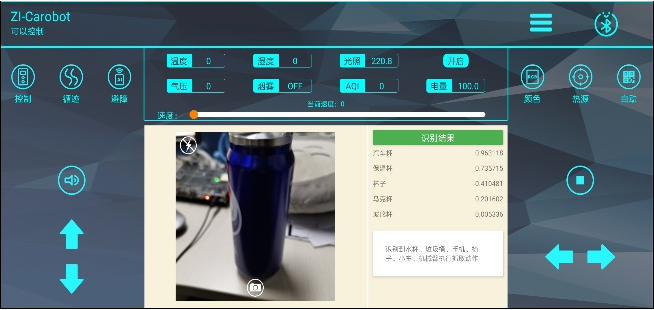
MatAdd算法
实现两个矩阵对应元素相加

MatAdd算法的GPU实现
- CPU端为输入矩阵A和B、输出矩阵C分配空间,并进行初始化
- CPU端分配设备端内存,并将A和B传输到GPU上
- 定义数据和线程的映射关系,并确定线程的开启数量和组织方式
- 每个线程负责输出矩阵C的一个元素的计算,全局ID为(i,j)的线程计算索引为(i,j)的矩阵元素
- 当矩阵规模为width*height时,共开启width * height个线程
- 每个block包含256个线程,采用(16,16)的组织形式
- 编写计算kernel,完成计算任务
- CPU端将计算结果从Device内存拷贝到Host内存
MatAdd算法的GPU实现

内存分配 数据传输

开启线程 启动kernel 结果返回

GPU kernel
CUDA程序编译


CUDA程序性能测试
使用 CUDA GPU Timers 实际要循环100次求平均值
使用 CPU Timers 实际要循环100次求平均值
 MatAdd程序之变一:每个线程处理4个元素
MatAdd程序之变一:每个线程处理4个元素
- CPU端为输入矩阵A和B、输出矩阵C分配空间,并进行初始化
- CPU端分配设备端内存,并将A和B传输到GPU上
- 定义数据和线程的映射关系,并确定线程的开启数量和组织方式
- 每个线程负责输出矩阵C的四个元素的计算,全局ID为(i,j)的线程计算索引为(i,4*j~4*j+3)的矩阵元素
- 当矩阵规模为width*height时,共开启width/4 * height个线程
- 每个block包含256个线程,采用(16,16)的组织形式
- 编写计算kernel,完成计算任务
- CPU端将计算结果从Device内存拷贝到Host内存


MatAdd程序之变二
矩阵A、B、C都为NxN的方阵,A和B为已知矩阵,C[i][j] = A[i][j] + B[j][i]。


- CPU端为输入矩阵A和B、输出矩阵C分配空间,并进行初始化
- CPU端分配设备端内存,并将A和B传输到GPU上
- 定义数据和线程的映射关系,并确定线程的开启数量和组织方式
- 每个线程负责输出矩阵C的一个元素的计算,全局ID为(i,j)的线程计算索引为(i,j)的矩阵元素
- 当矩阵规模为width*height时,共开启width * height个线程
- 每个block包含256个线程,采用(16,16)的组织形式
- 编写计算kernel,完成计算任务
- CPU端将计算结果从Device内存拷贝到Host内存

MatAdd程序之变三
- 矩阵A、B都为MxN的矩阵,矩阵C为(M/2)*(N/2)的矩阵, A和B为已知矩阵,C[i][j] = A[2*i][2*j] *B[2*i][2*j] + A[2*i][2*j+1] *B[2*i][2*j+1] + A[2*i+1][2*j] *B[2*i+1][2*j] + A[2*i+1][2*j +1] *B[2*i+1][2*j+1] 。
 CPU端为输入矩阵A和B、输出矩阵C分配空间,并进行初始化
CPU端为输入矩阵A和B、输出矩阵C分配空间,并进行初始化 - CPU端分配设备端内存,并将A和B传输到GPU上
- 定义数据和线程的映射关系,并确定线程的开启数量和组织方式
- 每个线程负责输出矩阵C的一个元素的计算,全局ID为(i,j)的线程计算索引为(i,j)的矩阵元素
- 当矩阵规模为(M/2)*(N/2)时,共开启(M/2)*(N/2)个线程,每个线程对应A和B的四个元素
- 每个block包含256个线程,采用(16,16)的组织形式
- 编写计算kernel,完成计算任务
- CPU端将计算结果从Device内存拷贝到Host内存

- 异构计算整成为当前计算领域的重点方向
- GPGPU是异构计算的主要形式
- GPGPU是一款大规模细粒度并行处理器,并行思维是进行GPGPU编程的重要前提
- NVIDIA是当前GPGPU领域当之无愧的霸主
- GPGPU编程的重点是定义明确的线程和数据间的映射