1、创建conda环境
conda create -n TTS python=3.10
conda activate TTS
2、拉取源代码
# 从 GitHub 下载代码
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
拉取模型文件
git clone https://www.modelscope.cn/pzc163/chatTTS.git ChatTTS-Model
3、安装环境依赖
在开始之前,请确保已安装必要的包,如果您尚未安装它们,可以使用 pip 进行安装。
注意:修改requirements.txt文件的torch版本为2.2.2后再次执行安装。直接安装requirements.txt依赖版本,在运行程序时会报错,经过多次验证后发现torch==2.2.2可以。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
依赖包列表requirements.txt文件如下:
numpy==1.26.0
numba
torch==2.2.2
torchaudio
tqdm
vector_quantize_pytorch
transformers>=4.41.1
vocos
IPython
gradio
pybase16384
av
pydub
4、启动WebUI
python examples/web/webui.py --server_name 0.0.0.0 --server_port 8080
执行后会先下载模型文件,共有7个pt文件,如果网络不好可能会有个别下载失败,再次执行上述指令即可,会跳过已经下载好的模型文件,继续下载未成功下载的文件,直到所有模型文件下载完成后,会自动跳转出webui,地址为http://localhost:8080/。
5、WebUI推理
运行界面如下所示,其中有很多可设置的参数,这些都在examples/web/webui.py示例脚本中可以自行设置。
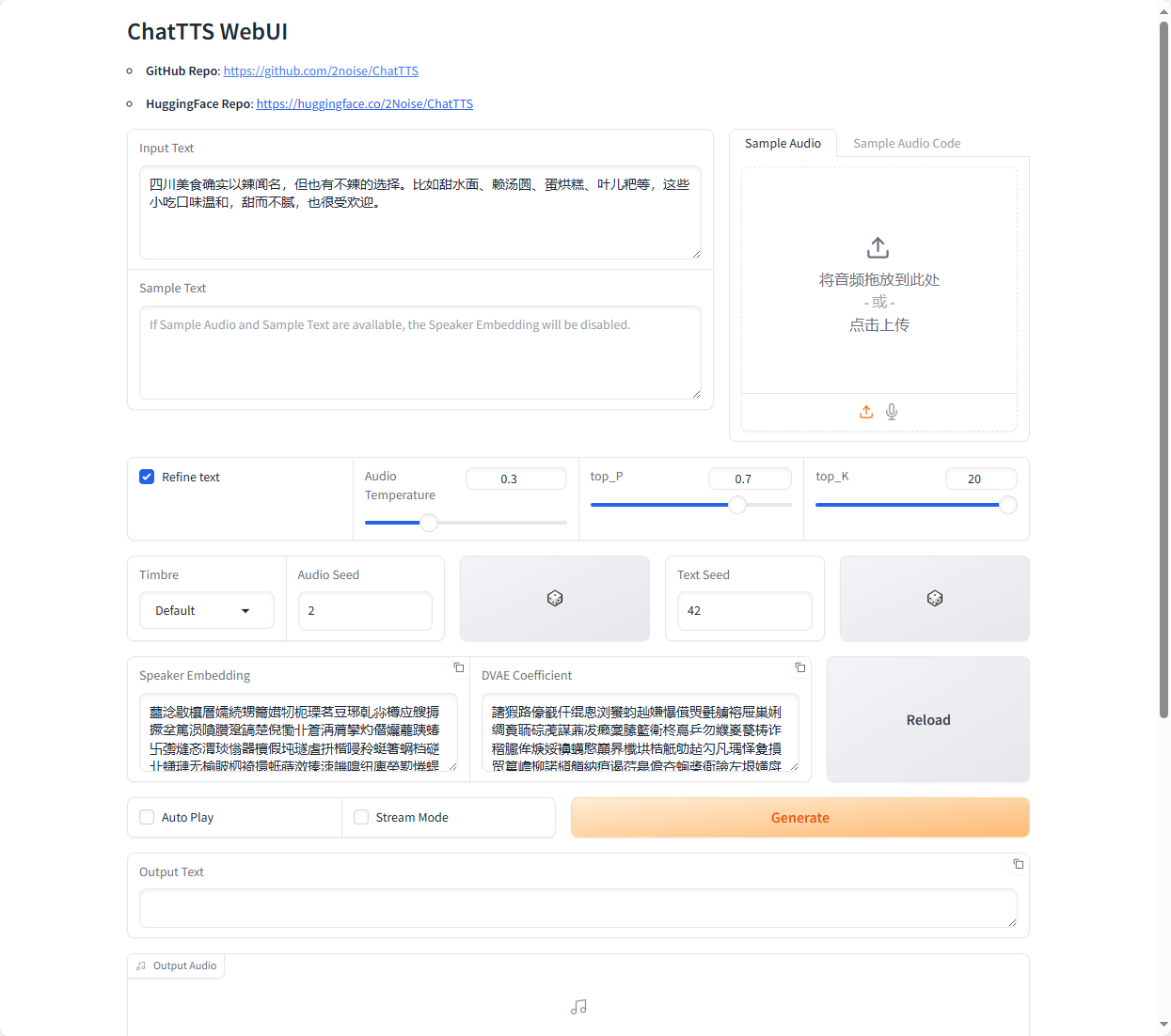
- [uv_break]、[laugh]等符号进行断句、微笑等声音控制。
- Audio Seed:用于初始化随机数生成器的种子值。设置相同的 Audio Seed 可以确保重复生成一致的语音,便于实验和调试。推荐 Seed: 3798-知性女、462-大舌头女、2424-低沉男。
- Text Seed:类似于 Audio Seed,在文本生成阶段用于初始化随机数生成器的种子值。
- Refine Text:勾选此选项可以对输入文本进行优化或修改,提升语音的自然度和可理解性。
- Audio Temperature️:控制输出的随机性。数值越高,生成的语音越可能包含意外变化;数值较低则趋向于更平稳的输出。
- Top_P:核采样策略,定义概率累积值,模型将只从这个累积概率覆盖的最可能的词中选择下一个词。
- Top_K:限制模型考虑的可能词汇数量,设置为一个具体数值,模型将只从这最可能的 K 个词中选择下一个词。
参考
[1]:https://github.com/lenML/ChatTTS-Forge/blob/main/docs/dependencies.md
[2]:https://blog.csdn.net/weixin_36829761/article/details/140164797


















