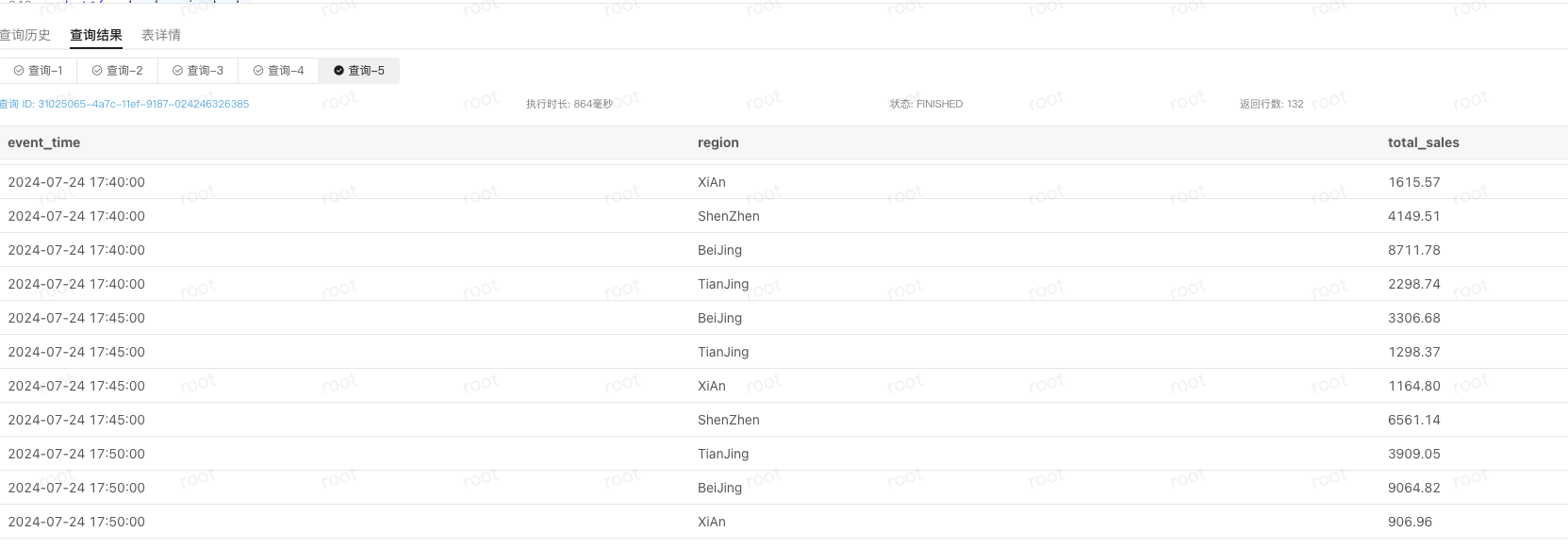
在 SQLAlchemy 中使用 GroupBy 和 Sum 时,有时会遇到重复计数或意外的查询结果。这通常是因为在聚合查询中没有正确地指定聚合函数或 GroupBy 条件,导致结果集没有按预期方式分组。

1、问题背景
在使用 SQLAlchemy 进行数据查询时,用户在尝试对表中的几个字段进行分组并对各组进行求和时遇到问题。然而,在实际查询结果中,求和结果被重复计数,导致不正确的数据。
2、解决方案
为了解决这个问题,需要对查询语句进行调整。具体来说,原始的查询语句中存在一些问题:
- 在对 Expense 表进行分组时,同时选择了 Expense 对象,这没有意义。
- CostCenter 和 Expense 表之间缺少连接条件,导致行被重复,每个成本中心都进行计数,但没有关系。
因此,需要将查询语句修改为如下形式:
session.query(
Expense.date,
func.sum(Expense.value).label('total')
).join(Expense.cost_center
).filter(CostCenter.id.in_([2, 3])
).group_by(Expense.date
).all()
修改后的查询语句具有以下特点:
- 只选择 Expense.date 和求和结果 total,避免了重复选择 Expense 对象。
- 使用 join() 方法连接 CostCenter 和 Expense 表,确保只对相关行进行分组和求和。
- 使用 filter() 方法过滤出符合条件的 CostCenter,指定了要考虑的成本中心 ID。
- 使用 group_by() 方法对 Expense.date 进行分组,以便对每组进行求和。
通过这些修改,可以正确地对数据进行分组和求和,避免了重复计数的问题。
代码示例
以下是一个简单的可运行示例,演示了如何使用修改后的查询语句进行数据分组和求和:
from datetime import datetime
from sqlalchemy import create_engine, Column, Integer, ForeignKey, Numeric, DateTime, func
from sqlalchemy.orm import Session, relationship
from sqlalchemy.ext.declarative import declarative_base
# 创建引擎和会话
engine = create_engine('sqlite://', echo=True)
session = Session(bind=engine)
# 定义表结构
Base = declarative_base(bind=engine)
class CostCenter(Base):
__tablename__ = 'cost_center'
id = Column(Integer, primary_key=True)
class Expense(Base):
__tablename__ = 'expense'
id = Column(Integer, primary_key=True)
cost_center_id = Column(Integer, ForeignKey(CostCenter.id), nullable=False)
value = Column(Numeric(8, 2), nullable=False, default=0)
date = Column(DateTime, nullable=False)
cost_center = relationship(CostCenter, backref='expenses')
# 创建表
Base.metadata.create_all()
# 添加数据
session.add_all([
CostCenter(expenses=[
Expense(value=10, date=datetime(2014, 8, 1)),
Expense(value=20, date=datetime(2014, 8, 1)),
Expense(value=15, date=datetime(2014, 9, 1)),
]),
CostCenter(expenses=[
Expense(value=45, date=datetime(2014, 8, 1)),
Expense(value=40, date=datetime(2014, 9, 1)),
Expense(value=40, date=datetime(2014, 9, 1)),
]),
CostCenter(expenses=[
Expense(value=42, date=datetime(2014, 7, 1)),
]),
])
# 执行查询
base_query = session.query(
Expense.date,
func.sum(Expense.value).label('total')
).join(Expense.cost_center
).group_by(Expense.date)
# 第一次查询,考虑成本中心 1
for row in base_query.filter(CostCenter.id.in_([1])).all():
print('{}: {}'.format(row.date.date(), row.total))
# 第二次查询,考虑成本中心 1、2 和 3
for row in base_query.filter(CostCenter.id.in_([1, 2, 3])).all():
print('{}: {}'.format(row.date.date(), row.total))
在执行查询后,它将按日期对数据进行分组并求和,并显示每个组的日期和总和。这样,可以正确地获取数据分组和求和的结果,避免重复计数的问题。
在使用 SQLAlchemy 的 GroupBy 和 Sum 时,可能会遇到重复计数的问题。通常,这是由于没有正确处理聚合逻辑或缺乏对 SQL 查询的深入理解。通过正确使用聚合函数,并在需要时检查生成的 SQL 语句,可以避免这些问题,确保查询结果的准确性。