SAM2(Segment Anything 2)是Meta开发的一个新模型,可以对图像中的任何物体进行分割,而不局限于特定的类别或领域。这个模型的独特之处在于其训练数据的规模:1100万张图像和110亿个掩码。这种广泛的训练使SAM2成为训练新图像分割任务的强大起点。
如果SAM可以分割任何东西,为什么我们还需要重新训练它?因为训练数据的原因,SAM在常见物体上表现很好,但在稀有或特定领域的任务上可能表现相当差。

所以我们可以在SAM给出不充分结果的情况下,通过在新数据上进行微调显著提高模型的能力。因为这将需要更少的训练数据,并给出比从头开始训练模型更好的结果。
本文演示了如何在仅60行代码内(不包括标注和导入)对SAM2进行微调。
Segment Anything的工作原理
SAM的主要工作方式是接收一张图像和图像中的一个点,然后预测包含该点的分割掩码。这种方法实现了无需人工干预且不受类别或分割类型限制的全图像分割。
使用SAM进行全图像分割的步骤如下:
- 在图像中选择一组点
- 使用SAM预测包含每个点的分割
- 将得到的分割组合成一个单一的地图
虽然SAM也可以利用其他输入,如掩码或边界框,但这些主要与涉及人工输入的交互式分割相关。所以在本文中,我们将专注于全自动分割,只考虑单点输入。
下载SAM2并设置环境
按照github仓库上的安装说明进行操作。
一般来说,需要Python >=3.11和PyTorch。然后就是OpenCV,可以使用以下命令安装:
pip install opencv-python
因为微调,所以还需要从以下链接下载预训练模型:
https://github.com/facebookresearch/segment-anything-2?tab=readme-ov-file#download-checkpoints
可以从几个与模型中选择。这里为了方便则使用小型模型,因为它训练速度最快。
训练数据
下一步是下载用于微调模型的数据集。我们将使用LabPics1数据集来分割材料和液体。你可以从以下URL下载数据集:
https://zenodo.org/records/3697452/files/LabPicsV1.zip?download=1
对于数据,需要编写数据读取器。这将读取并准备供网络使用的数据。
数据读取器需要生成:
- 一张图像
- 图像中所有分割的掩码
- 每个掩码内的一个随机点
我们从加载依赖项开始:
importnumpyasnp
importtorch
importcv2
importos
fromsam2.build_samimportbuild_sam2
fromsam2.sam2_image_predictorimportSAM2ImagePredictor
接下来,列出数据集中的所有图像:
data_dir=r"LabPicsV1//"# LabPics1数据集文件夹路径
data=[] # 数据集中的文件列表
forff, nameinenumerate(os.listdir(data_dir+"Simple/Train/Image/")): # 遍历所有文件夹标注
data.append({"image":data_dir+"Simple/Train/Image/"+name,"annotation":data_dir+"Simple/Train/Instance/"+name[:-4]+".png"})
下面是加载训练批次的主要函数。训练批次包括:一张随机图像、属于该图像的所有分割掩码,以及每个掩码中的一个随机点:
defread_batch(data): # 从数据集(LabPics)中读取随机图像及其标注
# 选择图像
ent =data[np.random.randint(len(data))] # 选择随机条目
Img=cv2.imread(ent["image"])[...,::-1] # 读取图像
ann_map=cv2.imread(ent["annotation"]) # 读取标注
# 调整图像大小
r=np.min([1024/Img.shape[1], 1024/Img.shape[0]]) # 缩放因子
Img=cv2.resize(Img, (int(Img.shape[1] *r), int(Img.shape[0] *r)))
ann_map=cv2.resize(ann_map, (int(ann_map.shape[1] *r), int(ann_map.shape[0] *r)),interpolation=cv2.INTER_NEAREST)
# 合并容器和材料标注
mat_map=ann_map[:,:,0] # 材料标注地图
ves_map=ann_map[:,:,2] # 容器标注地图
mat_map[mat_map==0] =ves_map[mat_map==0]*(mat_map.max()+1) # 合并地图
# 获取二进制掩码和点
inds=np.unique(mat_map)[1:] # 加载所有索引
points= []
masks= []
forindininds:
mask=(mat_map==ind).astype(np.uint8) # 制作二进制掩码
masks.append(mask)
coords=np.argwhere(mask>0) # 获取掩码中的所有坐标
yx=np.array(coords[np.random.randint(len(coords))]) # 选择随机点/坐标
points.append([[yx[1], yx[0]]])
returnImg,np.array(masks),np.array(points), np.ones([len(masks),1])
这个函数的第一部分是选择一个随机图像并加载它:
ent =data[np.random.randint(len(data))] # 选择随机条目
Img=cv2.imread(ent["image"])[...,::-1] # 读取图像
ann_map=cv2.imread(ent["annotation"]) # 读取标注
OpenCV读取的图像是BGR格式,而SAM期望RGB格式的图像,使用[…,::-1]将图像从BGR转换为RGB。
SAM期望图像大小不超过1024,所以要将图像和标注调整到这个大小。
r=np.min([1024/Img.shape[1], 1024/Img.shape[0]]) # 缩放因子
Img=cv2.resize(Img, (int(Img.shape[1] *r), int(Img.shape[0] *r)))
ann_map=cv2.resize(ann_map, (int(ann_map.shape[1] *r), int(ann_map.shape[0] *r)),interpolation=cv2.INTER_NEAREST)
这里有一个重要的点是,在调整标注地图(ann_map)大小时,使用INTER_NEAREST模式(最近邻)。在标注地图中,每个像素值是它所属分割的索引,所以使用不会引入新值到地图中的调整方法很重要。
下一个代码块是特定于LabPics1数据集格式的。标注地图(ann_map)在一个通道中包含图像中容器的分割地图,在另一个通道中包含材料标注的地图。我们将它们合并成一个单一的地图。
mat_map=ann_map[:,:,0] # 材料标注地图
ves_map=ann_map[:,:,2] # 容器标注地图
mat_map[mat_map==0] =ves_map[mat_map==0]*(mat_map.max()+1) # 合并地图
这给我们的是一个地图(mat_map),其中每个像素的值是它所属分割的索引(例如:所有值为3的单元格属于分割3)。我们想将这个转换成一组二进制掩码(0/1),每个掩码对应一个不同的分割。
inds=np.unique(mat_map)[1:] # 地图中所有索引的列表
points= [] # 所有点的列表(每个掩码一个)
masks= [] # 所有掩码的列表
forindininds:
mask= (mat_map==ind).astype(np.uint8) # 为索引ind制作二进制掩码
masks.append(mask)
coords=np.argwhere(mask>0) # 获取掩码中的所有坐标
yx=np.array(coords[np.random.randint(len(coords))]) # 选择随机点/坐标
points.append([[yx[1], yx[0]]])
returnImg,np.array(masks),np.array(points), np.ones([len(masks),1])
这样就得到了图像(Img)、对应图像中分割的二进制掩码列表(masks),以及每个掩码内单个点的坐标(points)。

上面就是训练数据批次示例:1)一张图像。2)分割掩码列表。3)每个掩码内的一个单点(仅用红色标记以便可视化)
加载SAM模型
因为是微调,所以我们需要加载网络:
sam2_checkpoint="sam2_hiera_small.pt"# 模型权重路径
model_cfg="sam2_hiera_s.yaml"# 模型配置
sam2_model=build_sam2(model_cfg, sam2_checkpoint, device="cuda") # 加载模型
predictor=SAM2ImagePredictor(sam2_model) # 加载网络
首先在sam2_checkpoint参数中设置模型权重的路径。*"sam2_hiera_small.pt"指的是小型模型,无论选择哪个模型都需要在model_cfg参数中设置相应的配置文件。配置文件已经位于主仓库的"sam2_configs/"***子文件夹中。
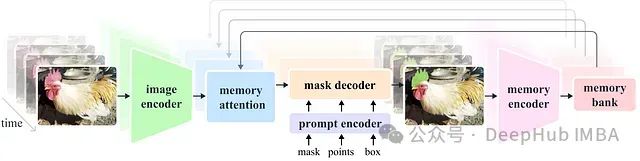
Segment Anything的一般结构
在设置训练参数之前,我们需要了解SAM模型的基本结构。SAM由三部分组成:
1)图像编码器
图像编码器负责处理图像并创建代表图像的嵌入。这部分由VIT transformer组成,是网络的最大组件。我们通常不想训练它,因为它已经提供了良好的表示,而且训练会需要大量资源。
2)提示编码器
提示编码器处理网络的额外输入,在我们这篇文章的情况下是输入点。
3)掩码解码器
掩码解码器接收图像编码器和提示编码器的输出,并生成最终的分割掩码。一般来说,我们只想训练掩码解码器,也许还有提示编码器。这些部分是轻量级的,可以用适度的GPU快速微调。
设置训练参数
可以通过设置以下内容来启用掩码解码器和提示编码器的训练:
predictor.model.sam_mask_decoder.train(True) # 启用掩码解码器的训练
predictor.model.sam_prompt_encoder.train(True) # 启用提示编码器的训练
定义标准的adamW优化器:
optimizer=torch.optim.AdamW(params=predictor.model.parameters(),lr=1e-5,weight_decay=4e-5)
还将使用混合精度训练,这只是一种更节省内存的训练策略:
scaler=torch.cuda.amp.GradScaler() # 设置混合精度
训练主循环
现在可以构建主训练循环了,第一部分是读取和准备数据:
foritrinrange(100000):
withtorch.cuda.amp.autocast(): # 转换为混合精度
image,mask,input_point, input_label=read_batch(data) # 加载数据批次
ifmask.shape[0]==0: continue# 忽略空批次
predictor.set_image(image) # 对图像应用SAM图像编码器
将数据转换为混合精度以进行高效训练:
withtorch.cuda.amp.autocast():
接下来使用之前创建的读取函数来读取训练数据:
image,mask,input_point, input_label=read_batch(data)
加载的图像并传递给图像编码器(网络的第一部分):
predictor.set_image(image)
接下来使用网络的prompt编码器处理输入点:
mask_input, unnorm_coords, labels, unnorm_box = predictor._prep_prompts(input_point, input_label, box=None, mask_logits=None, normalize_coords=True)
sparse_embeddings, dense_embeddings = predictor.model.sam_prompt_encoder(points=(unnorm_coords, labels),boxes=None,masks=None,)
在这部分我们也可以输入框或掩码,但我们不会使用这些选项。
已经编码了prompt(点)和图像,可以预测分割掩码了:
batched_mode = unnorm_coords.shape[0] > 1 # multi mask prediction
high_res_features = [feat_level[-1].unsqueeze(0) for feat_level in predictor._features["high_res_feats"]]
low_res_masks, prd_scores, _, _ = predictor.model.sam_mask_decoder(image_embeddings=predictor._features["image_embed"][-1].unsqueeze(0),image_pe=predictor.model.sam_prompt_encoder.get_dense_pe(),sparse_prompt_embeddings=sparse_embeddings,dense_prompt_embeddings=dense_embeddings,multimask_output=True,repeat_image=batched_mode,high_res_features=high_res_features,)
prd_masks = predictor._transforms.postprocess_masks(low_res_masks, predictor._orig_hw[-1])# Upscale the masks to the original image resolution
这段代码的主要部分是 model.sam_mask_decoder,它运行网络的mask_decoder部分并生成分割掩码(low_res_masks)及其分数(prd_scores)。
这些掩码的分辨率低于原始输入图像,并在 postprocess_masks 函数中调整为原始输入大小。
这给我们提供了网络的最终预测:每个输入点的3个分割掩码(prd_masks)和掩码分数(prd_scores)。prd_masks 包含每个输入点的3个预测掩码,但我们只会使用每个点的第一个掩码。prd_scores 包含网络认为每个掩码有多好(或对预测有多确定)的分数。
损失函数
1、分割损失
现在我们有了网络预测,可以计算损失了。首先要计算分割损失,这意味着预测掩码与真实掩码相比有多好。所以可以使用标准交叉熵损失。
使用sigmoid函数将预测掩码(prd_mask)从logits转换为概率:
prd_mask = torch.sigmoid(prd_masks[:, 0])# 将logit图转换为概率图
将真实掩码转换为torch张量:
prd_mask = torch.sigmoid(prd_masks[:, 0])# 将logit图转换为概率图
最后使用真实掩码(gt_mask)和预测概率图(prd_mask)手动计算交叉熵损失(seg_loss):
seg_loss = (-gt_mask * torch.log(prd_mask + 0.00001) - (1 - gt_mask) * torch.log((1 - prd_mask) + 0.00001)).mean() # 交叉熵损失
这里添加0.0001以防止log函数对零值爆炸。
2、分数损失(可选)
除了掩码外,网络还预测每个预测掩码的好坏分数。训练这部分不太重要,但可能有用。要训练这部分,首先需要知道每个预测掩码的真实分数。也就是说,预测掩码实际上有多好。我们将通过使用交集除并集(IOU)指标比较GT掩码和相应的预测掩码来做到这一点。IOU简单来说就是两个掩码的重叠区域除以两个掩码的合并区域。
计算预测掩码和GT掩码之间的交集(它们重叠的区域):
inter = (gt_mask * (prd_mask > 0.5)).sum(1).sum(1)
使用阈值 (prd_mask > 0.5) 将预测掩码从概率转换为二进制掩码。
接下来通过将交集除以预测掩码和gt掩码的合并区域(并集)来获得IOU:
iou = inter / (gt_mask.sum(1).sum(1) + (prd_mask > 0.5).sum(1).sum(1) - inter)
使用IOU作为每个掩码的真实分数,并将分数损失作为预测分数与我们刚刚计算的IOU之间的绝对差异。
score_loss = torch.abs(prd_scores[:, 0] - iou).mean()
最后合并分割损失和分数损失(给予前者更高的权重):
loss = seg_loss+score_loss*0.05 # 混合损失
最后一步:反向传播和保存模型
一旦得到损失就可以使用之前创建的优化器计算反向传播并更新权重:
predictor.model.zero_grad() # 清空梯度
scaler.scale(loss).backward() # 反向传播
scaler.step(optimizer)
scaler.update() # 混合精度
每1000步保存一次训练好的模型:
if itr%1000==0: torch.save(predictor.model.state_dict(), "model.torch") # 保存模型
由于我们已经计算了IOU,可以将其显示为移动平均值,查看模型预测随时间的改善情况:
if itr==0: mean_iou=0
mean_iou = mean_iou * 0.99 + 0.01 * np.mean(iou.cpu().detach().numpy())
print("step)",itr, "Accuracy(IOU)=",mean_iou)
我们在不到60行代码(不包括标注和导入)内训练/微调了Segment-Anything 2。我们这篇文章的训练结果,大约25,000步后,应该会看到重大改进。
推理:加载和使用训练好的模型
现在模型已经微调好了,让我们用它来分割一张图像。
分割将通过以下步骤完成:
- 加载我们刚刚训练的模型。
- 给模型一张图像和一堆随机点。对于每个点,网络将预测包含该点的分割掩码和分数。
- 将这些掩码拼接成一个分割图。
首先加载依赖项并将权重转换为float16,这使得模型运行得更快(仅适用于推理)。
# 对整个脚本使用bfloat16(内存高效)
torch.autocast(device_type="cuda", dtype=torch.bfloat16).enter()
接下来,加载一个样本图像和我们想要分割的图像区域的掩码(下载图像/掩码):
image_path = r"sample_image.jpg" # 图像路径
mask_path = r"sample_mask.png" # 掩码路径,掩码将定义要分割的图像区域
def read_image(image_path, mask_path): # 读取并调整图像和掩码的大小
img = cv2.imread(image_path)[...,::-1] # 以rgb格式读取图像
mask = cv2.imread(mask_path,0) # 我们想要分割的区域的掩码
# 将图像调整到最大尺寸1024
r = np.min([1024 / img.shape[1], 1024 / img.shape[0]])
img = cv2.resize(img, (int(img.shape[1] * r), int(img.shape[0] * r)))
mask = cv2.resize(mask, (int(mask.shape[1] * r), int(mask.shape[0] * r)),interpolation=cv2.INTER_NEAREST)
return img, mask
image,mask = read_image(image_path, mask_path)
在我们想要分割的区域内采样30个随机点:
num_samples = 30 # 要采样的点/分段数量
def get_points(mask,num_points): # 在输入掩码内采样点
points=[]
for i in range(num_points):
coords = np.argwhere(mask > 0)
yx = np.array(coords[np.random.randint(len(coords))])
points.append([[yx[1], yx[0]]])
return np.array(points)
input_points = get_points(mask,num_samples)
加载标准SAM模型(与训练时相同)
# 加载模型,您需要已经有预训练模型
sam2_checkpoint = "sam2_hiera_small.pt"
model_cfg = "sam2_hiera_s.yaml"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
predictor = SAM2ImagePredictor(sam2_model)
加载我们刚刚训练的模型的权重(model.torch):
predictor.model.load_state_dict(torch.load("model.torch"))
运行微调后的模型,为我们选择的每个点预测一个掩码:
with torch.no_grad(): # 防止网络计算梯度(更高效的推理)
predictor.set_image(image) # 图像编码器
masks, scores, logits = predictor.predict( # prompt编码器 + mask解码器
point_coords=input_points,
point_labels=np.ones([input_points.shape[0],1])
)
现在有了一系列预测掩码及其分数。我们需要把它们以某种方式拼接成一个单一的一致分割图。许多掩码重叠并可能彼此不一致。由于我们随机选择了点,所以很可能有些点会落在同一个分段中。
拼接的方法很简单,将根据预测分数对预测掩码进行排序:
np_masks = np.array(masks[:,0].cpu().numpy()) # 从torch转换为numpy
np_scores = scores[:,0].float().cpu().numpy() # 从torch转换为numpy
shorted_masks = np_masks[np.argsort(np_scores)][::-1] # 根据分数排列掩码
创建一个空的分割图和占用图:
seg_map = np.zeros_like(shorted_masks[0],dtype=np.uint8)
occupancy_mask = np.zeros_like(shorted_masks[0],dtype=bool)
一个接一个地将掩码添加到分割图中(从高分到低分)。我们只添加与之前添加的掩码一致的掩码,这意味着只有当想要添加的掩码与已占用区域的重叠少于15%时才添加。
for i in range(shorted_masks.shape[0]):
mask = shorted_masks[i]
if (mask*occupancy_mask).sum()/mask.sum()>0.15: continue
mask[occupancy_mask]=0
seg_map[mask]=i+1
occupancy_mask[mask]=1
seg_mask 现在包含预测的分割图,每个分片有不同的值,背景为0。
rgb_image = np.zeros((seg_map.shape[0], seg_map.shape[1], 3), dtype=np.uint8)
for id_class in range(1,seg_map.max()+1):
rgb_image[seg_map == id_class] = [np.random.randint(255), np.random.randint(255), np.random.randint(255)]
可以使用以下命令将其转换为彩色图:
rgb_image = np.zeros((seg_map.shape[0], seg_map.shape[1], 3), dtype=np.uint8)
for id_class in range(1,seg_map.max()+1):
rgb_image[seg_map == id_class] = [np.random.randint(255), np.random.randint(255), np.random.randint(255)]
显示最终的结果
cv2.imshow("annotation",rgb_image)
cv2.imshow("mix",(rgb_image/2+image/2).astype(np.uint8))
cv2.imshow("image",image)
cv2.waitKey()

就是这样,完整的代码在这里:
https://avoid.overfit.cn/post/9598b9b4ccc64a8e86275f1e7712e0dd
作者:Sagi eppel



















