mysql索引为什么选择B+树?
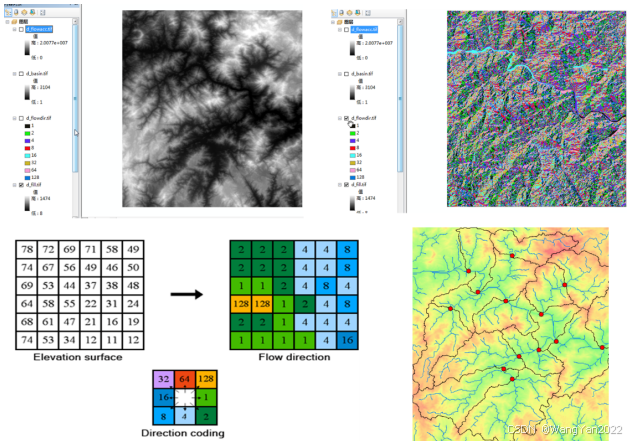
在回答这个问题之前,得先了解一个概念,页的概念。页是InnoDB中数据管理的最小单位。当我们查询数据时,其是以页为单位,将磁盘中的数据加载到缓冲池中的。同理,更新数据也是以页为单位,将我们对数据的修改刷回磁盘。每个数据页16kb,一个数据页大约16k,也就是说一个数据区可以包含64个连续的数据页。
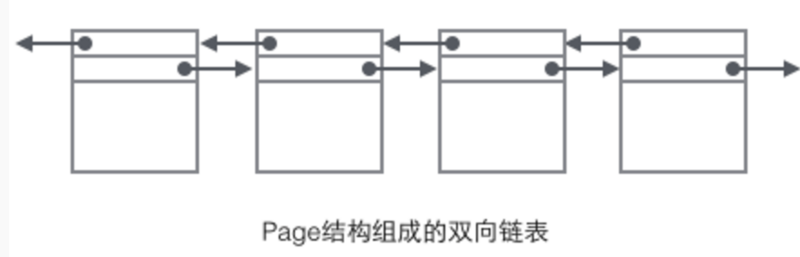
页头部保存了两个指针,分别指向前一个页和后一个页,头部还有页的类型信息和用来唯一标识页的编号。根据这个指针分布可以想象到页链接起来就是一个双向链表。
有了这个概念,我们看一下,如果选择B树,会是什么个情况。
B树有两个特点,和二叉树相比,B树每个节点有更多的子节点,B树每个节点上不仅有索引信息,还存放了数据。
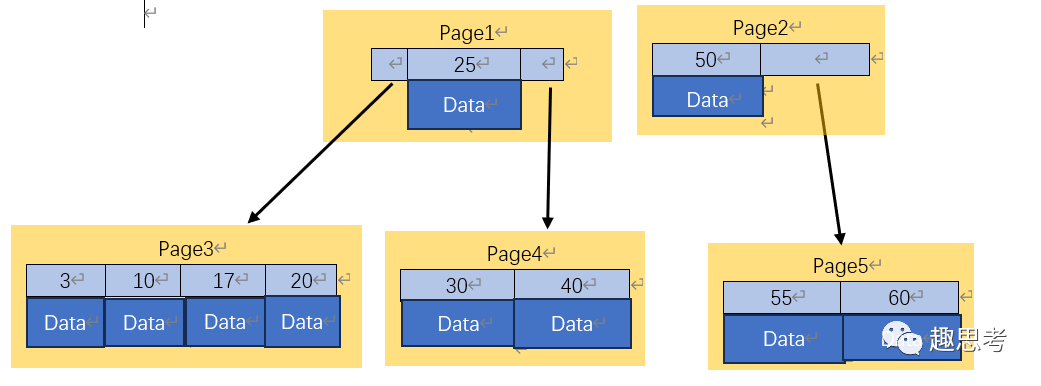
简化B树
B+树和B树相比,有一点是一样的,每个节点有更多的子节点,那他们不同点在哪里呢?B+树内部节点不存储数据,所有的数据都存储在叶子节点。第二点,为所有叶子节点增加了一个链指针。
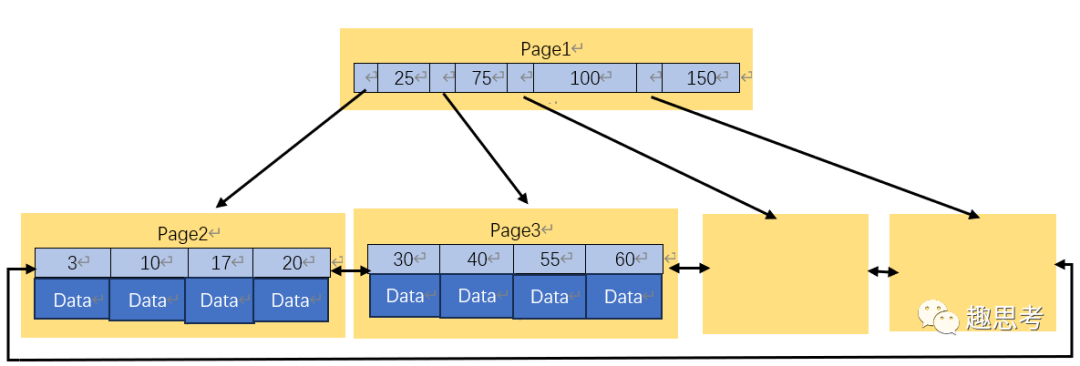
简化B+树
那么,B树和B+树的差异,会引起什么问题呢?我们来做一个思维实验,假设每次内存从磁盘中只加载一页,实际上不是,会加载很多页,我们为了方便问题讨论,便假设只加载一页。有一个查询语句,需要查询范围30到60之间的数据。对于B树,由于内部节点上存了数据信息,导致一页上索引元素相对就少了很多,第一次搜索到Page1,据此,可以定位到Page4,30到50之间的数据就可以拿到了,这个时候需要进行一次中序遍历,先回到Page4的根节点,再执行一次中序遍历返回到Page1和Page2的根节点,最终搜索到Page2,由此定位到Page5,获取50到60之间的数据,由此,可见,为了获取这个范围内的数据,需要多了几次遍历查找。那么,如果选择B+树,由于内部节点不存储数据,只存储索引信息,因此,一页可以包含更多的索引信息,因此,查询的时候,定位到Page1的数据,根据索引信息,可以查询到Page3,一次拉取,即可实现30到60之间的数据查询。
众所周知,索引的功能和新华字典的目录的功能是一样的,根据字母粗定位一个汉字大概在哪些页。B+树内部节点就像现在新华字典的目录一样,不包含数据,只有索引信息,因此,一页目录上包含了更多的索引信息,可以减少翻页的次数。而B树把数据和索引信息放到了一起,这个效果就像新华字典的目录中不仅有索引信息,还有具体的汉字信息,那么一页能展示的信息就很少了,需要翻页更多次才能实现定位,效率就低下了。
B+树另外一个特点,为所有叶子节点增加了一个链指针。根据空间局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问。而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快。比如,我们访问key为20的数据,那么key为30,40,55,50的数据也被加载进内存,这样可以减少内存和磁盘之间的交互。
基于,以上两点,所以选择了B+树索引。