【联邦学习】在近年来的深度学习领域中备受关注,它通过在保证数据隐私的前提下,协同多个分散的设备或服务器进行模型训练。联邦学习技术能够在不集中数据的情况下,实现数据共享和模型优化,在医疗、金融和智能设备等领域取得了显著成果。其独特的方法和有效的表现使其成为研究热点之一。
为了帮助大家全面掌握联邦学习的方法并寻找创新点,本文总结了最近两年【联邦学习】相关的20篇顶会论文的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。

三篇详述
1、An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning
IMG_256
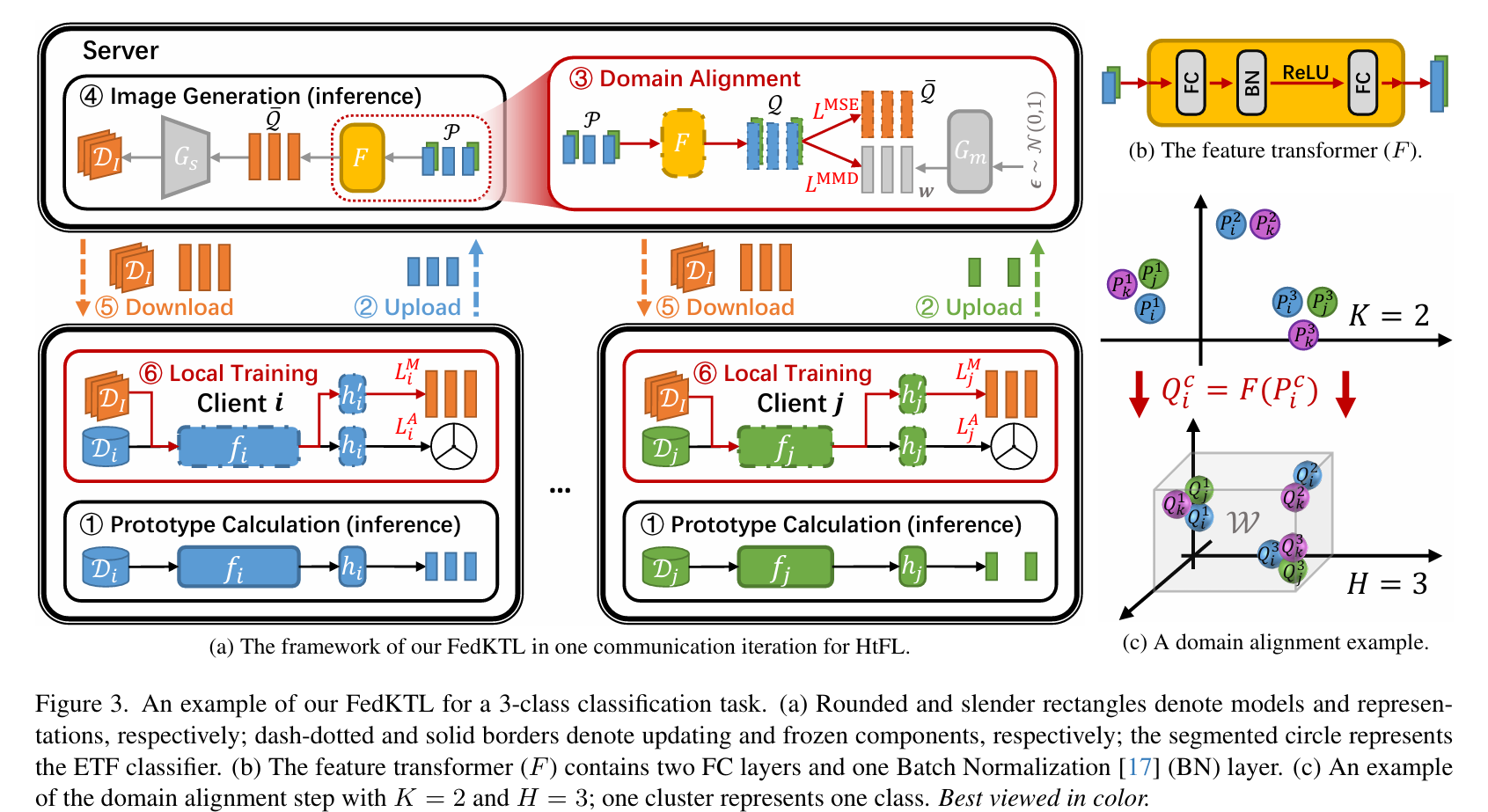
这篇文章提出了一种名为 Federated Knowledge-Transfer Loop (FedKTL) 的上传高效知识转移方案,旨在解决异构联邦学习(Heterogeneous Federated Learning, HtFL)中存在的数据和模型异构性问题。FedKTL 利用服务器端的预训练生成器所存储的知识,通过生成与客户端任务相关的原型图像-向量对,帮助客户端模型学习并提升性能。
主要贡献和特点:
-
上传高效:FedKTL 通过服务器上的生成器推理产生少量全局原型图像-向量对,这些向量对与客户端任务相关,使得客户端可以通过额外的监督本地任务转移来自生成器的预存知识。
-
解决异构性问题:该方案适用于客户端模型架构不同的场景,能够处理数据和模型的异构性。
-
实验验证:在四个数据集上进行了广泛的实验,包括 CIFAR10、CIFAR100、Tiny-ImageNet 和 Flowers102,使用了包括 CNN 和 ViT 在内的 14 种模型架构。实验结果显示 FedKTL 在准确性上超过了七种最先进方法,最高提升达到了 7.31%。
-
适用性:FedKTL 即使在只有一个边缘客户端的场景中也适用,展示了其在实际应用中的潜力。
-
代码开源:文章提供了实现 FedKTL 的代码,增加了研究的可复现性和实用性。
方法概述:
-
原型生成:每个客户端首先生成类别原型。
-
上传原型:客户端将原型上传到服务器。
-
特征转换器训练:服务器训练一个特征转换器(F),将客户端原型转换为有效的潜在向量。
-
图像生成:服务器使用类别中心潜在向量生成图像,并将图像-向量对分发给客户端。
-
本地训练:客户端使用本地数据和接收到的图像-向量对进行额外的监督学习,增强模型的特征提取能力。
相关工作:
-
文章讨论了异构联邦学习(HtFL)的相关研究,包括模型异构性的不同层次和现有方法。
-
探讨了 ETF(Equatorial Tight Frame)分类器在解决数据异构性问题中的应用。
-
分析了现有的 HtFL 方法,如基于知识蒸馏(KD)的技术,以及它们在处理全局数据集、全局辅助模型或全局类别原型时的局限性。
实验设置:
-
使用了多个数据集和基线方法进行比较。
-
考虑了模型异构性的不同场景,并在实际设置中评估了 FedKTL 的性能。
-
展示了 FedKTL 在处理不同数量客户端、不同客户端训练周期和不同特征维度时的性能。
结论:
文章提出的 FedKTL 通过利用预训练生成器的知识,有效地解决了 HtFL 中的知识共享难题,提高了客户端模型的性能,并且在保持上传效率的同时,减少了通信成本。
2、Federated Incremental Semantic Segmentation
IMG_257
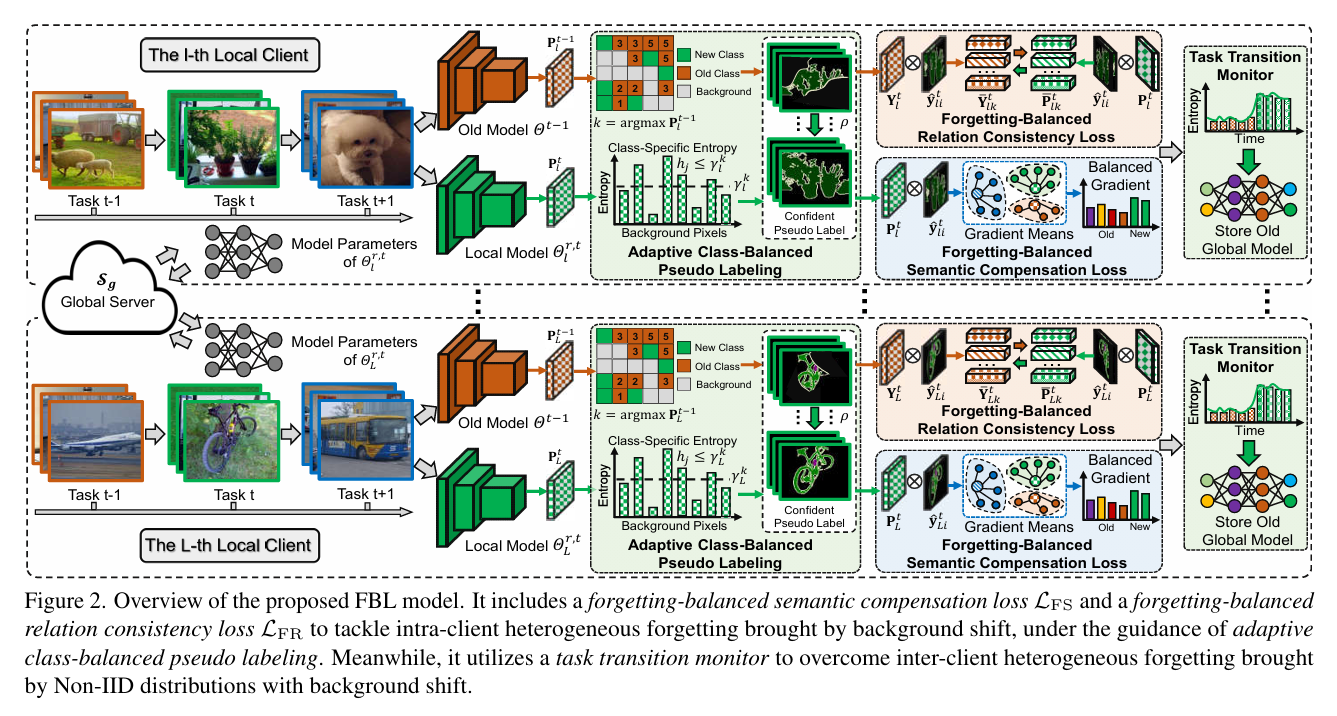
这篇文章提出了一种名为Federated Incremental Semantic Segmentation (FISS)的新问题,即在保护隐私的前提下,通过分布式训练学习一个全局模型,以解决在不同本地客户端上连续收集到的新类别的语义分割问题。FISS面临的主要挑战是本地客户端和不同客户端之间的异构遗忘,即在接收新类别的同时,对旧类别的记忆存储不足。
为了解决这个问题,文章提出了一种Forgetting-Balanced Learning (FBL)模型。FBL模型通过以下几个关键组件来解决FISS问题:
-
自适应类平衡伪标签生成:针对背景偏移问题,FBL模型开发了一种自适应类平衡伪标签方法,为旧类别生成可信的伪标签。
-
遗忘平衡语义补偿损失:提出了一种新的损失函数,考虑了不同旧任务间的平衡梯度传播,以解决本地客户端内部的异构遗忘问题。
-
遗忘平衡关系一致性损失:设计了一种新的损失函数,通过关系原型来补偿异构关系蒸馏增益,解决本地客户端内部的异构遗忘问题。
-
任务转换监控器:为了解决不同客户端之间的异构遗忘问题,提出了一种任务转换监控器,它可以在保护隐私的情况下自动识别新类别,并存储最新的旧全局模型以进行关系蒸馏。
文章通过在Pascal-VOC 2012和ADE20k数据集上的实验,验证了FBL模型在多种FISS设置下的有效性。实验结果表明,与现有的增量语义分割方法相比,FBL模型在mIoU(mean Intersection over Union)上取得了显著的改进,证明了其在解决FISS问题方面的优越性。
此外,文章还进行了消融研究,证明了模型中所有设计模块的有效性,包括自适应类平衡伪标签生成、遗忘平衡语义补偿损失和遗忘平衡关系一致性损失。通过这些组件,FBL模型能够在保护隐私的同时,协作地学习一个全局增量分割模型。
文章的结论部分指出,FBL模型成功解决了FISS问题,并通过实验验证了其有效性。未来的工作将考虑仅使用新类别的几个样本来解决本地客户端和不同客户端之间的遗忘问题。
3、Make Landscape Flatter in Differentially Private Federated Learning
IMG_258
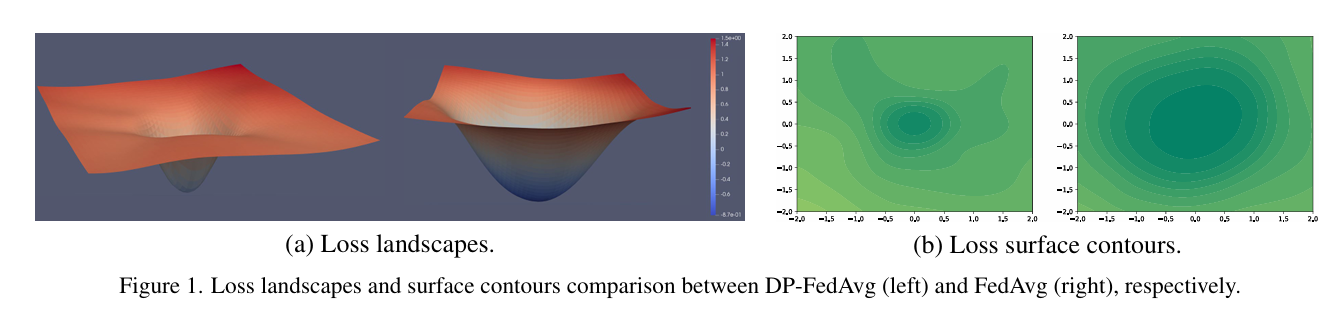
这篇文章提出了一种新的算法,旨在解决在联邦学习(FL)中由于引入差分隐私(DP)而造成的性能下降问题。文章首先介绍了联邦学习(FL),这是一种允许分布式客户端协作训练共享模型而不共享数据的技术。然而,FL面临着隐私泄露的严重困境,包括服务器可能通过精心设计的生产模型或影子模型推断客户端的隐私信息。为了解决这个问题,文章引入了差分隐私(DP),这是一种保护客户端数据隐私的标准方法。
文章指出,现有的客户端级DP联邦学习方法通过裁剪局部更新并添加随机噪声来保护隐私,但这些方法往往会导致损失景观变得更加陡峭,从而降低模型的权重扰动鲁棒性,最终导致严重的性能下降。为了缓解这些问题,文章提出了一种名为DP-FedSAM的新型DPFL算法。该算法利用梯度扰动来减轻DP的负面影响,通过集成Sharpness Aware Minimization(SAM)优化器来生成具有更好稳定性和权重扰动鲁棒性的局部平坦模型,从而改善性能。
从理论角度来看,文章详细分析了DP-FedSAM如何减轻由DP引起的性能下降,并给出了严格的隐私保证以及局部更新的敏感性分析。文章还通过实验证实了所提算法与现有的最先进基线相比,在DPFL中实现了最先进的性能。
文章的主要贡献可以总结为四点:
-
提出了DPFedSAM方案,从优化器的角度缓解了DPFL中的性能下降问题;
-
建立了比传统界限更紧的收敛速率,并提供了严格的隐私保证和敏感性分析;
-
首次深入分析了局部更新的平均范数αt和客户端之间局部更新的一致性˜αt对收敛的影响;
-
(通过大量实验验证了DP-FedSAM的效果,与几个强DPFL基线相比,实现了最先进的性能。
文章还回顾了相关工作,包括客户端级DPFL和SAM优化器。客户端级DPFL是保护客户端数据的实际方法,而SAM优化器是一种有效的深度学习模型训练优化器,它利用损失景观的平坦几何形状来提高模型的泛化能力。
在方法论部分,文章详细描述了DP-FedSAM的工作原理,包括如何采用SAM优化器在每个客户端中生成局部平坦模型,并通过聚合多个局部平坦模型来生成具有更高泛化能力和更好对抗DP噪声鲁棒性的全局平坦模型。
在理论分析部分,文章提供了对DP-FedSAM的敏感性、隐私和收敛速率的严格分析。文章首先给出了几个必要的假设,然后提供了局部更新的敏感性分析,并推导出客户端级DP在DP-FedSAM中的敏感度。
文章的实验部分对DP-FedSAM的有效性进行了广泛的验证。作者在EMNIST、CIFAR10和CIFAR-100数据集上进行了实验,并在独立同分布(IID)和非IID设置中进行了评估。实验结果表明,DP-FedSAM在保持隐私的同时,显著提高了性能,减少了DP引入的模型不一致性问题。