一、预准备:过滤器设置
打开fiddler后,清空内容,然后播放视频。
找到与B站视频资源相关的回应,而后在“原始(raw)”标签中查看它的host信息。
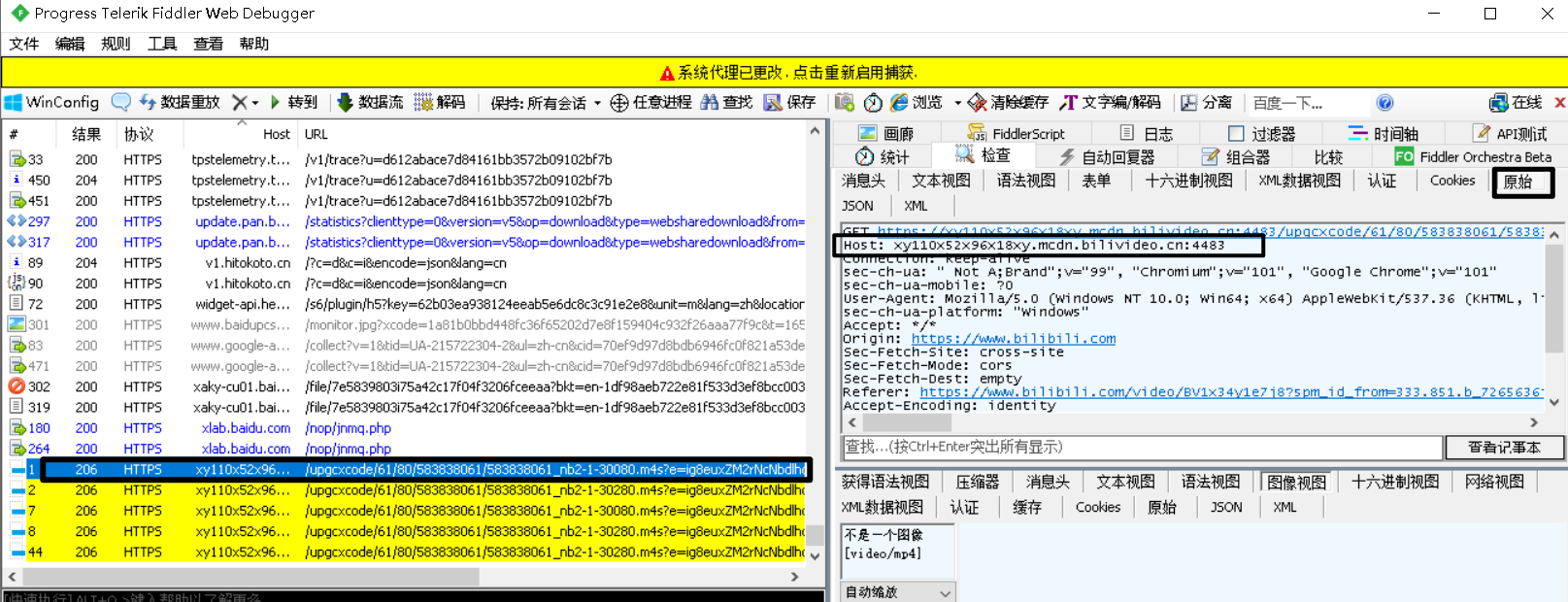
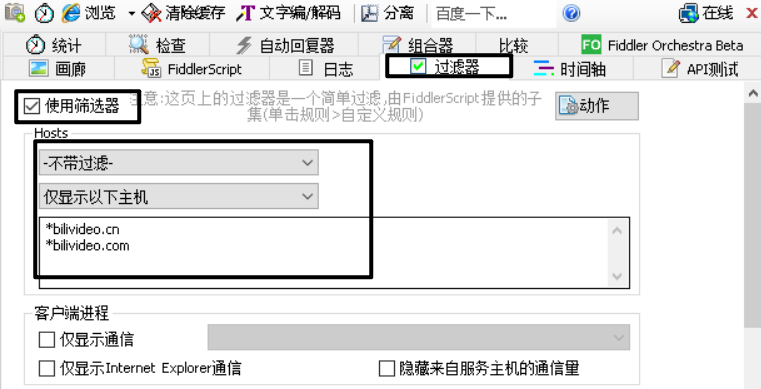
发现B站视频资源的服务器DNS地址为【*bilivideo.cn】、【*bilivideo.com】。
激活过滤器,并且只过滤B站视频资源。
二、正式抓取:随便抓取一个B站视频
再次清空所有抓取到的会话。
重新播放视频,得到新的一批会话后,发现存在m4s的资源已被下载,停止捕获。


将其最小sizes改成0,然后点击执行 。
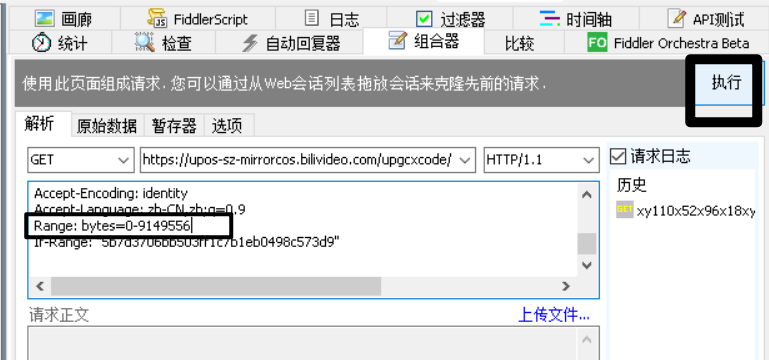
会话窗口新增了一个会话,下载完后;右键——保存——响应——响应正文。

默认给的名称后缀是.txt。

直接不改名,保存。
打开后,发现是乱码,说明这玩意不是字幕文件;建议的txt后缀是错误的。

同样地,把30080号码对应的会话拖拽进组合器,然后修改最小sizes为0,执行。
这个响应会话的最大sizes是63699963 bytes,对应63MB。估计这个就是视频图像文件。

同样地,保存操作。

建议以m4s后缀保存。
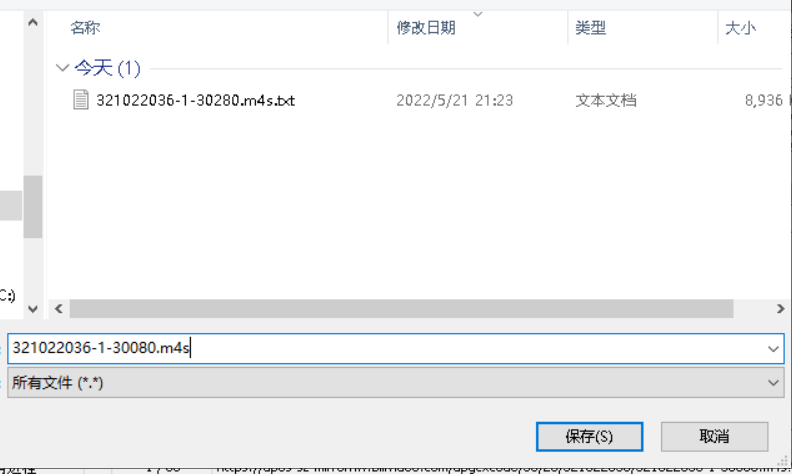
然后我修改成Mp4后缀后,打开发现没有声音。
最后,我又对一个30064号码会话进行同样的操作,保存了一个40mb的文件。
改成mp4后缀后,打开发现是分辨率小于30080号码对应的视频图像文件。
说明这个号码,只是视频图像文件的低分辨率版本而已。
最后再对号码30280的文件后缀改成mp3,打开播放发现正是视频的音频部分。
那么,此时此刻我已经得到了3个文件——低分辨率和高分辨率的视频图像部分,以及视频的声音部分。
三、利用ffmpeg进行多媒体文件的拼接
在cmd窗口中执行命令。
ffmpeg -i 321022036-1-30080.m4s.mp4 -i 321022036-1-30280.m4s.mp3 -c copy 456.mp4
而后在同一文件夹中得到了456.mp4文件,打开后,就是B站视频的源文件。






![[C++] STL (multi)map/(multi)set简介](https://i-blog.csdnimg.cn/direct/64f2570484cb4a368d691a2c57293183.png)