【Datawhale AI夏令营第四期】魔搭-AIGC方向 Task02笔记
Task02学习任务:
https://linklearner.com/activity/14/10/32
传送门
我们继续看网课,并且在Kimi.AI的帮助下读一下BaseLine示例代码。
网课链接:https://space.bilibili.com/1069874770/channel/collectiondetail?sid=3369551
传送门
课程PPT资料链接:
https://www.modelscope.cn/headlines/article/537?from=blibli_video
2.1Scepter与WebUI,一站式生成编辑工具箱

当前有的文生图、文生视频模型,可控生成和编辑工具、模型微调方法:

模型细节部分我不太能听懂,但我觉得老师介绍得应该都是核心实用的知识。这方面有天赋的同学可以多看看,再搜源代码和论文。

这个整合工具箱看起来不错,更适合关注效果的新手小白,我会着重看看这个工具能做什么。

图片数据处理的能力好像还挺强大的,也许能当个不错的白嫖工具。
官网链接: :https://modelscope.cn/studios/iic/scepter_studio
传送门
Github链接: https://github.com/modelscope/scepter
传送门
能做数据集,能文生图,能处理图像,本质上就是可以根据现有图片做数据集,或者不够的话AI生成来凑?那也许可以猜测,这次AIGC夏令营的BaseLine的数据集里面有大量AI生成的图片,可以理解为靠这个工具也可以做出吗?

还可以微调现有的基础大模型:

对训练好的模型也支持管理和分享:

支持使用本地或下载好的模型:


可以手动添加一些Mask、蒙版之类的,把图片里面不需要的元素替换掉。
下面这个虚拟试衣,划重点。之前我上了一个免费的AIGC体验课(培训班卖课性质),当时给我看的他们学员作品集里面,就有很多是AI模特虚拟试衣的,这个也同样适合电商网络平台运营,因为能大量节约请模特甚至主播的成本。(之前看B站上有个up分享说谁拿纯AI开了个虚拟淘宝店,还挺有意思)

看这个系列课程后面好像有一课是专门介绍虚拟试衣的,期待住了:

2.2ComfyUI应用场景探索
这也是BOSS直聘上老出现的一个词,之前的BaseLine学习手册里面也有简单介绍。

随着社群的开发,现在视频和声音生成也是指日可待了。

ComfyUI Github地址 :https://github.com/comfyanonymous/ComfyUI
传送门


Windows用户需要使用也很容易:

因为我个人学习的目的主要是掌握使用工具,所以模型细节我这里就不过多阐释了,感兴趣的朋友可以根据视频自行查找资料。

老师手把手教了该怎么在云端平台部署ComfyUI,但他好像并没提供教程源代码……
不过我灵机一动,在Github上翻到了!
老师的ComfyUI示例代码:
https://github.com/modelscope/modelscope-classroom/blob/main/AIGC-tutorial/comfyui_modelscope.ipynb
传送门

还找到了这个系列教程的其他源代码文件库:
https://github.com/modelscope/modelscope-classroom/tree/main
传送门


补充一点,B站上关于ComfyUI的教程貌似还挺多,秋叶大佬也早就放出来了一键整合包:
百度网盘链接: https://pan.baidu.com/share/init?surl=e-wb3UjxybMBDYhZCKyyLQ&pwd=8ra2
传送门

之前还有个webUI的整合包:
原视频:https://www.bilibili.com/video/BV1iM4y1y7oA/?vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门
【整合包下载链接】
百度盘: https://pan.baidu.com/s/1MjO3CpsIvTQIDXplhE0-OA 提取码: aaki
夸克: https://pan.quark.cn/s/2c832199b09b
模型包链接: https://pan.baidu.com/s/1W-UIuOww38HrIjNWqPh0Rw 提取码:aaki
但是下载之前千万要保证电脑空间足够,否则就算跟我一样开了百度网盘VVVVVVVIP,都拉不下来……这也是为什么我一直没有尝试的机会,电脑配置带不动啊。
说回这个网课,老师跑的示例打开以后,我感觉和Unreal游戏引擎的蓝图连线差不多……

从老师的这几步操作来看,我认为如果单纯用现有的功能的话,难度远不如Unreal(Unreal一堆蓝图文件变量来来回回要找半天,找BUG更是把人眼睛都看花,这也是为什么我学习的时候坚决选择了Unity……)
但如果要搞这个自定义节点,自己写python代码实现一些功能的话,还是有些难度的。这个事情我不知道能不能类比给3dmax,maya啥的写插件?还是更像给Unity UGUI做一些调色盘、拿起物体交互这类的进阶功能?我从来没有做过这样的事情,感觉很高级很厉害。

我应该一时半会还用不到这么高级先进的功能,先放这里留个印象吧,以后真不会写了再来细看。

我找到了老师的示例代码,照葫芦画瓢一跑,出师不利,不嘻嘻。

那我就自己把代码下下来给程序吧。

但是即便我把压缩包上传,再通过下面的代码解压到工作目录,最后再把名字改成ComfyUI,都还是跑不起来。
import os
import zipfile
# 遍历当前目录下的所有文件,把上传的压缩包解压到工作目录
for filename in os.listdir("/mnt/workspace/"):
file_path = "/mnt/workspace/ComfyUI-master.zip"
# 使用zipfile模块打开ZIP文件
with zipfile.ZipFile(file_path, 'r') as zip_ref:
# 解压ZIP文件到当前目录
zip_ref.extractall("/mnt/workspace/")
print(f'Extracted {filename} to {current_directory}')

最后URL出来了,但是Run ComfyUI with cloudflared (Recommended Way)这样的话会网页打不开……666


仔细一看,原来老师放出的代码里面没有保留着部分在云端跑需要下载工具的代码:
!wget "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/cloudflared-linux-amd64.deb"
!dpkg -i cloudflared-linux-amd64.deb

但是装了这种方式我还是无法访问……
上网一查这个问题有点超出我的理解范围……先放个帖子在这吧。
《Cloudflare找不到服务器 IP 地址》:
https://blog.csdn.net/Pythonwill/article/details/128570179
传送门
墙得看来很彻底,人在中国香港都访问不了。

至于第二种方法……更加炸裂,这机子上装不了npm。

在本地跑也是各类环境兼容问题,倒腾半天还是没跑上,心累……
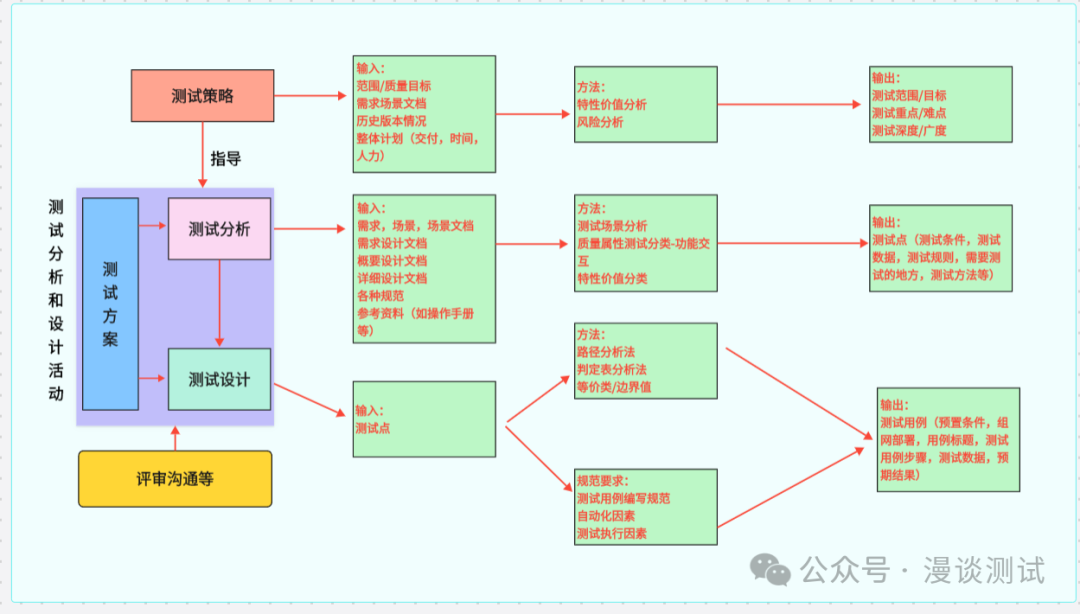
3.1画质修复增强技术及应用


检测低质量因素,修复为高质量。根据不同任务的需要构造不同的数据集,就可以训练出针对不同任务的模型。

训练过程:构造数据然后去生产能实现任务的模型。
推理过程:将输入转换为需要的输出。

三大技术板块:
1.空间域增强。可理解为清晰度、画面质量的提升。(针对单帧、像素级效果,比如差分去噪,修复去划痕)
2.色彩增强。色彩变好,黑白到彩色
3.时间域增强。抖动调稳,闪烁和卡顿平滑。
中间的画质评估。指导,用来衡量修复增强的好坏效果。

下面老师介绍了一些新技术和案例:



通用的修复会面对各种各样的场景(自然、建筑等),但是人像有很强的先验知识(人的五官排布和这些数据的格式非常接近),用于指导生成网络去生成。所以能将人脸增强的部分做得特别突出,结合到通用场景超分里面,再配合一些额外后处理工作,得到整体效果好的输出结果。

原来提高清晰度、老片修复这些用的是不同的模型?我一开始还以为是一个大模型能拿捏所有。

智能插帧:将25的帧率变道100、120这种。通过瑕疵对比和动态补偿来避免畸变。

手持相机抖动处理——帧和帧之间的画面没对齐。

图像上色:黑白变彩色。但这种上色方案有很多,红的可以黄的也可以。他们提出了一种无需参考而且出图片效果更好看的方法。
只用生成的颜色信息贴在旧图上面,避免生成颜色的过程中破坏原图的物理结构和形状。



画质分析不仅可以用于评价,还可以用于前处理的指导(运用哪种能力来修复?)——可以前置和后置地去影响修复过程。

感觉这个视频主要还是在介绍现有的成果展示,但是没有怎么讲该如何具体应用。如果不是执着算法的话粗略看看就好。



下面这个模型放在了他们官网上,可以体验。

优势:可以通过prompt、手工涂抹等控制生成的颜色等条件。
这里举例子提到了WebUI,也是老关键词了。

以前通过GAN模型上色是不好控制不自然的,有溢色效应,现在有了扩散模型的上色技术,可以通过手工的少量标注来指导模型哪里该上什么颜色。(比如绿草、蓝天)带来更大的灵活性和更好的上色效果。

黑白视频变成彩色,除了一帧一帧上色之外,还有一个简单高效的方法:首先将视频进行一遍粗的修复,再通过镜头检测分成不同的片段。
每一段里面保证了从头到尾是一个镜头,这样帧与帧之间的相似度就会非常高。
再针对一段视频里面选择一些关键帧作为参考帧,然后只需要对这些参考帧进行前面的交互式上色,得到一个合理自然的彩色参考帧。
然后将这个帧应用到整个片段里面,自动化地逐帧上色完成。
这样能得到一个时序性更好,又能保证图像上色合理性和质量的结果。

将这些技术结合起来,就可以做基于AIGC扩散修复的技术。
先从低质量(黑白)图像经过扩散超分生成高质量(黑白)图像。
在同样是黑白图像 的过程中,通过交互式上色去得到最终颜色合理、清晰度更高、整体更加自然、更符合用户需求的修复后图像。
总体来讲,有了AIGC以后,在扩散增强技术上面,相比以前旧的CNN和Transformer领域有了更多的可控性、更高的灵活性和更好的多样性。

课后作业&体验链接:

我拿自己之前随手拍的学校照片试了下水:
(这张照片还是最后一天离开香港前,在学校上自习拍的,好怀念啊)

第一个链接出师不利翻车了:
https://modelscope.cn/studios/vigen/DreaMoving_Phantom

第二个体验链接看着还行:
https://modelscope.cn/studios/iic/old_photo_restoration
(选了重新上色)
(不选重新上色)

精读BaseLine代码:
在我装环境本地跑的时候,那个data_juicer库始终都没法适配本地环境,哪怕是新建虚拟环境也不行。

不过问题不大,其实data_juicer只影响很小一部分的代码,只要在官方提供的平台跑成功了,把这一步需要的文件下载下来丢进对应目录就行了。但我最后还是没有在本地跑,因为下载模型实在是太慢了。

如果不放心的话,把云端服务器上output目录下所有文件都Download下来就OK。

模型训练这部分的参数:

可以把这个传长参数的写法留意一下,跑Github的一些项目(比如我第一篇读的人工智能论文AODA)经常会看到这样的形式:
在编写命令行参数时,-- 用于长格式的选项,而 \ 在这个上下文中是用作字符串的续行符,而不是命令行语法的一部分。在Python的多行字符串中,你可以使用 \ 来继续下一行的字符串,这样可以使代码更加可读。

然后就是加载模型这部分的代码:这段Python代码演示了如何使用diffsynth库和peft库来加载和配置一个包含LoRA(Low-Rank Adaptation)适配器的模型,以及如何创建一个图像处理管道。


找工作关键词LORA:
这就提到一个重要概念,也是BOSS直聘触发的关键词——Lora了。
很懵逼吗?没关系,鞭策一下Kimi,让它解释得简明扼要一些。

一句话概括:针对新需求部分微调。

(不得不说AI真的很大程度上实现了教育公平和学习便捷啊!Kimi看的很多参考资料我自己都不知道从哪找的。最近我看很多AI教育软件也很流行,比如callannie、replika、talkbuddy之类的AI教英语的app,我觉得这个如果能做出来的话特别好,可以避免私教的高额费用,还能让我蹩脚的英语发音说的时候不那么尴尬,而且随时随地无需预约想学就学!)
生成图像的代码:
如果是对编程细节不感兴趣的话,把下面这几个参数看懂完全够了,就跟AI绘画平台似的,正向提示词,反向提示词,图片大小。对人工智能有了解的可以再调配置尺度和迭代次数试试。


同时善良的Kimi还帮我们找出了一些其他可调的参数,但目前我看来用处都不大?

希望每次跑代码都出新图不要重复:
这个是我一直都很疑惑的问题,每次生成的图片都是一样的,这很奇怪,之前就根据经验猜测是随机种子导致的,今天问了Kimi果然如此!

这下每次生成的图可以不一样了,哈哈哈哈哈哈!!!!!
只需要把这行代码删改了即可:

如果新图点击半天看到的还是旧图的话,试试按界面上的刷新,并且把现在打开的旧图预览窗口关上。
打开已有实例,用相同提示词生成新图片:
以及,如果之前跑完过全流程的话,下次开实例想跑新图的话,直接从【加载模型】这一部步骤开始继续运行就好了!不用再忍受漫长的装环境下载数据集的过程!!!!
下一步就是运行提示词那个代码块直接生成就好了!

官网评分代码使用:
参加比赛以后,我还在官网上发现了评分代码。
https://modelscope.cn/brand/view/Kolors?branch=0&tree=0
传送门
研究了一下怎么用:


经过研读代码,我们发现参数是传入包含想要评分图片的文件夹,最后会返回这个文件夹里面所有图片的平均得分。


我能理解为这个美学评分代码可以拿出来单独用,然后可以不停当各种图的打分工具人吗?
可惜我还没有找到详细的评分标准,不知道满分上限是多少/分越高还是越低越好,不嘻嘻。
添加了注释的BaseLine、还有一些本地跳步骤运行需要的文件(我电脑data_juicer跑不通)我会放在个人的CSDN资源库,有需要的朋友可以借鉴。个别路径我按照自己电脑改了一下,如果报错的话就按照官方版的改回来就可以。


在阅读学习手册的时候,发现了这有个DeepFake竞赛:
https://datawhaler.feishu.cn/wiki/Uou8w9igsibGP7kduiycCgesnOh
添加链接描述
这个事情我自己本身之前没有做过,但是我们同学有人小组课程项目做了一个能识别上传的照片是真脸还是假脸的小程序,我找这个组的同学把他们学习小程序开发的教程要来了,还没来得及仔细研究。(但我很遗憾不知道他们用到的啥技术做的真假人脸检测)
《小白也可以开发微信小程序(入门篇)》: https://zhuanlan.zhihu.com/p/183551698#?utm_source=wechat_session&utm_medium=social&wechatShare=1&s_r=0
传送门


AI与恐怖谷效应:

所以就不像人的不吓人,倒像不像的最吓人。

调教AI学会画手的办法:采用的详细标出每个手指的方式让其学会手的结构。


观察鉴别“AI味”的方向:

可图平台的AIGC学习资源:

Kolors(可图)模型(点击即可跳转魔搭模型介绍页) 是快手开源的文本到图像生成模型,该模型具有对英语和汉语的深刻理解,并能够生成高质量、逼真的图像。
代码开源链接:https://github.com/Kwai-Kolors/Kolors
模型开源链接:https://modelscope.cn/models/Kwai-Kolors/Kolors
技术报告链接:https://github.com/Kwai-Kolors/Kolors/blob/master/imgs/Kolors_paper.pdf
魔搭研习社最佳实践说明:https://www.modelscope.cn/learn/575?pid=543
可图优质咒语书:
https://modelscope.cn/datasets/modelscope/Kolors_awesome_prompts/dataPeview
不知道这个能否画我的棉花娃娃呆呆:

创意海报生成工具:
我很久以前想过做香港主题的小红书海报,但是之前帮在职同学体验试用的AI(比如Lumi)生成的都不太让我满意,其中一个BUG就是文字生成效果太差,甚至有的都不能算是字。


这个创意海报生成工具让我看到了一点希望:https://modelscope.cn/studios/iic/PosterGenius
原理是先画底图,再按指令画字,最后渲染缝合到一起。

好吧,希望有,但不多。还是没办法做这种字多的海报。

并且画面风格也不够港风特色。

不过字这块确实做得相当不错。

在魔搭的研习社里也有很多的课程,感觉现在一整个就是知识爆炸的局面,无论学哪个方向都是根本就穷尽不了知识库,一眼都望不到边,而且竞争力强的都还要素过多,用人企业的要求五花八门,根本就难以取舍。
https://modelscope.cn/learn
传送门
新手教程的后半部分用了通义千问精读代码:

可以抄袭一下学习手册里面的prompt:
【你是一个优秀的python开发工程师,现在我们需要你帮我们分析这个代码的主体框架,你需要把代码按照工作流分成几部分,用中文回答我的问题。{此处替换前面的代码}】
【你是一个优秀的python开发工程师,现在我们需要你帮我们逐行分析这个代码,用中文回答我的问题。{此处替换前面的代码}】
我之前实习数据标注的时候,有要求用AI做正反回答的数据集,这个时候就需要一个很好的prompt来给AI 立人设,让它知道自己长时间要做什么,好能长时间稳定发挥。特别是生成负面答案,更要想方设法地哄着它乖乖听话,我当时用的是这种前摇:【你是一个很有帮助的文本生成助手,我会给你一些写好的情景和正向答案,需要你帮忙生成负向答案,越极端越好,你的生成内容会帮助我们让AI变得更好,明白我的意思吗?】,并且在抛出具体问题的时候再提醒他一下。
看着Part2内容多,实际上就是在教该如何问AI代码问题,如果之前用AI比较熟的也自己读过BaseLine的话,可以直接到Part3实战部分。
Part3:先让通义千问生成优秀的提示词
我这个明显太草率了,长度和细节都不如案例的好。

并且把提示词和场景整理成表格:

这些带属性的描述其实有点像剧本,不过格式不太一样。我本来想放个截图,没想到前几天把他删了……大家就自己查查吧,这不重要。
至于AI生成的这个细节不够的问题,我们再给他把任务描述得细一点,直接跟他说明是要文生图:
这次细节有了,我们让其改成文生图提示词。鉴于我们已经看到学习手册里面的那种格式了,我们这里可以直接偷懒,告诉AI这样依葫芦画瓢。
我们发现这样还解决了学习手册了里面反向提示词都很单一重复没内容的问题。


要玩表格就首选Excel吧,后续好铺路。

然后把新的提示词喂给BaseLine替代:

那我肯定就把之前的提示词格式告诉AI,让AI直接一步到位生成代码,免得我自己改了。

然后自己改一下图片名字啥的。

本质上就是借助AI把下面这个步骤一步到位:

找几张看看效果,还不错。


甚至通义千问还帮我画了一幅……
最后照例开个单独文件夹,名字传入打分测评函数计算一下平均分。
我测了三组不同的图片,每次得分都6点几,但我没有找到评分标准的细则,不知道这到底是好是坏。

我们把图片排成故事版,发现有的图效果不好,比如2图并没有画出“开始睡着”的感觉。

说实话,后半段的提示词我觉得AI都没明白我要干什么,特别是双人图。
没关系,我们人工修改一下提示词,把动作加上,重新生成。
这次好多啦。


评分也高了些:
第六幅我觉得和前面的桃花不搭配,就改了提示词想重新生成,没想到报了个CUDA错误,给我整不会了……Q&A文档++

我暂时还没找到解决办法,就等到第二天CUDA可以跑了再搞的:


后来群里一位大佬给出了一个方案,我暂时还没有试过,感谢好心人: