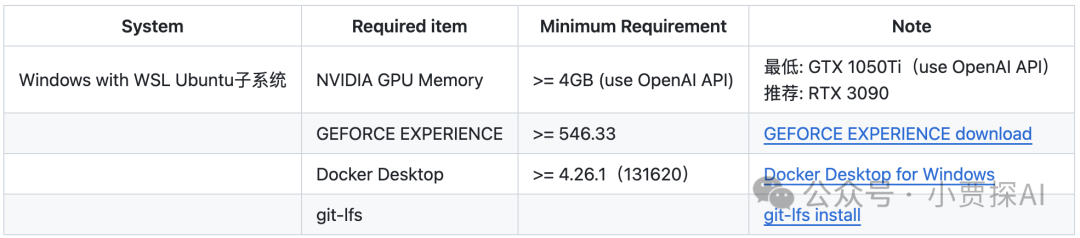
1、在Transformer模型中,为什么scaled dot-product attention在计算QK内积之后要除以根号d?
简单来说,就是需要压缩softmax输入值,以免输入值过大,进入了softmax的饱和区,导致梯度值太小而难以训练。如果不对attention值进行scaling,也可以通过在参数初始化时将方差除以根号d ,同样可以起到预防softmax饱和的效果。
2、Transformer自注意力计算中,为什么Q和K要使用不同的权重矩阵进行线性变换投影,为什么不使用同一个变换矩阵,或者不进行变换?
1、如果Q和K一样,则矩阵乘积的结果是一个对称矩阵,这样减弱了模型的表达能力。
2、如果Q和K一样,乘积结果的对称矩阵中,对角线的值会比较大,导致每个位置过分关注自己。
3、使用不同的投影矩阵,参数增多,可以增强模型表达能力。
3、Transformer模型中,注意力计算后面使用了两个FFN层,为什么第一个FFN层先把维提升,第二个FFN层再把维度降回原大小?
1、提升维度:类似SVM kernel,通过提升维度可以识别一些在低维无法识别的特征。
2、提升维度:更大的可训练参数,提升模型的容量。
3、降回原维度:方便多层注意力层和残差模块进行拼接,而无需进行额外的处理。
4、MQA(Multi-Query Attention)和GQA(Grouped-Query Attention)相比MHA(Multi-Head Attention),计算量变化如何,主要带来了什么优化?
1、MQA和GQA虽然可训练参数量比MHA少,但是计算量和MHA相比变化不大,主要在生成KV时有少量降低。
2、Decoder-only的大模型由于causal attention的存在,使用了KV缓存加速推理。MQA和GQA能减少KV头的数量,节省了缓存,使得在输入长度较长时也能把KV放进缓存。
5、为什么现在主流的LLM模型基本都是Decoder-only的结构?单向注意力模型为什么效果比双向注意力效果好?
1、双向Attention在多层模型训练中容易退化成低秩矩阵,限制了模型容量;而Decoder-only模型使用了下三角注意力矩阵,使得训练过程中矩阵是满秩,建模能力更强。
2、单向注意力模型相比双向注意力模型在训练的时候难度更大,能迫使模型学到更多信息。
3、Causal Attention天然具有位置编码的功能,而双向Attention即使交换两个token的位置也基本不影响表示,对语序区分能力较弱。
4、工程上,单向模型支持KV Cache等,对于对话场景效率友好。
5、轨迹依赖,基模型训练成本高,业界倾向于沿着已经成功的模型继续开发。
6、在Bert中,词向量token embedding和(绝对)位置编码position encoding为什么可以直接相加?
1、两个向量相加,理论上其效果等价于维度拼接concat+线性变换,而相加的操作在实现上更为方便。
2、高维空间中(如768维),两个随机向量近似为正交关系。模型在高维度有能力区分出所有组合的情况。假设共有2万个词向量,500个位置,则模型需要在768维空间区分1000万个点,即使768维每个维度只能取1和-1也具备足够的区分能力。
3、词向量和位置编码可以认为都是一个one-hot向量经过一层线性变换层得到的。两个向量相加等价于把它们的one-hot编码拼接后进行线性变换。
4、没有使用相乘则是出于工程考虑。相加相比相乘结果更为稳定,方便训练。
7、LoRA和全参数训练在计算量和显存上相比如何?为什么LoRA能提升大模型训练效率?
1、计算量上:LoRA训练时,在主干模型的(部分)全连接层增加了LoRA旁路,前向和后向的计算量都在主干模型的基础上,增加了旁路部分的计算,因此相比全参数训练,略有增加。
2、显存上:训练时,显存主要有①模型参数②梯度③中间激活值④优化器参数四个部分。模型参数/梯度/激活值相比全参数训练也略微增加;而优化器则不需要再存储原模型参数的部分,只需要存储LoRA旁路部分,这部分节省较多显存。
3、使用LoRA能提升训练效率主要是因为(1)优化器部分的显存需要减少了,可以增大batch(2)优化器参数减少了,分布式训练中多卡之间的通信量减少了(3)(optional)主干模型由于不用更新,可以进一步量化到int8/int4等。
8、为什么模型需要normalization(batchnorm/layernorm等)?
1、输入数据包含多个特征,特征之间有不同的量纲和范围(如身高180和年龄18岁),通过normalization进行归一化再经过模型进行线性/非线性组合,能够防止部分特征占据主导,部分特征被忽略。
2、batchnorm论文认为:模型一般有多层,前一层的输出是后一层的输入,而训练中前一层的参数更新会导致后一层的输入数据分布变化导致ICS(internal covariate shift),这样后面的层就不得不频繁剧烈更新适应分布变化,导致分布偏移进入激活函数饱和区而出现梯度消失,另外分布变化也是对i.i.d.条件的破坏。使用normalization可以保持分布的稳定,减小方差,使模型训练可以正常进行。
3.《How Does Batch Normalization Help Optimization?》设计了实验测量使用batchnorm前后的ICS,发现batchnorm实际上并没有缓解ICS,甚至有所增加。而batchnorm能优化模型训练的原因更多是使得损失函数平面更加光滑,而便于梯度下降收敛。
9、Transformer中pre-norm和post-norm各有什么优缺点?
1.原始的Transformer用的是post-norm,它在残差之后进行归一化(add & norm),对参数正则化的效果更强,模型更为鲁棒;post-norm对每个通路都进行了归一化,使得梯度在回传的时候容易出现消失。
2.Pre-norm相对于post-norm,残差部分存在不经过归一化的通路,因此能够缓解梯度消失,能够训练更深的网络。但是模型的等效“深度”受到影响,L+1层网络近似于一个L层的宽网络。
3.也就是说,在层数较少,post-norm和pre-norm都能正常收敛的情况下,post-norm的效果更好一些;但是pre-norm更适合用于训练更深的网络。
10、对于使用Multi-Head Attention的模型,假设hidden size=D,注意力头数量为h,每个头维度为d(假设有D=d×h),输入上下文长度为s,batch size=1,计算self-attention模块各个部分的计算量(Float Operations)。
1.QKV线性变换:6 × s × D^2(矩阵乘法,每个位置有加法和乘法两个运算,因此每个位置需要2D次计算)
2.QK内积:h × 2 × d × s^2(h组矩阵分别计算)
3.scaling:h × s^2
4.softmax:h × 3 × s^2(softmax是按列进行的,每列要计算s个exp,s个exp结果的求和,以及s次除法)
5.reduction(权重矩阵乘以V):h × 2 × d × s^2
11.旋转位置编码RoPE有什么优缺点?
优点:RoPE以绝对位置编码的方式实现了相对位置编码,使得能够在不破坏注意力形式的情况下,以“加性编码”的方式让模型学习相对位置。①相比其他相对位置编码来说,实现简单,计算量少。②可以应用于线性注意力。③RoPE具有远程衰减的特性,使得每个位置天然能够更关注到附近的信息。
缺点:RoPE相比训练式的绝对位置编码具有一定的外推能力,如可以在2k数据长度训练的模型进行略长于2k的推理。但是相比于Alibi等位置编码,其直接外推能力并不算特别好,需要通过线性插值、NTK插值、YaRN等方式来优化外推能力。
12.batchnorm中的momentum怎么影响训练效果
batchnorm在训练时计算每个batch内的均值和方差用于normalization,同时统计一个全局均值和方差用于推理。全局均值和方差计算公式为:
moving_mean = momentum × moving_mean + (1.0 − momentum) × mean
moving_var = momentum × moving_var + (1.0 − momentum) × var
小的momentum值对应快的更新速度,能够更快地向真实分布靠近,但是同时也会导致更大的波动;如果更新过慢,则可能导致训练结束时还没有统计到真实的分布,是欠拟合的状态。如果batch size比较小,每个mini batch和全局差异较大,就不应该用太大的momentum。
13.多头注意力相比单头有什么好处?
多头注意力使用多个维度较低的子空间分别进行学习。
一般来说,相比单头的情况,多个头能够分别关注到不同的特征,增强了表达能力。多个头中,会有部分头能够学习到更高级的特征,并减少注意力权重对角线值过大的情况。
比如部分头关注语法信息,部分头关注知识内容,部分头关注近距离文本,部分头关注远距离文本,这样减少信息缺失,提升模型容量。
另外虽然多头注意力的整体计算量比单头要大一点,但是并行度也高一些。
14.kv cache为什么能加速推理?
对于GPT类模型,使用的是单向注意力,每个位置只能看到自己和前面的内容。
在进行自回归解码的时候,新生成的token会加入序列,一起作为下一次解码的输入。
由于单向注意力的存在,新加入的token并不会影响前面序列的计算,因此可以把已经计算过的每层的kv值保存起来,这样就节省了和本次生成无关的计算量。
通过把kv值存储在速度远快于显存的L2缓存中,可以大大减少kv值的保存和读取,这样就极大加快了模型推理的速度。
15.ReLU有什么优缺点?
优点:(1)计算快,前向只需要进行max(0, x)计算,后向则是直接透传;(2)有激活值的时候,梯度恒定为1,不会爆炸/消失;
缺点:(1)均值不为0,分布产生偏移(2)输入值小于0时,梯度再也无法回传过来,导致神经元坏死。
16.为什么Transformer用layernorm而不是batchnorm
首先,NLP数据中由于每条样本可能不一样长,会使用padding,如果对padding部分进行normalization,对效果有负面影响。直观来说,batchnorm会对同一个特征以batch为组进行归一化,而对于文本数据,同一个位置的token很可能是没有关联的两个token,对这样一组数据进行归一化没有什么实际意义。《PowerNorm: Rethinking Batch Normalization in Transformers》论文的实验也表明,在NLP数据使用batchnorm,均值和方差相对layernorm会更加震荡,因此效果欠佳。
17.transformer中,encdoer和decoder是怎么进行交互的?
decoder部分的输入,在每层中,先进行一次self-attention;之后用encoder的输出作为attention计算中的K、V,decoder的输入作为Q,进行cross-attention。
18.PyTorch中,Tensor的view()和reshape()两个方法有什么区别?
1.功能上:view()与reshape()方法都可以用来改变tensor的形状,但是使用条件不同,view()能做的是reshape的子集。
2.view()方法需要tensor满足连续性,操作后返回一个引用,返回值是视图,没有改变原储存空间的值,多个视图共享同一个物理储存空间的内容。
3.reshape()方法不需要tensor一定满足连续性。如果tensor不满足连续性的要求,则会使用新的储存空间并返回。如果满足连续性需求,则功能和view()一致。
4.连续性:比如一个二维张量,如果按行优先展开成一维的结果,和物理储存顺序是一致的,就是连续的。可以用is_contiguous()来判断一个张量是否连续,如果不连续,可以用contiguous()得到一份新空间中的连续副本。
19.RLHF中,PPO需要哪几个模型,分别是什么作用?
一般来说,PPO需要使用4个模型。
1.Actor模型:由SFT初始化,就是进行强化学习的主模型,是我们想要最终获得的模型;它不断产生action并被Critic模型所评价,计算loss进行训练。
2.Reference模型:一般也是从SFT模型初始化,RLHF中Reference模型并不更新参数,只是作为Actor模型的参考使用;通过约束Actor模型和Reference模型的KL penalty等,可以防止Actor模型被训得跑得太偏。
3.Reward模型:提前训练好的,对SFT模型进行打分的模型,RLHF中参数是冻结的。
4.Critic模型:一般由Reward模型进行初始化,参数可训练,用于预测Actor模型生成的token的收益。
20.GPT类模型训练过程中,消耗显存的主要有哪些部分?分别是多少?哪部分占用最多?假设模型有L层,词表大小为V,hidden size为H,batch size为B,训练窗口长度为S,使用Adam优化器混合精度训练(需要存一阶和二阶动量),注意力头数为N。
训练过程中,显存消耗主要有模型参数、梯度、optimizer状态值和中间激活值。
1.模型参数Φ:词表部分VH,每层参数12H2+13H,总共有Φ=VH+L(12H2+13H),如果是半精度就是2Φ
2.梯度:每个参数对应有一个梯度,总量为Φ,如果是半精度就是2Φ
3.optimizer状态值:每个参数有一个对应梯度,每个参数又对应优化器一个一阶动量和二阶动量。在混合精度训练中,使用半精度进行前向计算和梯度计算,同时优化器备份一份单精度的优化器状态、梯度和参数用于更新参数,因此共有(Φ+Φ)*2+(Φ+Φ+2Φ)*4=20Φ,除去参数和梯度,优化器占部分16Φ
4.激活值:保存激活值是为了计算梯度,因此每个矩阵相乘、softmax、dropout都需要保存输入值的中间的激活值。总共是34BSH+5BNS^2,如果都是半精度,就乘以2。
模型参数、梯度和优化器状态和输入长度无关,是固定值,而激活值随着长度增加,以平方速度增长。以GPT3(175B)为例,H=12288,L=96,N=96。模型参数量显存越为350G。以B=1计算,如果S=1024,激活值约为90G;如果S=8192,激活值约为3420G。
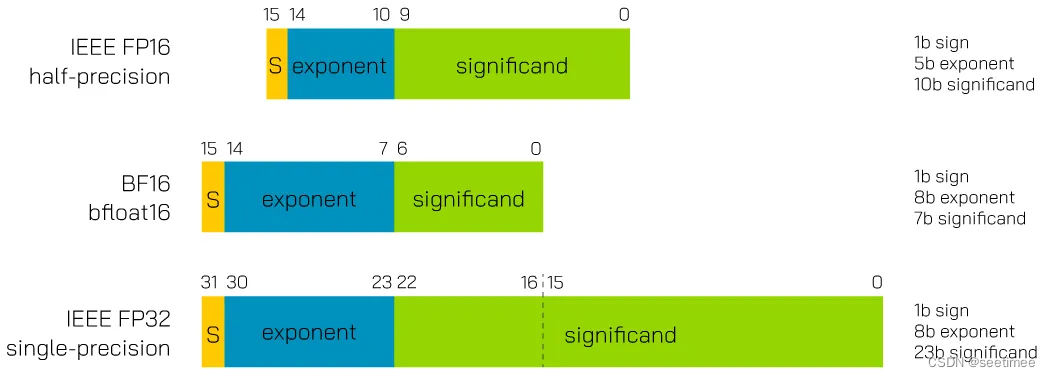
21.使用半精度训练时,bf16和fp16格式有什么异同?
二者都是占用16bit空间。
fp16由1个符号位、5个指数位和10个尾数位组成。fp16在表达小数时具有较高的精度,但表示的最大范围相对bf16比较小。相比bf16,在表达较大的数时更容易出现上溢的情况。
bf16由1个符号位、8个指数位和7个尾数位组成。相比于fp16,bf16牺牲了一些尾数位以增加指数位,扩大了表达的范围,但是精度降低了,因此对于对精度需求比较高的模型,模型可能效果不如fp16。
模型训练时使用bf16和fp16都可以降低内存使用和传输量,提高训练效率。
22.支持模型长上下文的方案「NTK-aware interpolation」的思路是什么?
1.在NTK插值之前,线性插值通过在原模型训练的两个位置编码中间,插入新的位置编码,使得同样的取值范围可以容纳更多位置。
2.而NTK插值则是一种非线性插值的方法。它通过仅改变RoPE的base,使得位置编码中不同频率的信号有不同的表现,具体来说就是“高频外推,低频内插”。高频信号使用外推,防止分辨率太低,而低频信号沿用插值的方式,实现方便。
23.LLM长度外推方案NTK-by-parts的思路是什么?
NTK-by-parts的方法在NTK插值的基础上又多想了一层。它认为无论是线性插值还是NTK-aware插值,都认为RoPE的所有分量都对网络有同样的重要性。而NTK-by-parts的思路认为,应该区别对待不同分量,他们对网络的影响有所不同。对于波长远小于上下文长度的分量(如波长<=1/32上下文),就不插值只外推;而对于波长大于等于上下文长度的分量,就只外推不插值;对于介于两者之间的分量,就使用外推和插值的加权和。
使用一个斜坡函数来定义NTK-by-parts的分段插值方法,如下所示

24.LLM长度外推方案YaRN是怎做的?
PI/NTK/NTK-by-parts主要的做法都是使用插值,而随着插值进行,token之间的距离变得更近(因为现在每一个位置旋转角度变小了),平均最小距离在减小,这样注意力softmax的分布会变得更尖,也就是都集中在某个区间。
换句话说,就是RoPE原本远距离衰减的特性变弱了,衰减得更不明显,就会导致模型更平均地关注到更多的token,这样就削弱了注意力机制,导致输出质量下降。
可以通过在softmax之前,将中间注意力矩阵乘以温度 t>1来缓解这个问题。由于RoPE被编码为一个旋转矩阵,就可以简单地给旋转矩阵乘以一个系数根号t来实现,这样可以不必修改注意力的代码。
YaRN结合NTK-by-parts和这个温度系数,对attention score进行调整。
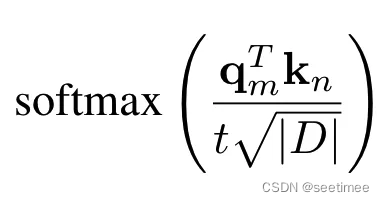
25.对于使用Group-Query Attention的模型,假设hidden size=D,Q的注意力头数量为h,每个头维度为d(假设有D=d×h),kv组数为n,输入上下文长度为s,batch size=b,模型层数为L,计算推理时kv cache所需的空间。
kv cache缓存的是经过投影变换之后的K和V矩阵。
对于GQA,每层有n组K和V,每组的特征维度和Q的每个头的特征维度相同,为D/h。则每层每组K和V数据量为sD/h,整个模型共有2LnsD/h个数据,因此整个batch需要缓存2bLnsD/h个数据。如果使用的是半精度浮点数,每个浮点需要两个字节,因此共需要4bLnsD/h字节的空间。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓