1.概念介绍
目标检测不仅可以检测数字,而且可以检测动物的种类、汽车的种类等。例如,自动驾驶车辆需要自动识别前方物体是车辆还是行人,需要自动识别道路两 旁的指示牌和前方的红绿灯颜色。对于自动检测的算法,有两个要求,一个是快, 一个是准。VOC是一个挑战赛,主要目的是识别真实场 景中的一系列物体。交并比是交集与并集的比例。假设需要检测到其中“0”的位置。白色方框是人工标注的标准答案,也是想要预测的理想位置。 灰色方框是预测的实际位置。通过IoU 计算,利用两个框的交集面积与并集面积的比值就可以衡量模型预测的灰框是否准确。

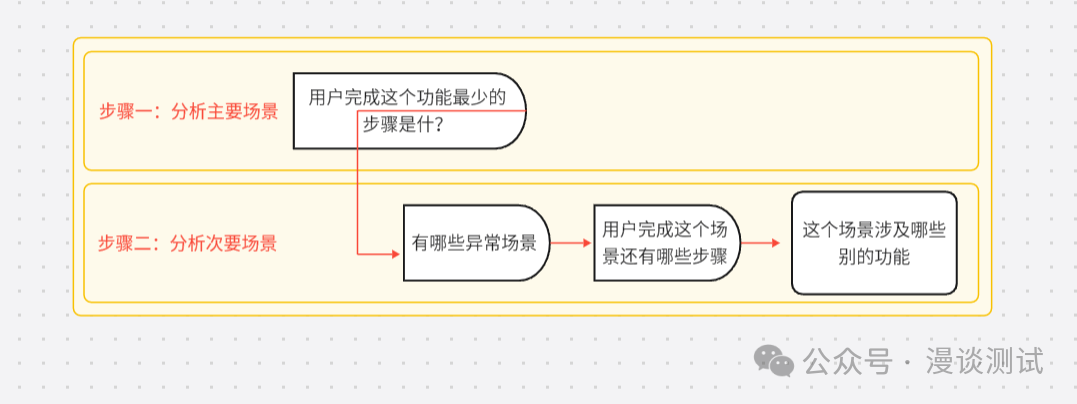
平均精度均值(mAP)衡量一个目标检测模型整体效果的指标。对于图像分类模型,整个流程就是根据损失函数来反向传播更新深度卷积网络中各个卷积核的参数,而所需要的数据集就是图片数据和图片标签。其实对于YOLOv1这样的 一步走模型,整个流程大体差不多,所以需要研究的有4个方面:输入、网络、输 出、损失函数。
输出:YOLO v1模型速度之所以快是因为它的候选框的数量并不多。首先,把一个输入图片分成S×S 的格子,然后以每个格子为中心,预测出来B 个候选框(Bounding Boxes),每个候选框包含5个预测值,其中4个表示位置信息,1个表示置信度。
注意:如果两个物体的中心点在同一个cell内,则会失去一个物体的预测。因为同一个cell最终只能给出一个有效候选框,而一个有效候选框无法预测两个不同的物体。
对图像的一些处理,包括随机剪裁、随机调整尺寸、随机调整光亮、随机调整饱和度、随机平移等,都是图像增强的方法。
TP、TN、FP、 FN。TP是真实的正样本,即预测是正样本,而且预测对了,真的是正样 本 ;TN 是预测是负样本,预测对了,真的是负样本;FP 是错误的正样本,预测是正样本,但 是错了,其实不是正样本;FN 是预测是负样本,预测错了,其实是正样本。先计算每个预测框与真实框的IoU, 如果IoU 大于0.5,这个预测框就是真的正样本, 则认为该预测框成功地检测出了目标;如果小于0.5,那么这个预测框就没有找到目标。
接下来考虑置信度。要给置信度增加一个阈值,然后只考虑置信度在阈值之上的预测 框。继续看上面的例子。假设阈值是0.9,那就忽视所有阈值小于0.9的预测框。AP 是对某一个类检测的好坏,mAP 是所有类的AP 的平均值。
归一化(Batch Normalization)。Batch Normalization可以提升 模型的收敛速度,也可以起到轻微的正则化的效果,降低模型过拟合。改进是高精度的分类器(High Resolution Classifier)
改进是先验框(Prior Anchor),改进是聚类(Dimension Cluster) ,改进是细粒度特征,改进是多尺度训练。