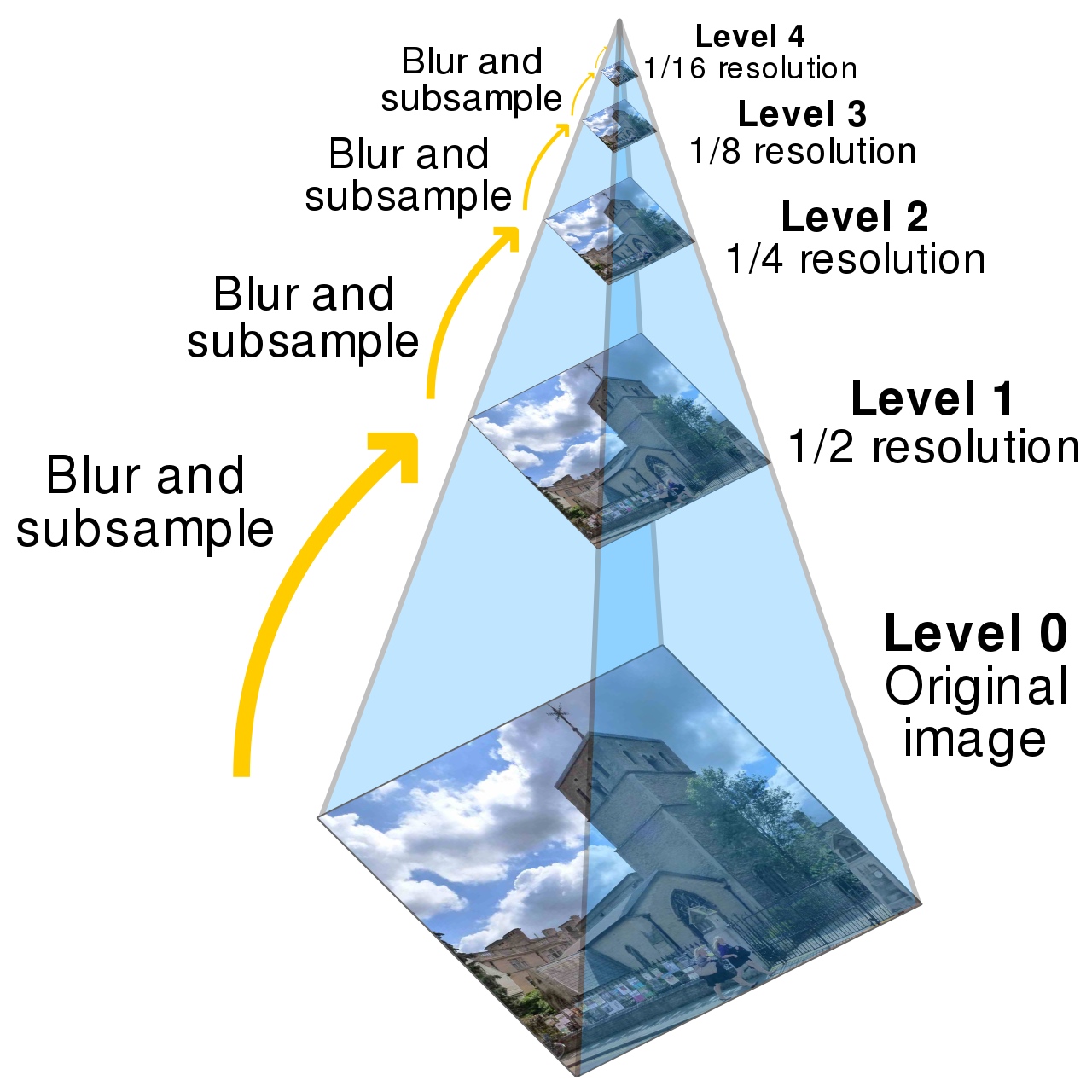
这种结构之所以重要,是因为它允许算法在多个尺度上分析图像,这在很多应用中都非常有用,比如图像识别、目标检测、图像融合等。
2-1:图像金字塔的构建
构建图像金字塔的过程通常涉及以下几个步骤:
-
原始图像获取:首先,需要有一个高分辨率的原始图像作为起点。
-
降采样:通过降采样技术,如最邻近插值、双线性插值或更高级的方法,将原始图像缩小到较小的尺寸。这个过程会逐渐减少图像的分辨率,同时增加图像的层级。
-
重复过程:重复降采样过程,直到图像缩小到所需的最小尺寸或达到预设的层级数。
-
存储结构:所有这些不同分辨率的图像按照从大到小的顺序排列,形成一个金字塔结构。
2-2:图像金字塔的类型
-
高斯金字塔:每一层的图像都是通过高斯低通滤波后降采样得到的,这样可以减少混叠效应,保留图像的重要特征。
-
拉普拉斯金字塔:在高斯金字塔的基础上,通过计算相邻层之间的差异来创建额外的细节层,这有助于图像重建和分析。
-
K-L金字塔:基于Karhunen-Loève变换,这种金字塔在图像压缩领域有应用。
2-3:图像金字塔的应用
-
多尺度分析:在图像中搜索特定特征或对象时,可以在不同分辨率的图像上进行,以适应不同大小的目标。
-
图像融合:在图像拼接或图像融合任务中,使用金字塔方法可以更好地处理不同图像间的接缝。
-
图像压缩:在某些图像压缩算法中,图像金字塔可以有效地表示图像在不同分辨率下的信息。
-
计算机视觉算法:在诸如SIFT(尺度不变特征变换)等算法中,图像金字塔是关键组成部分,用于检测和描述图像中的关键点。
-
实时视频处理:在视频流处理中,图像金字塔可以用于快速目标跟踪,因为它允许在不同时间尺度上分析运动。
2-4:结论
图像金字塔提供了一种灵活的方式来处理和分析图像数据,它通过在多个尺度上表示图像,增强了算法对图像内容的理解和处理能力。随着计算资源的增加和算法的优化,图像金字塔在现代图像处理和计算机视觉任务中的应用越来越广泛。
三、格式转换
一般来讲,如果我们用的扫描仪是江丰的,那么图像格式是kfb,如果用的扫描仪是蔡司的,则格式为czi,这里先介绍如何将kfb的格式转换为svs,后面的推文会介绍如何将czi转换为TIFF。
3-1:配套软件
注意,后面介绍的代码要在Windows中运行,并且需要搭配配套的软件使用。
软件获取地址:https://github.com/Lxltxpku/Share

3-2:配套代码
import os # 引入os模块,用于操作文件和目录
import sys # 引入sys模块,用于访问与Python解释器相关的变量和函数
import subprocess # 引入subprocess模块,用于执行命令行命令
from time import time # 引入time函数,用于测量时间
from glob import glob # 引入glob模块,用于文件名模式匹配
def main():
# 设置源文件夹名称、目标文件夹名称和转换级别
src_folder_name = 'Raw' # KFB文件所在文件夹
des_folder_name = 'Raw-svs' # 保存SVS文件的文件夹
level = 9 # 设置转换级别
# 设置转换程序的路径
exe_path = r'E:\...\...\...\KFbioConverter.exe' # 下载的转换程序所在文件夹
if not os.path.exists(exe_path):
raise FileNotFoundError('Could not find convert library.') # 如果转换程序不存在,抛出异常
# 检查级别是否在2到9之间
if int(level) < 2 or int(level) > 9:
raise AttributeError('NOTE: 2 < [level] <= 9') # 如果级别不在范围内,抛出异常
# 设置当前工作目录
pwd = r'E:\...'
full_path = os.path.join(pwd, src_folder_name) # 拼接源文件夹的完整路径
dest_path = os.path.join(pwd, des_folder_name) # 拼接目标文件夹的完整路径
if not os.path.exists(full_path):
raise FileNotFoundError(f'could not get into dir {src_folder_name}') # 如果源文件夹不存在,抛出异常
if not os.path.exists(dest_path):
os.makedirs(dest_path) # 如果目标文件夹不存在,创建它
# 获取源文件夹中的所有kfb文件
kfb_list = os.popen(f'dir {full_path}').read().split('\n')
kfb_list = [elem.split(' ')[-1] for elem in kfb_list if elem.endswith('kfb')]
# 打印找到的kfb文件数量,并开始转换
print(f'Found {len(kfb_list)} slides, transfering to svs format ...')
for elem in kfb_list:
st = time() # 记录开始时间
kfb_elem_path = os.path.join(full_path, elem) # 获取单个kfb文件的完整路径
svs_dest_path = os.path.join(dest_path, elem.replace('.kfb', '.svs')) # 构建目标svs文件的路径
command = f'{exe_path} {kfb_elem_path} {svs_dest_path} {level}' # 构建转换命令
print(f'Processing {elem} ...') # 打印正在处理的文件名
p = subprocess.Popen(command) # 执行转换命令
p.wait() # 等待命令执行完成
print(f'\nFinished {elem}, time: {time() - st}s ...') # 打印完成信息和所用时间
# 程序入口点
if __name__ == "__main__":
main()










![[开源] 安卓系统发送modbus协议到硬件设备下位机](https://i-blog.csdnimg.cn/direct/262d6dc3af2f4e808c8bdc960fee08ad.png)