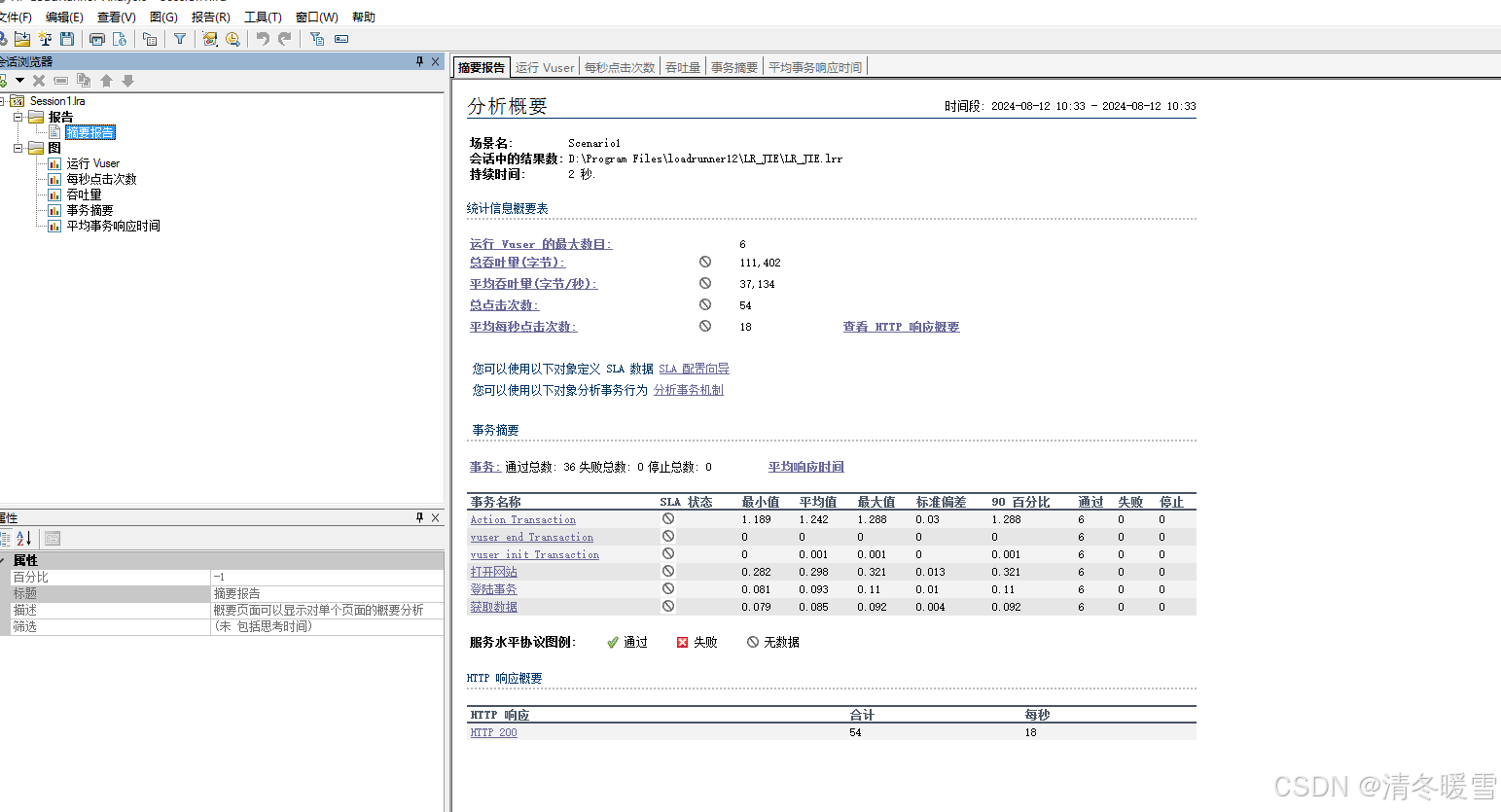
目录
Redis概述
简介
特点
架构
使用场景
Mermaid图示
Redis数据类型
基础数据类型
扩展数据类型(Redis 3.2及以上版本)
Mermaid图示
String类型详解
定义
内部实现
应用场景
Mermaid图示
List类型详解
定义
内部实现
应用场景
Mermaid图示
Hash类型详解
定义
内部实现
应用场景
Mermaid图示
Set类型详解
定义
内部实现
应用场景
Mermaid图示
Zset类型详解
定义
特点
应用场景
内部实现
Mermaid图示
扩展数据类型详解
BitMap
HyperLogLog
GEO
Stream
Mermaid图示
Redis性能优化策略
选择合适的数据类型和命令
避免在大数据量下进行复杂的集合操作
Mermaid图示
Redis概述
简介
Redis(Remote Dictionary Server)是一个开源的高性能键值数据库,以其内存中数据存储、支持数据持久化、丰富的数据结构和原子操作而闻名。它通常用作数据库、缓存和消息队列系统。
特点
-
内存中数据存储:数据主要存储在内存中,提供快速的读写访问。
-
持久化:支持将内存中的数据保存到磁盘,确保数据的持久性。
-
丰富的数据类型:支持字符串、列表、集合、有序集合、散列等多种数据类型。
-
原子操作:提供原子的增删改查操作,适用于计数器、分布式锁等场景。
-
高可用性:通过主从复制、哨兵系统和集群支持高可用性。
架构
Redis的架构通常包括:
-
单节点:所有数据存储在一个Redis实例中。
-
主从复制:一个主节点负责写操作,多个从节点负责读操作,实现读写分离。
-
哨兵系统:监控主节点状态,自动进行故障转移。
-
集群:多个Redis节点组成的分布式系统,提供数据分片和高可用性。
使用场景
-
缓存:减少数据库访问,提高应用性能。
-
会话存储:存储用户会话信息。
-
消息队列:实现应用之间的异步消息传递。
-
排行榜:存储和更新排行榜数据。
-
实时分析:进行实时数据的统计和分析。
Mermaid图示
以下是Redis架构的Mermaid图示:
 这个图展示了Redis的主从复制架构和哨兵系统,以及它们与应用的交互。
这个图展示了Redis的主从复制架构和哨兵系统,以及它们与应用的交互。
Redis数据类型
Redis提供了多种数据类型,以满足不同场景的数据存储需求。
基础数据类型
-
String(字符串)
-
基本的key-value结构,value可以是字符串或数字。
-
适用于计数器、缓存等场景。
-
-
List(列表)
-
有序列表,支持两端插入和删除。
-
可用于消息队列、栈或队列实现。
-
-
Set(集合)
-
无序集合,元素唯一。
-
适用于去重、集合运算等。
-
-
Zset(有序集合)
-
每个元素关联一个分数,元素按分数排序。
-
适用于排行榜、范围查询等。
-
扩展数据类型(Redis 3.2及以上版本)
-
BitMap(位图)
-
使用位来存储信息。
-
适用于状态跟踪、稀疏数据集。
-
-
HyperLogLog(基数统计)
-
用于估算集合中不同元素的数量。
-
节省内存,适用于大规模数据集。
-
-
GEO(地理位置)
-
存储地理位置信息。
-
支持地理查询,如距离、半径查询。
-
-
Stream(流)
-
消息队列数据结构。
-
支持消费者组、消息持久化。
-
Mermaid图示
以下是Redis数据类型及其使用场景的Mermaid图示:
 这个图展示了Redis的九种数据类型及其主要使用场景。
这个图展示了Redis的九种数据类型及其主要使用场景。
String类型详解
定义
String类型是Redis中最基础的数据结构,它提供了简单的key-value存储功能。其中,key是数据的唯一标识符,而value可以是字符串或者数字。
内部实现
-
int:如果value是一个整数值,Redis会使用整数类型来存储。
-
SDS(Simple Dynamic String):如果value是一个字符串,Redis使用SDS来存储。SDS是C语言中的一个字符串库,具有以下特点:
-
二进制安全:可以存储任何类型的数据。
-
获取字符串长度的时间复杂度为O(1)。
-
避免缓冲区溢出:SDS在处理字符串时会自动扩展内存。
-
应用场景
-
存储对象:可以存储序列化后的JSON对象,或者使用特定的key来分别存储对象的不同字段。
-
数据计数:适用于实现访问计数器,如页面访问次数、商品点击量等。
-
分布式锁:使用
SET命令的NX(Not Exist)选项实现锁的功能。 -
共享Session信息:在分布式系统中,使用Redis作为Session存储,实现用户状态的共享。
Mermaid图示
以下是String类型的内部实现和应用场景的Mermaid图示:
 这个图展示了String类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解String类型在Redis中的作用和优势。
这个图展示了String类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解String类型在Redis中的作用和优势。
List类型详解
定义
List类型在Redis中是一个双向链表结构,它可以存储一系列的字符串元素,元素在链表中有序,并且可以支持从链表的头部或尾部插入或删除元素。
内部实现
-
双向链表:当List的元素数量较少时,Redis使用双向链表作为底层实现,以便快速地进行插入和删除操作。
-
压缩列表:当List的元素数量较多时,Redis可能会使用压缩列表来存储元素,以节省内存空间。
应用场景
-
消息队列:List类型可以作为消息队列使用,生产者可以使用
LPUSH命令从头部插入消息,消费者可以使用RPOP命令从尾部取出消息。 -
消息的可靠性:为了确保消息的可靠性,可以使用
BRPOPLPUSH命令,它允许消费者从列表中取出消息的同时,将消息插入到另一个列表中,以备不时之需。
Mermaid图示
以下是List类型的内部实现和应用场景的Mermaid图示:

这个图展示了List类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解List类型在Redis中的使用方式和优势。
Hash类型详解
定义
Hash类型在Redis中是一个键值对集合,其中每个键(field)对应一个值(value)。这种结构非常适合存储对象,因为对象通常由多个属性组成。
内部实现
-
压缩列表:当Hash中的元素数量较少时,Redis使用压缩列表作为底层数据结构,这有助于节省内存。
-
哈希表:当元素数量增加到一定程度时,Redis会使用哈希表来存储Hash类型,以提供更快的查找速度。
应用场景
-
存储对象:例如,用户信息可以存储在一个Hash中,其中用户的ID作为key,而用户的姓名、年龄等属性作为field-value对存储在Hash中。
-
购物车:可以使用用户的ID作为key,商品ID作为field,商品数量作为value,构建购物车。
Mermaid图示
以下是Hash类型的内部实现和应用场景的Mermaid图示:
 这个图展示了Hash类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解Hash类型在Redis中如何用于存储和管理复杂的数据结构。
这个图展示了Hash类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解Hash类型在Redis中如何用于存储和管理复杂的数据结构。
Set类型详解
定义
Set类型在Redis中是一个无序集合,它能够存储不重复的元素。这意味着每个元素在集合中都是唯一的。
内部实现
-
整数集合:当Set中的元素都是整数且数量较少时,Redis使用整数集合作为底层数据结构,这有助于节省内存和提高性能。
-
哈希表:当Set中的元素包含非整数或元素数量较多时,Redis使用哈希表来存储Set类型,以保持元素的唯一性和快速查找。
应用场景
-
数据去重:Set类型可以确保存储的数据不会有重复,适用于需要去重的场景,如用户ID的存储。
-
集合运算:Redis的Set类型支持交集(SINTER)、并集(SUNION)、差集(SDIFF)等集合运算,适用于需要进行数据聚合或筛选的场景。
Mermaid图示
以下是Set类型的内部实现和应用场景的Mermaid图示:
 这个图展示了Set类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解Set类型在Redis中如何用于处理无序且元素唯一的数据集合。
这个图展示了Set类型的定义、内部实现方式以及它的主要应用场景。通过这种结构化的方式,可以清晰地理解Set类型在Redis中如何用于处理无序且元素唯一的数据集合。
Zset类型详解
定义
Zset(Sorted Set)类型在Redis中是一个有序集合,它与Set类型类似,也是由不重复的元素组成。不同之处在于,Zset中的每个元素都关联了一个分数(Score),这个分数用于对集合中的元素进行排序。
特点
-
有序性:元素根据分数从小到大进行排序。
-
元素唯一:集合中的元素不能重复,但分数可以相同。
-
灵活的分数:分数可以是整数或浮点数,提供了排序的灵活性。
应用场景
-
排行榜:Zset可以用来实现各种排行榜,如游戏得分、文章点赞数等。元素可以是用户ID或文章ID,分数可以是得分或点赞数。
-
范围查询:由于Zset是有序的,它可以高效地进行范围查询,如查询得分在一定范围内的用户。
内部实现
Zset在Redis内部通常使用两个数据结构来实现:
-
跳跃表(Skip List):提供快速的元素查找和有序遍历。
-
哈希表:快速地通过元素定位到其分数,并进行插入和删除操作。
Mermaid图示
以下是Zset类型的应用场景的Mermaid图示:
 这个图展示了Zset类型的定义、特点、应用场景以及内部实现方式。通过这种结构化的方式,可以清晰地理解Zset类型在Redis中如何用于实现有序数据集合及其高效应用。
这个图展示了Zset类型的定义、特点、应用场景以及内部实现方式。通过这种结构化的方式,可以清晰地理解Zset类型在Redis中如何用于实现有序数据集合及其高效应用。
扩展数据类型详解
Redis的扩展数据类型提供了一些特殊的数据结构,用于解决特定的问题,它们在Redis 3.2及以上版本中提供。
BitMap
-
定义:BitMap 是一种位图结构,使用单个字符串值来表示大量独立的布尔字段。
-
应用场景:
-
状态跟踪:例如,用户是否在线、商品是否售罄。
-
稀疏数据集:存储大量二进制数据,如用户行为标记。
-
HyperLogLog
-
定义:HyperLogLog 是一种概率数据结构,用于估算集合中不同元素的数量。
-
应用场景:
-
基数统计:例如,网站访问的独立用户数,无需存储所有用户数据。
-
GEO
-
定义:GEO 是一种用于存储地理位置信息的数据结构。
-
应用场景:
-
地理查询:如查找给定位置附近的商店或用户。
-
Stream
-
定义:Stream 是一种用于消息队列的数据结构,支持消费者组和消息持久化。
-
应用场景:
-
消息队列:实现应用之间的异步消息传递。
-
消费者组:允许多个消费者实例共享消息流。
-
Mermaid图示
以下是Redis扩展数据类型的Mermaid图示:
 这个图展示了Redis的四种扩展数据类型及其定义和主要应用场景。通过这种结构化的方式,可以清晰地理解每种数据类型在Redis中的作用和优势。
这个图展示了Redis的四种扩展数据类型及其定义和主要应用场景。通过这种结构化的方式,可以清晰地理解每种数据类型在Redis中的作用和优势。
Redis性能优化策略
Redis的性能优化是一个多方面的过程,涉及到数据类型的选择、命令的使用,以及对大数据量操作的处理。以下是一些关键的性能优化策略:
选择合适的数据类型和命令
-
数据类型选择:根据数据的使用场景选择最合适的数据类型。
-
对于简单的计数,使用String类型。
-
对于需要排序的元素集合,使用List或Zset。
-
对于需要唯一性保证的数据,使用Set。
-
对于需要存储对象属性,使用Hash。
-
-
命令选择:选择能够最有效执行操作的命令。
-
使用
MSET和MGET批量设置和获取Hash字段。 -
使用
LPUSH和RPOP或BRPOPLPUSH进行消息队列操作。
-
-
避免阻塞操作:使用BLPOP、BRPOP等命令,避免长时间阻塞等待。
避免在大数据量下进行复杂的集合操作
-
减少复杂操作:在大数据集上执行如SINTER、SUNION等复杂操作可能会影响性能。
-
考虑使用分片或分区技术将数据分散到不同的Redis实例。
-
-
使用辅助索引:在需要频繁进行范围查询或排序的场景中,使用额外的数据结构或索引来优化查询。
-
内存管理:合理配置内存淘汰策略,如LRU(最近最少使用)等,以避免内存溢出。
-
异步处理:对于耗时的数据处理,考虑使用Redis的持久化功能或将数据异步写入磁盘。
-
监控和调优:使用Redis的监控工具,如
redis-cli --stat或redis-cli --info,定期检查性能指标,并根据需要进行调优。
Mermaid图示
以下是Redis性能优化策略的Mermaid图示:
 这个图展示了Redis性能优化的关键策略,包括数据类型和命令的选择,以及如何在大数据量下避免性能瓶颈。通过这些策略,可以确保Redis实例的高效运行。
这个图展示了Redis性能优化的关键策略,包括数据类型和命令的选择,以及如何在大数据量下避免性能瓶颈。通过这些策略,可以确保Redis实例的高效运行。





![[每周一更]-(第110期):QT开发最佳实战(php/go/python/javascript)](https://i-blog.csdnimg.cn/direct/64659e0b14b640cb847a1bdc2769b22e.jpeg#pic_center)