转自老贾探AI
在日常生活和工作中,我们经常面对大量本地信息资料(如PDF、Doc等),需要进行关联理解和处理。频繁地切换和区分文件格式,再加上需要跨语言理解的环境,使得如何找到一个准确、快速、可靠地处理文件的解决方案成为一项挑战。这个问题既现实又复杂,我们需要一个强大且可靠的工具来解决这个问题。
今天给大家推荐一个GitHub开源项目:netease-youdao/QAnything。该项目已经拥有超过5.8k Star,"Question and Answer based on Anything"。

QAnything介绍
QAnything (Question and Answer based on Anything) 是一个支持多种格式文件和数据库的本地知识库问答系统,可离线安装。
简单上传本地文件,即可获得准确、快速、靠谱的问答体验。
目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html)等。
特点
-
数据安全,支持断网离线安装使用;
-
支持跨语种问答,可根据文档的语种自由切换中英文问答;
-
支持海量数据问答,两阶段检索rerank,解决大规模数据检索降级问题(数据越多,效果越好);
-
高性能生产级系统,可直接私有化生产部署;
-
易用,无需繁琐配置,一键安装部署,开箱即用;
-
支持跨知识库问答。
架构
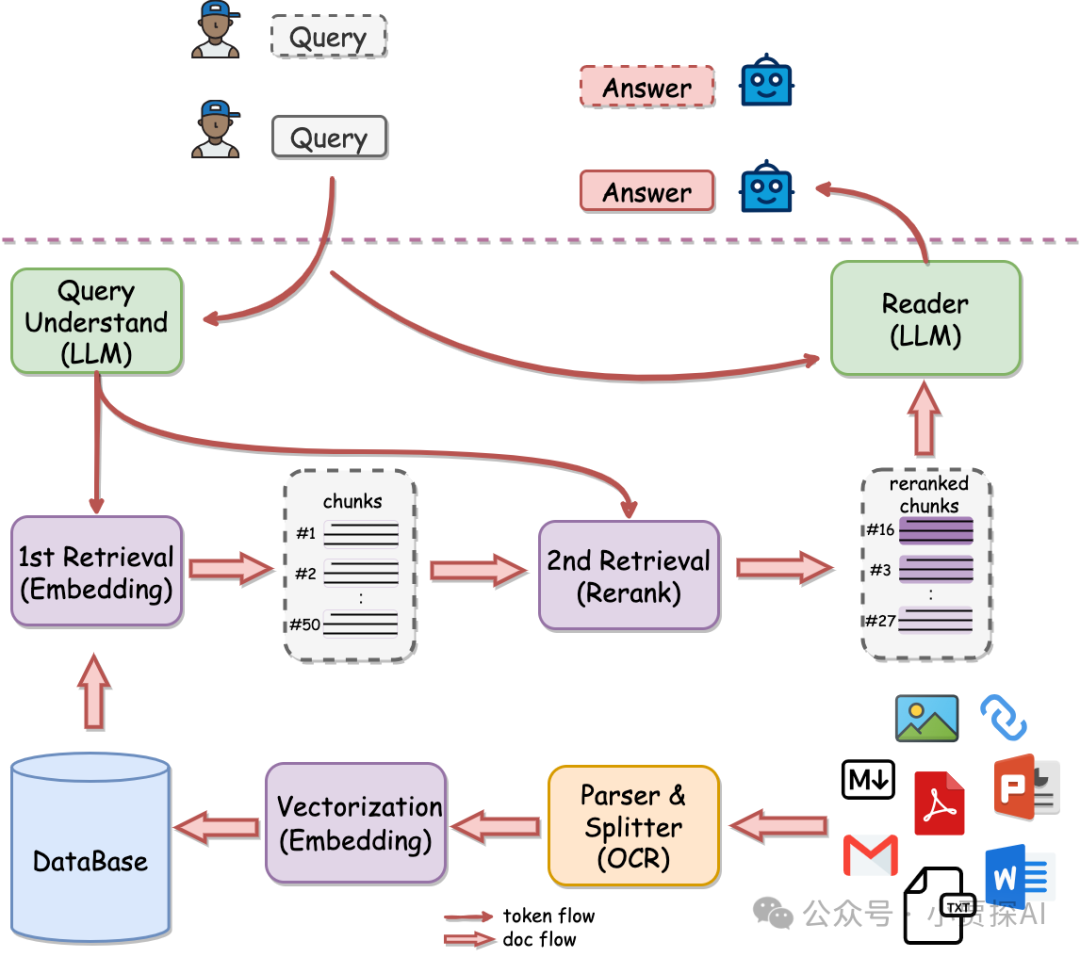
为什么是两阶段检索?
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索降级的问题。二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
QAnything使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异。
-
强大的双语和跨语种语义表征能力->基于MTEB的语义表征评测指标(https://github.com/netease-youdao/BCEmbedding/tree/master?tab=readme-ov-file#semantic-representation-evaluations-in-mteb)
-
基于LlamaIndex的RAG评测,表现SOTA->基于LlamaIndex的RAG评测指标(https://github.com/netease-youdao/BCEmbedding/tree/master?tab=readme-ov-file#rag-evaluations-in-llamaindex)
提示:
-
在WithoutReranker列中,
bce-embedding-base_v1模型优于所有其他embedding模型。 -
在固定embedding模型的情况下,
bce-reranker-base_v1模型达到了最佳表现。 -
bce-embedding-base_v1和bce-reranker-base_v1的组合是
SOTA。
LLM
开源版本QAnything的大模型基于通义千问,并在大量专业问答数据集上进行微调;在千问的基础上大大加强了问答的能力。选择一个性价比高的LLM也是很重要的。
最佳实践
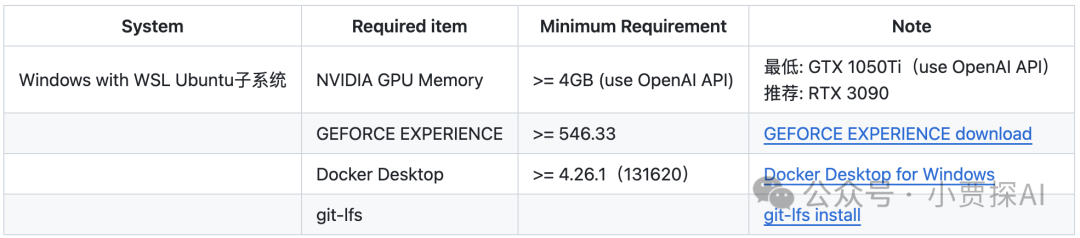
准备环境
-
Linux系统

-
Windows系统
部署安装
1: 下载项目
git clone https://github.com/netease-youdao/QAnything.git
2: 进入项目根目录执行启动脚本
cd QAnything
bash ./run.sh -h 获取详细的LLM服务配置方法
bash run.sh # 默认在0号GPU上启动
bash close.sh # 关闭服务
【注意】如果自动下载失败,可手动下载模型。
-
modelscope: https://modelscope.cn/models/netease-youdao/QAnything
-
wisemodel: https://wisemodel.cn/models/Netease_Youdao/qanything
-
huggingfase: https://huggingface.co/netease-youdao/QAnything
(可选)Linux指定单GPU启动
bash ./run.sh -c local -i 0 -b default # 指定0号GPU启动
(可选)Windows指定单GPU启动 - 推荐 Windows10/Windows11 WSL2
# 注意: Windows系统请先进入**WSL2**环境
# Step 1. 下载开源 LLM 模型 (Qwen-7B-QAnything) 并保存在路径 "/path/to/QAnything/assets/custom_models
# (可选) 从 ModelScope 下载 Qwen-7B-QAnything: https://www.modelscope.cn/models/netease-youdao/Qwen-7B-QAnything
# (可选) 从 Huggingface 下载 Qwen-7B-QAnything: https://huggingface.co/netease-youdao/Qwen-7B-QAnything
cd QAnything/assets/custom_models
git clone https://huggingface.co/netease-youdao/Qwen-7B-QAnything
# Step 2. 执行启动命令,其中"-b hf"表示指定使用 Huggingface transformers 后端运行 LLM.
cd ../..
bash ./run.sh -c local -i 0 -b hf -m Qwen-7B-QAnything -t qwen-7b-qanything
(可选)指定单GPU启动 - 推荐 GPU Compute Capability >= 8.6 && VRAM >= 24GB
# 查看 GPU 算力 GPU Compute Capability:
https://developer.nvidia.com/cuda-gpus
# Step 1. 下载开源 LLM 模型 (Qwen-7B-QAnything) 并保存在路径 "/path/to/QAnything/assets/custom_models"
# (可选) 从 ModelScope 下载 Qwen-7B-QAnything: https://www.modelscope.cn/models/netease-youdao/Qwen-7B-QAnything
# (可选) 从 Huggingface 下载 Qwen-7B-QAnything: https://huggingface.co/netease-youdao/Qwen-7B-QAnything
cd QAnything/assets/custom_models
git clone https://huggingface.co/netease-youdao/Qwen-7B-QAnything
# Step 2. 执行启动命令,其中"-b vllm"表示指定使用 vllm 后端运行 LLM.
cd ../..
bash ./run.sh -c local -i 0 -b vllm -m Qwen-7B-QAnything -t qwen-7b-qanything -p 1 -r 0.85
(可选)指定多GPU启动
bash ./run.sh -c local -i 0,1 -b default # 指定0,1号GPU启动,最多支持两张卡启动
windows断网安装
# 先联网下载docker镜像
docker pull quay.io/coreos/etcd:v3.5.5
docker pull minio/minio:RELEASE.2023-03-20T20-16-18Z
docker pull milvusdb/milvus:v2.3.4
docker pull mysql:latest
docker pull freeren/qanything-win:v1.2.1
# 导出镜像
docker save quay.io/coreos/etcd:v3.5.5 minio/minio:RELEASE.2023-03-20T20-16-18Z milvusdb/milvus:v2.3.4 mysql:latest freeren/qanything-win:v1.2.1 -o qanything_offline.tar
# 下载QAnything代码
wget https://github.com/netease-youdao/QAnything/archive/refs/heads/master.zip
# 把镜像qanything_offline.tar和代码QAnything-master.zip拷贝到断网机器上
cp QAnything-master.zip qanything_offline.tar /path/to/your/offline/machine
# 在断网机器上加载镜像
docker load -i qanything_offline.tar
# 解压代码,运行
unzip QAnything-master.zip
cd QAnything-master
bash run.sh
Linux断网安装
# 先联网下载docker镜像
docker pull quay.io/coreos/etcd:v3.5.5
docker pull minio/minio:RELEASE.2023-03-20T20-16-18Z
docker pull milvusdb/milvus:v2.3.4
docker pull mysql:latest
docker pull freeren/qanything:v1.2.1
# 导出镜像
docker save quay.io/coreos/etcd:v3.5.5 minio/minio:RELEASE.2023-03-20T20-16-18Z milvusdb/milvus:v2.3.4 mysql:latest freeren/qanything:v1.2.1 -o qanything_offline.tar
# 下载QAnything代码
wget https://github.com/netease-youdao/QAnything/archive/refs/heads/master.zip
# 把镜像qanything_offline.tar和代码QAnything-master.zip拷贝到断网机器上
cp QAnything-master.zip qanything_offline.tar /path/to/your/offline/machine
# 在断网机器上加载镜像
docker load -i qanything_offline.tar
# 解压代码,运行
unzip QAnything-master.zip
cd QAnything-master
bash run.sh
开始体验
1、前端地址: http://${host}:5052/qanything/
2、API 接口地址: http://${host}:8777/api/
3、相关日志:QAnything/logs/debug_logs目录下的日志文件。
-
debug.log
-
用户请求处理日志
-
-
sanic_api.log
-
后端服务运行日志
-
-
llm_embed_rerank_tritonserver.log(单卡部署)
-
LLM embedding和rerank tritonserver服务启动日志
-
-
llm_tritonserver.log(多卡部署)
-
LLM tritonserver服务启动日志
-
-
embed_rerank_tritonserver.log(多卡部署或使用openai接口)
-
embedding和rerank tritonserver服务启动日志
-
-
rerank_server.log
-
rerank服务运行日志
-
-
ocr_server.log
-
OCR服务运行日志
-
-
npm_server.log
-
前端服务运行日志
-
-
llm_server_entrypoint.log
-
LLM中转服务运行日志
-
-
fastchat_logs/*.log
-
FastChat服务运行日志
-
部署FAQ
FAQ快链:https://github.com/netease-youdao/QAnything/blob/master/FAQ_zh.md
相关技术组件
-
BCEmbedding
-
Triton Inference Server
-
vllm
-
FastChat
-
FasterTransformer
-
Langchain
-
Langchain-Chatchat
-
Milvus
-
PaddleOCR
-
Sanic
引用
-
https://github.com/netease-youdao/QAnything