一、说明
注意力机制是深度学习领域的一个突破。它们帮助模型专注于数据的重要部分,并提高语言处理和计算机视觉等任务的理解和性能。这篇文章将深入探讨深度学习中注意力的基础知识,并展示其背后的主要思想。
二、注意力机制回顾
在我们谈论注意力之前,让我们先回顾一下深度学习中序列模型(也称为递归神经网络或 RNN)背后的基本思想。我们不打算深入研究这个领域,但理解序列模型背后的概念将有助于我们理解注意力机制和它所解决的问题。
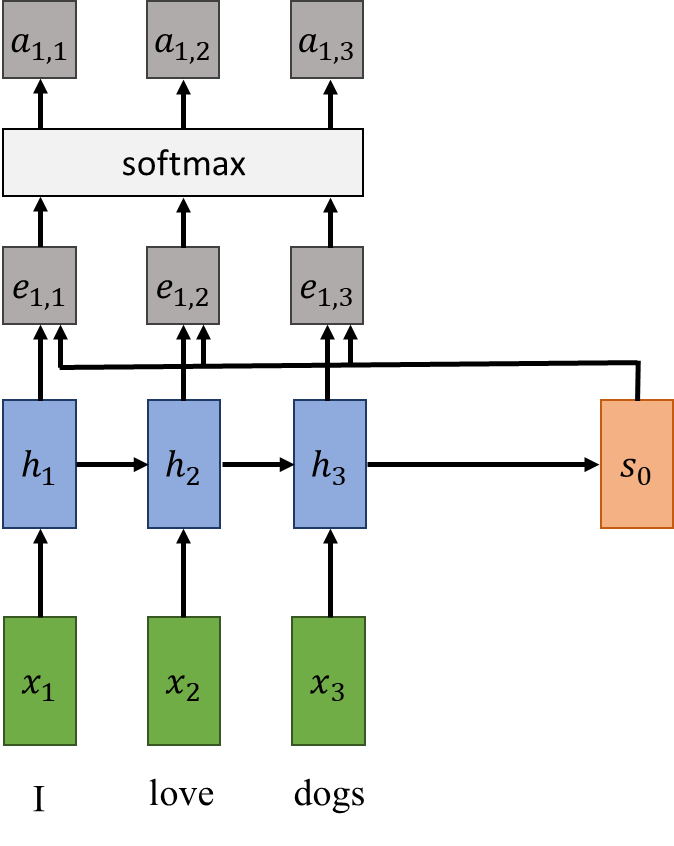
我们将使用的示例是一个用于将句子从英语翻译成意大利语的网络。该网络由两部分组成:编码器,对英语句子的含义进行编码,以及将编码信息解码为句子到意大利语的翻译的解码器。
我们可以用以下方式来看待编码器:
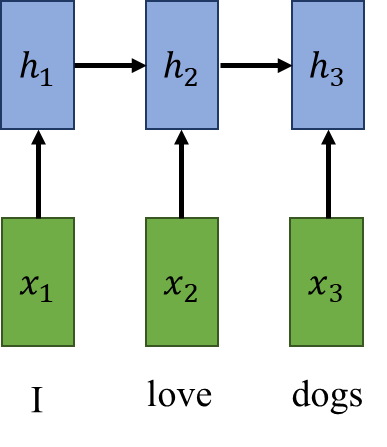
绿色矩形是输入。在图中所示的情况下,输入是一系列英语单词,这些单词组成了“I love dogs”这句话。蓝色矩形称为隐藏状态。隐藏状态应该包含有关当前输入的一些知识,即先前的隐藏状态,而先前的隐藏状态本身包含其输入和先前隐藏状态的知识。正式地,我们可以这样写:
![]()
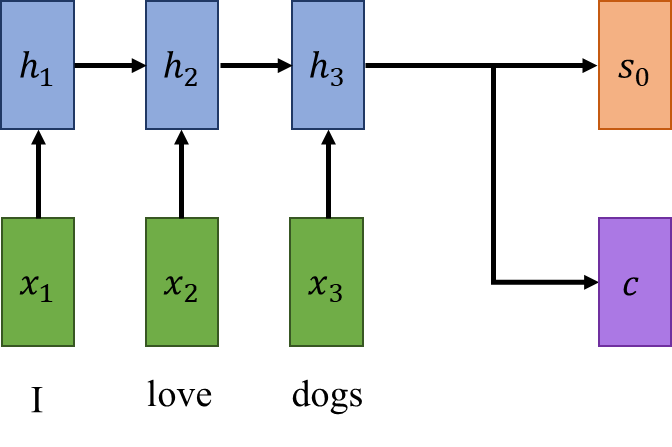
通过这种方式,我们将句子的信息编码为隐藏状态,直到句子的结尾。在检查了所有输入之后,编码器将句子的所有内容(从最后一个隐藏状态开始)汇总到两个向量中。第一个应该是解码器(网络中应该进行实际转换的部分)的初始隐藏状态 s₀,第二个是上下文向量(通常是编码器的最终隐藏状态),c,解码器的任何步骤都将使用它来帮助它理解它所处理的句子。
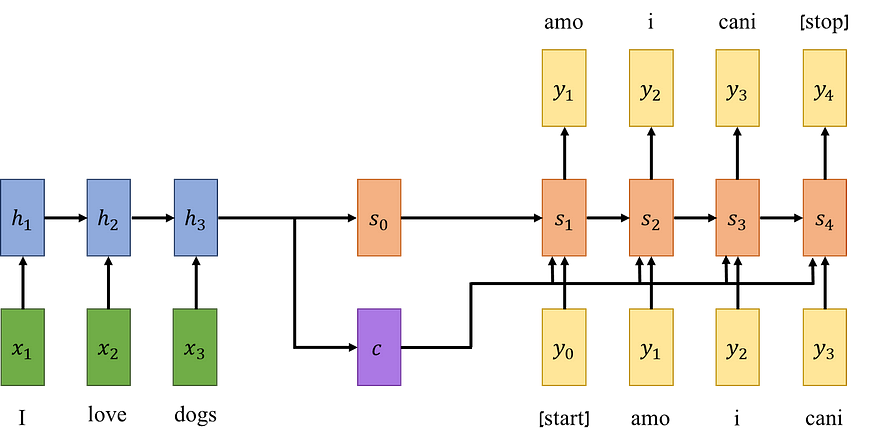
现在,当我们在编码器部分完成句子信息的提炼后,我们就可以开始解码信息并使用解码器将句子翻译成意大利语了。解码器的第一个输入是一个开始令牌,它与初始隐藏状态和上下文向量一起构成了第一个隐藏状态。对于这种隐藏状态,我们可以得到新句子的第一个输出。我们将该输出与上一个隐藏状态和上下文向量一起用作下一步的输入,以构建新的隐藏状态和输出。正式地,我们可以这样写:
![]()
这个过程一直持续到我们得到一个停止令牌作为输出。
此过程适用于短句子,但当句子变长时,它可能会失败。原因是解码器对所有步骤都使用上下文向量,并且它需要它包含有关原始句子的所有信息。对于一个很长的句子,将整个信息保存在一个固定大小的向量中可能非常困难。该问题的解决方案可能是为解码器的每一步构建一个新的上下文向量。
三、注意力
我们将像以前一样保持编码器-解码器的架构,但这次我们向网络添加了另一种机制,为解码器的每一步构建一个新的上下文向量。
我们的编码器仍然会像以前一样检查输入序列并创建隐藏状态,最后为解码器创建初始隐藏状态。现在,我们不是使用编码器的最终隐藏状态来制作上下文向量,而是使用解码器的初始隐藏状态和所有其他隐藏状态来构造它。为此,我们将实现一个对齐函数,该函数是在编码器的隐藏状态和解码器的隐藏状态上运行的 MPL。此函数计算编码器的每个隐藏状态的对齐分数(即标量)。从形式上讲,第 i 个隐藏状态的步骤 t 的对齐分数为:
![]()
这些分数表示,鉴于解码器的当前隐藏状态,我们应该在多大程度上关注编码器的每个隐藏状态。
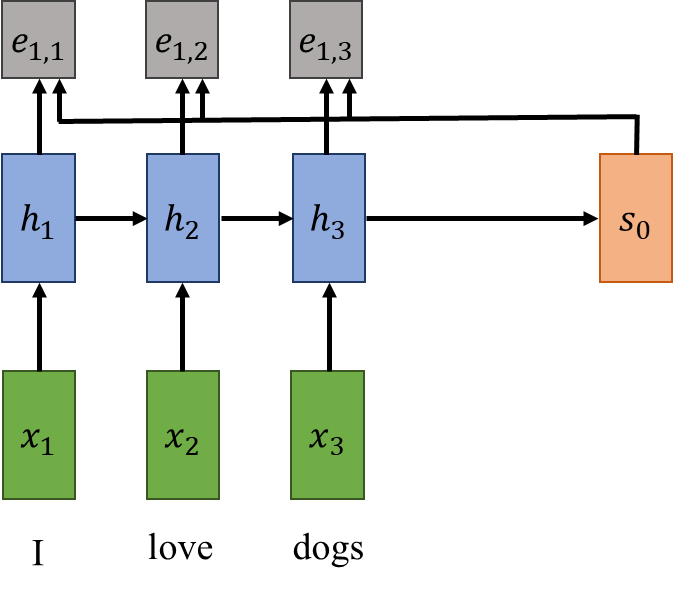
例如,对齐分数 e₁,₁ 表示第一个隐藏状态对于解码器中第一个单词的预测有多重要。由于对齐分数是任意实数,我们希望对它们应用 softmax 运算以获得概率分布。
这些概率是归一化对齐分数,它们将用作编码器隐藏状态的注意力权重。新的上下文向量将是编码器的隐藏状态的加权和,加上注意力权重的加权和。

从形式上讲,步骤 t 的上下文向量是:
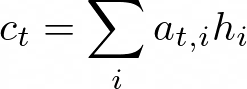
现在,我们可以使用新的上下文向量来预测解码器中的第一个单词。
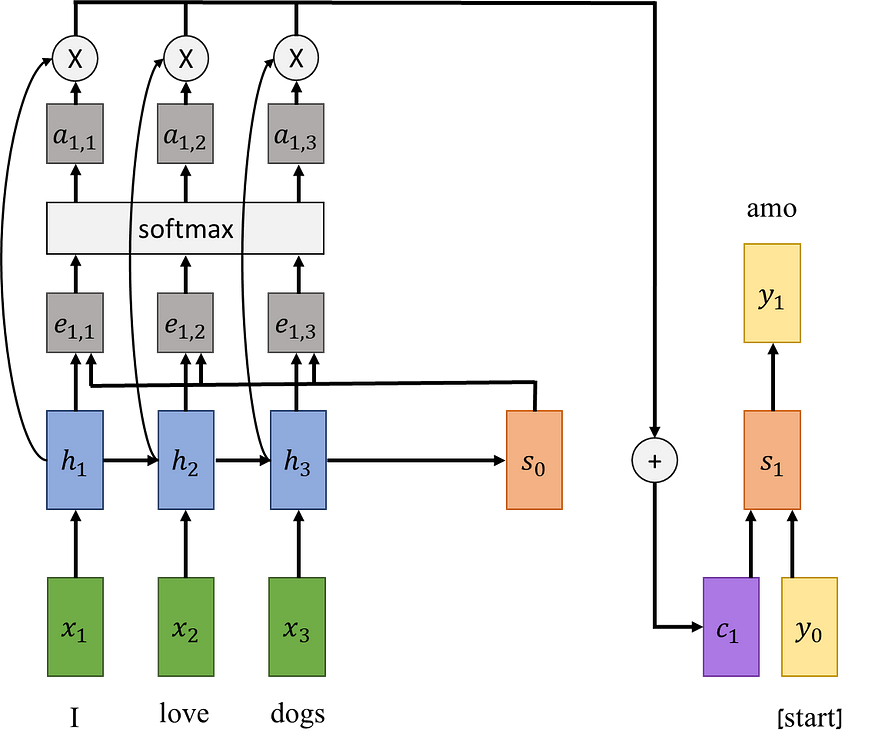
就直觉而言,在我们的示例中,“amo”的意思是“我爱”,因此我们可以预期 a₁,₁ 和 a₁,₂ 的分数很高,而 a₁,₃ 的分数很低。
好的部分是所有的操作都是差分的,所以我们不需要对注意力权重进行任何监督,我们可以在网络的常规训练中学习计算它们,因此网络可以自行学习哪些部分是重要的每一步。
对于句子的其他部分,解码器的预测以相同的方式继续进行。对于下一个单词,我们通过使用 s₁ 来计算注意力权重来构造 c₂ 上下文向量。

我们可以看到英语和法语之间翻译中单词之间注意力权重的可视化,下图取自 Bahdanau 等人。

由 RNNsearch-50 找到的比对。每个图的 x 轴和 y 轴分别对应于源句子(英语)和生成的翻译(法语)中的单词。每个像素以灰度(0:黑色,1:白色)显示第 i 个目标词的第 j 个源词注释的权重 αij。资料来源:图3。
您可以看到相关词的权重很高,而关系较弱的词的权重很小。例如,请参阅“Area”和“zone”一词的权重。这些词在句子中的不同位置,但网络成功地将它们联系起来。
四、图片说明的注意事项
如果你仔细看一下前面的例子,你会发现我们没有使用输入的顺序性质来表示注意力部分。这意味着我们可以将注意力用于其他不是序列的任务。使用注意力机制的另一个任务示例是图像标题。在图像描述中,我们有一个图像,我们希望我们的网络输出一个句子来描述我们在图像中看到的内容。

与翻译任务类似,我们可以通过 CNN 网络运行图像,并将最终输出作为特征向量网格,这些特征向量类似于我们之前使用的隐藏状态。然后,我们计算解码器的初始隐藏状态,并将其与网格特征向量一起使用来计算对齐分数。使用 softmax,我们得到注意力权重,然后我们计算特征向量与注意力权重的加权和,以构建上下文向量。最后,我们使用上下文向量来生成标题中的第一个单词。

正式:
![]()
和
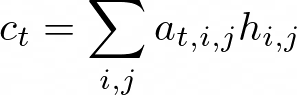
在下面的可视化中可以看到网络对图像每个部分的关注。

随时间推移的注意力。当模型生成每个单词时,其注意力会发生变化以反映图像的相关部分。资料来源:Xu et al
例如,您可以看到“鸟”一词如何关注鸟的图像部分,而“水”一词如何关注背景中的水。
五、结论
在这篇文章中,我们介绍了注意力机制背后的基本思想。我们看到了它如何通过关注编码器最相关的部分,在每一步构建一个新的上下文向量,从而解决编码器-解码器架构中处理长句子的问题以进行翻译。我们还看到了如何利用注意力机制来完成图像标题的任务,其中注意力有助于将注意力集中在图像的相关部分,以预测标题中的下一个单词。
在以后的文章中,我们将回顾注意力的数学原理,并介绍自我注意力模块。