StarRocks Lakehouse 快速入门指南为您提供了湖仓技术概览,旨在帮助您迅速掌握其核心特性、独特优势和应用场景。本指南将指导您如何高效地利用 StarRocks 构建解决方案。文章末尾,我们集合了来自阿里云、饿了么、喜马拉雅和同程旅行等行业领导者在 StarRocks x Paimon Streaming Lakehouse 活动中的实战经验分享。通过这些真实案例,您可以更直观地了解如何在实际应用中发挥 StarRocks Lakehouse 的最佳效用。希望这些实践能启发您在自己的项目中应用 StarRocks Lakehouse,发掘其潜力,实现数据价值最大化。
Apache Paimon 介绍
Apache Paimon (后简称 Paimon)起源于 Apache Flink (后简称 Flink)的一个子项目,起初它只是 Flink 内置的 Table Store 的一个格式,经过了几年的发展后,在 2024 年成功从 Apache 软件基金会(ASF)孵化器毕业,成为正式的顶级项目。Paimon 围绕具有 ACID 特性的数据湖存储构建,支持 DML 操作, 可以完整地支持批处理和流处理。它创新性地将 LSM Tree 与湖格式相结合,具有高效的实时更新能力与 compaction 效率。
Paimon 架构与关键特性
架构设计
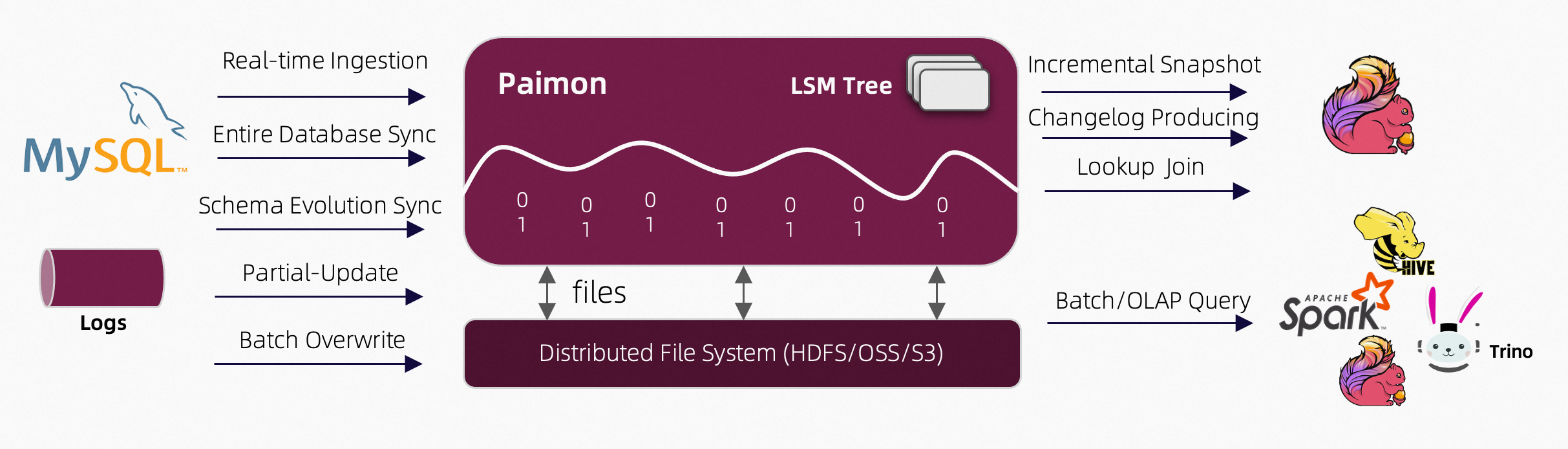
关键特性
Apache Paimon 是一个高性能的数据湖存储系统,旨在支持批处理和流处理。其主要特点包括:
-
统一的批处理和流处理 :Paimon 提供了一个单一的数据存储格式,可用于批处理和流处理,确保在不同处理范式之间实现无缝的数据分析。
-
Schema Evolution :允许在不需要完全重写数据的情况下进行数据模式的变化,这对于处理不断变化的数据需求至关重要。
-
ACID 事务 :Paimon 通过提供 ACID(原子性、一致性、隔离性、持久性)事务,确保数据的一致性和可靠性,这对于在复杂数据处理流水线中维护数据完整性至关重要。
-
Time Travel :允许用户访问数据的历史版本,方便进行数据审计、调试和历史分析。
-
与大数据生态系统的集成 :Paimon 无缝集成了流行的大数据处理框架,如 Apache Flink、Apache Spark 和 Apache Hive,便于采用和互操作性。
Apache Paimon 的优势
Paimon 的优势主要在以下四大方面:
-
高效的实时更新 :Paimon 提供了灵活的实时数据流更新能力,支持最低一分钟内的数据时效性。它能够处理部分列更新、聚合更新,并生成变更日志,为下游系统提供实时数据流。
-
优化的流写流读 :作为源自 Flink 内置格式的系统,Paimon 与 Flink 高度兼容,支持高效的流式读写操作。同时,Paimon 也与 Spark 紧密集成,成为 Spark 批处理计算的理想选择。
-
强大的查询性能 :Paimon 支持高效的 OLAP 查询,具备点查能力和丰富的索引功能。社区正积极推进索引技术的发展,如 bitmap 索引和布隆过滤器,以进一步提升查询效率。
-
大规模的离线处理 :Paimon 能够处理大规模的离线数据集,并对 Append 表提供全面支持,满足超大规模数据处理的需求。
Paimon 使用场景
-
数据湖存储:作为数据湖的存储底座,管理各类数据,包括结构化、半结构化和非结构化数据。
-
实时数据处理:将实时数据摄入到数据湖中,支持实时数据的写入、更新和查询,构建实时数据仓库,满足实时性业务需求,例如实时监控、实时报表等。
-
数据库入湖:提升 ods 层时效性,替代基于传统方式(如 Hive 实时同步、凌晨合并等)的数据入库。
-
构建下游数据层:利用湖的增量能力构建下游的 dwd 层,节省计算资源。
-
局部更新:支持局部数据的更新,适用于需要频繁更新部分数据的场景,例如构建实时统计视图和报表、宽表构建等。
-
流读/增量读:通过增量流读的方式读取数据,支持实时数仓的建设,极大地缩减数据可见时间,提升数据的实时性,同时降低底层数仓的压力。
Pamion 表模型
Primary Key
主键表,可以支持新增、更新和删除表中的数据。如果将多条具有相同主键的数据写入 Paimon 主键表,将根据数据合并机制对数据进行合并。主键表适用于需要进行数据更新和删除操作,并且对数据一致性要求较高的场景。
Append Table
如果表没有定义主键,默认情况下它就是一个Append Table,其实可以理解为StarRocks中的明细表,写入多条一样的数据不会覆盖,会保留多条。这种类型的表适用于不需要流式更新的用例(如日志数据同步)。
Append Queue
其实可以把Append Queue看作是一种特殊的Append Table。同一个桶中的每条记录都是严格排序的,流式读取会完全按照写入的顺序将记录传输到下游。有点类似kafka中的partition,单分区内严格有序。应用在数据管道场景、状态最综合监控场景、时间流处理场景和金融交易场景。
Time Travel
基于快照文件(snapshot)实现。消费者可以通过不同的快照文件,查询在该快照文件产生时刻的Paimon表中的具体数据。
Compaction 策略
Paimon 目前采用的 compaction 策略类似于 RocksDB 的 universal compaction。默认有两种策略:
-
leveled compaction,RocksDB 的默认 compaction 策略
-
Size tiered
这里跟 StarRocks 目前采用的 compaction 比较类似,都是 Size Tiered Compaction。基本的思路就是尽可能让数据量相近的 rowset 执行 compaction,从而避免 compaction 带来的写放大。
StarRocks x Paimon 极速湖仓分析
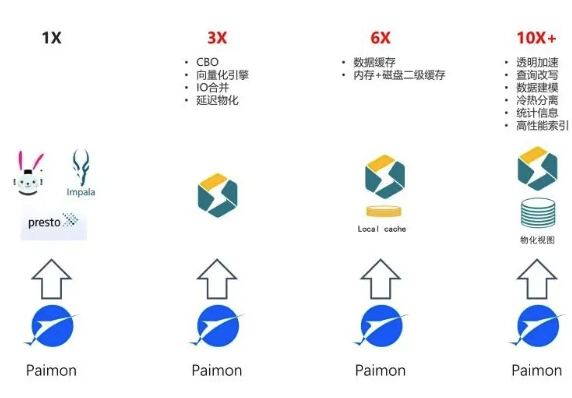
当前 StarRocks x Paimon 的能力主要包括:
-
支持各类存储系统,包括 HDFS 以及对象存储 S3/OSS/OSS-HDFS
-
支持 HMS 以及阿里云 DLF 元数据管理系统
-
支持 Paimon 的 Primary Key 和 Append Only 表类型查询
-
支持 Paimon 系统表的查询,常见例如 Read Optimized 表,snapshots 表等
-
支持 Paimon 表和其他类型数据湖格式的关联查询
-
支持 Paimon 表和 StarRocks 内表的关联查询
-
支持 Data Cache 加速查询
-
支持基于 Paimon 表构建物化视图实现透明加速,查询改写等
-
支持Paimon表开启Delete Vector加速查询
对于 Primary Key 表类型,Paimon 社区对 Read Optimized 系统表做了完善的性能优化,可以与 Append Only 表一样充分利用 Native reader 的能力,得到直接查询 Paimon数据的最佳性能。直接查询 Primary Key 表的情况下,若 Primary Key 表里包含没有做 Compaction 的数据,StarRocks 里会通过 JNI 调用 Java 读取这部分内容,性能会有一定的损耗。即使是这种情况,在我们收到用户反馈里,平均还是会有相对 Trino 达到3倍以上的性能提升。
Quick Start
Pamion 部署
使用的组件版本
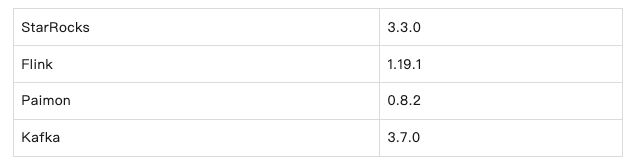
下载 Flink
以下链接是阿里云机器加速的域名,如果是非阿里云机器,可替换为https://mirrors.aliyun.com
wget "http://mirrors.cloud.aliyuncs.com/apache/flink/flink-1.19.1/flink-1.19.1-bin-scala_2.12.tgz"
解压
tar -xf flink-1.19.1-bin-scala_2.12.tgz
下载 Paimon 和相关依赖包
wget "https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-flink-1.19/0.8.2/paimon-flink-1.19-0.8.2.jar"
#如果使用对象存储,需要下载下面的包
wget "https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-oss/0.8.2/paimon-oss-0.8.2.jar"
下载 flink-hadoop 依赖包
wget "https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar"
如果没有如上 jar 包会报错
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
下载 flink-sql-connector-kafka 依赖包
wget "https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka/3.2.0-1.18/flink-sql-connector-kafka-3.2.0-1.18.jar"
下载 flink-connector-starrocks 依赖包
wget "https://github.com/StarRocks/starrocks-connector-for-apache-flink/releases/download/v1.2.9/flink-connector-starrocks-1.2.9_flink-1.18.jar"
拷贝上面下载的包到 flink/lib 下
cp paimon-flink-1.19-0.8.2.jar paimon-oss-0.8.2.jar flink-shaded-hadoop-2-uber-2.7.5-10.0.jar flink-connector-starrocks-1.2.9_flink-1.18.jar flink-sql-connector-kafka-3.2.0-1.18.jar flink-1.19.1/lib/
启动 flink 集群
cd flink-1.19.1
#修改flink-1.19.1/conf/config.yaml中numberOfTaskSlots为10,允许同时执行的任务
numberOfTaskSlots: 10
./bin/start-cluster.sh
Kafka 部署
下载安装包
以下链接是阿里云机器加速的域名,如果是非阿里云机器,可替换为https://mirrors.aliyun.com
wget "http://mirrors.cloud.aliyuncs.com/apache/kafka/3.7.0/kafka_2.12-3.7.0.tgz"
解压
tar -xf kafka_2.12-3.7.0.tgz
启动 kafka
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
./bin/kafka-server-start.sh -daemon ./config/server.properties
测试 Demo
本文测试的场景,订单数据来源于 Kafka,用户数据来源于 MySQL,最终实现在 Paimon 中存储5分钟时间窗口的汇总结果。 这里为了简化测试demo,下文中用StarRocks替代了MySQL。
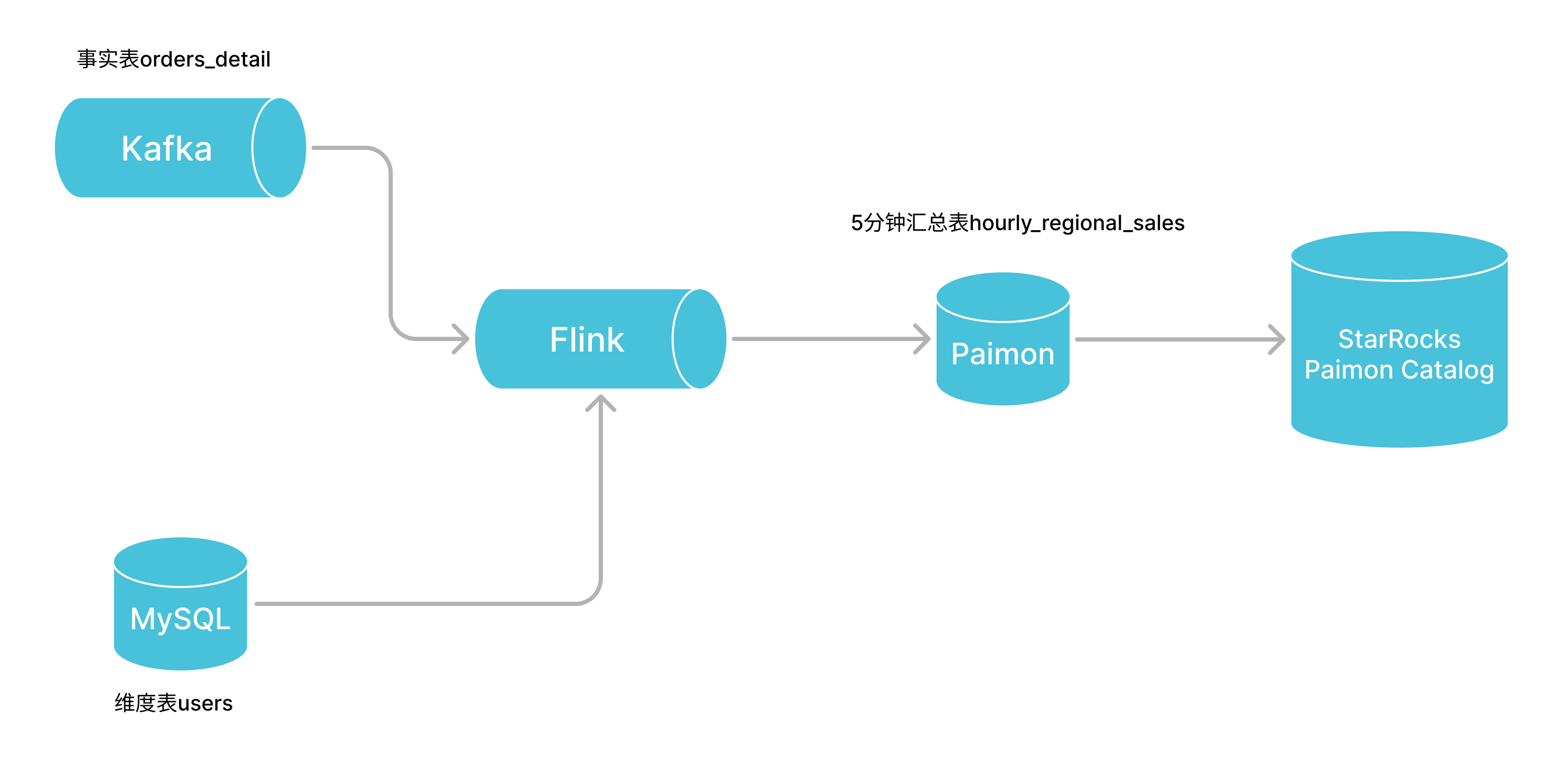
创建维度表并写入测试数据
CREATE TABLE `users` (
`user_id` bigint(20) NOT NULL COMMENT "",
`region` varchar(65533) NULL COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`);
insert into users values (1,'BeiJing'),(2,'TianJin'),(3,'XiAn'),(4,'ShenZhen'),(5,'BeiJing'),(6,'BeiJing'),(7,'ShenZhen'),(8,'ShenZhen');
Kafka 中创建事实表并写入测试数据
./bin/kafka-topics.sh --create --topic order-details --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
测试数据生成
需要 pip install kafka
from kafka import KafkaProducer
import time
import json
import random
from datetime import datetime, timedelta
start_time = datetime(2024, 7, 24, 15, 0, 0)
end_time = datetime(2024, 7, 24, 18, 0, 0)
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
while True:
order_id = random.randint(1, 10000)
user_id = random.randint(1, 8)
order_amount = round(random.uniform(10.0, 1000.0), 2)
random_time = start_time + timedelta(seconds=random.randint(0, 3600))
data = {
"order_id": order_id,
"user_id": user_id,
"order_amount": order_amount,
"order_time": random_time.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]
}
producer.send('order-details', value=json.dumps(data).encode('utf-8'))
time.sleep(3)
producer.close()
创建 paimon 表并写入测试数据
./bin/sql-client.sh
CREATE CATALOG my_catalog_oss WITH (
'type' = 'paimon',
'warehouse' = 'oss://starrocks-public/dba/jingdan/paimon',
'fs.oss.endpoint' = 'oss-cn-zhangjiakou-internal.aliyuncs.com',
'fs.oss.accessKeyId' = 'ak',
'fs.oss.accessKeySecret' = 'sk'
);
use catalog my_catalog_oss;
CREATE TABLE hourly_regional_sales (
event_time TIMESTAMP(3),
region STRING,
total_sales DECIMAL(10, 2)
);
use catalog default_catalog;
CREATE TABLE orders_kafka (
order_id BIGINT,
user_id BIGINT,
order_amount DECIMAL(10, 2),
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order-details',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'order-consumer ',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
CREATE TABLE users_starrocks (
user_id BIGINT,
region STRING
) WITH (
'connector'='starrocks',
'scan-url'='172.26.92.154:8030',
'jdbc-url'='jdbc:mysql://172.26.92.154:9030',
'username'='root',
'password'='xxx',
'database-name'='jd',
'table-name'='users'
);
SET 'execution.checkpointing.interval' = '10 s';
INSERT INTO my_catalog_oss.`default`.hourly_regional_sales
SELECT
TUMBLE_START(order_time, INTERVAL '5' MINUTE) AS event_time,
u.region,
CAST(SUM(o.order_amount) AS DECIMAL(10, 2)) AS total_sales
FROM default_catalog.`default_database`.orders_kafka AS o
JOIN default_catalog.`default_database`.users_starrocks AS u ON o.user_id = u.user_id
GROUP BY TUMBLE(order_time, INTERVAL '5' MINUTE), u.region;
查询数据
select * from my_catalog_oss.`default`.hourly_regional_sale;
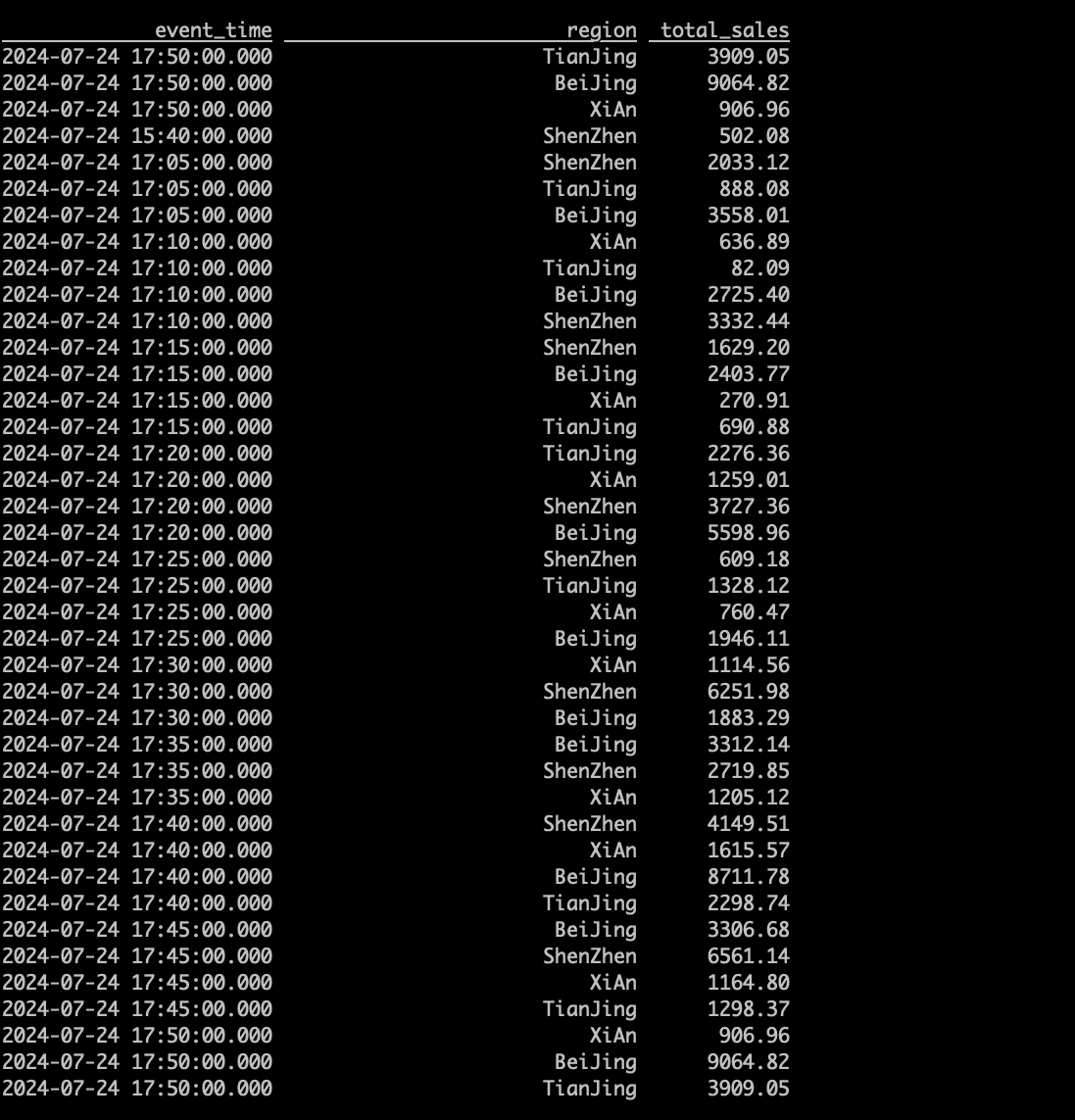
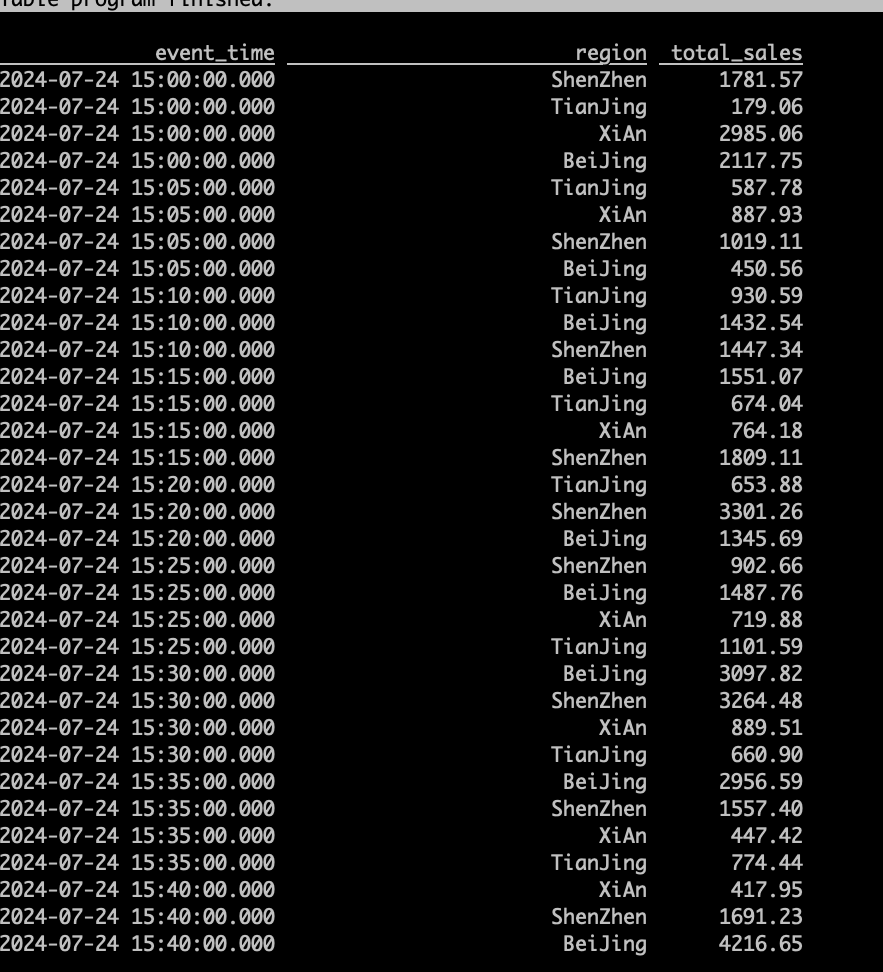
查询增量数据(Batch Time Travel)
SET 'execution.runtime-mode' = 'batch';
SELECT * FROM hourly_regional_sales /*+ OPTIONS('scan.snapshot-id' = '2') */;

SET 'execution.runtime-mode' = 'batch';
SELECT * FROM hourly_regional_sales /*+ OPTIONS('incremental-between' = '5,10') */;
创建 StarRocks Paimon Catalog
CREATE EXTERNAL CATALOG paimon_catalog_oss
PROPERTIES
(
"type" = "paimon",
"paimon.catalog.type" = "filesystem",
"paimon.catalog.warehouse" = "oss://starrocks-public/dba/jingdan/paimon",
"aliyun.oss.access_key" = "ak",
"aliyun.oss.secret_key" = "sk",
"aliyun.oss.endpoint" = "oss-cn-zhangjiakou-internal.aliyuncs.com"
);
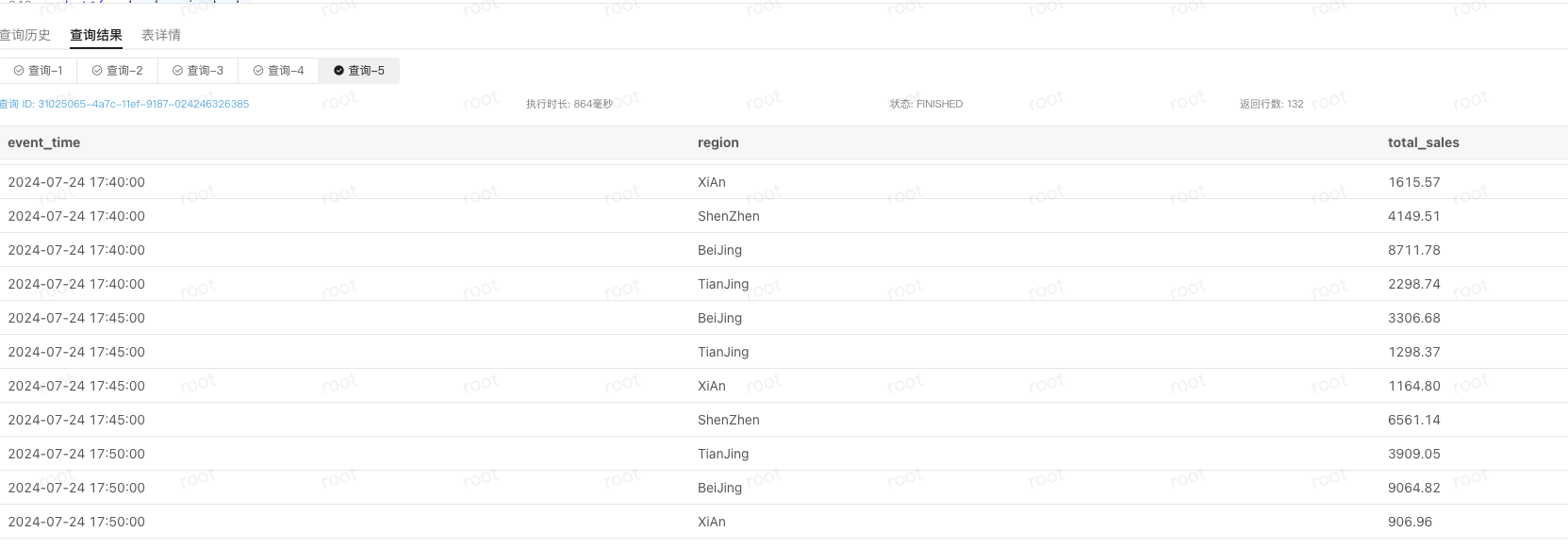
set catalog paimon_catalog_oss;
use `default`;
select * from hourly_regional_sales;
StarRocks 侧可以实时的看到汇总表的变化
用户案例:
Paimon+StarRocks 在同程旅行的湖仓构建方案
饿了么基于 Paimon+StarRocks 的实时湖仓探索
喜马拉雅基于 Paimon+StarRocks 构建直播实时湖仓
使用 StarRocks x Paimon 创建 Streaming Lakehouse
延伸阅读:
StarRocks x Paimon 构建极速实时湖仓分析架构实践
Paimon+StarRocks 湖仓一体数据分析方案
参考:
https://paimon.apache.org/docs/0.8/flink/quick-start/
https://github.com/facebook/rocksdb/wiki/Universal-Compaction
https://mp.weixin.qq.com/s/7n8787v8oVyn5RHoGwgszQ
https://mp.weixin.qq.com/s/Gh5rrtU4BxsDYvgvbwrR5A
https://mp.weixin.qq.com/s/PiyZgI7DYgAtLh17xlbz8A
更多交流,联系我们:StarRocks