目录
1. 目的
2. 概念解释
2.1 计算并行度
2.2 超参数
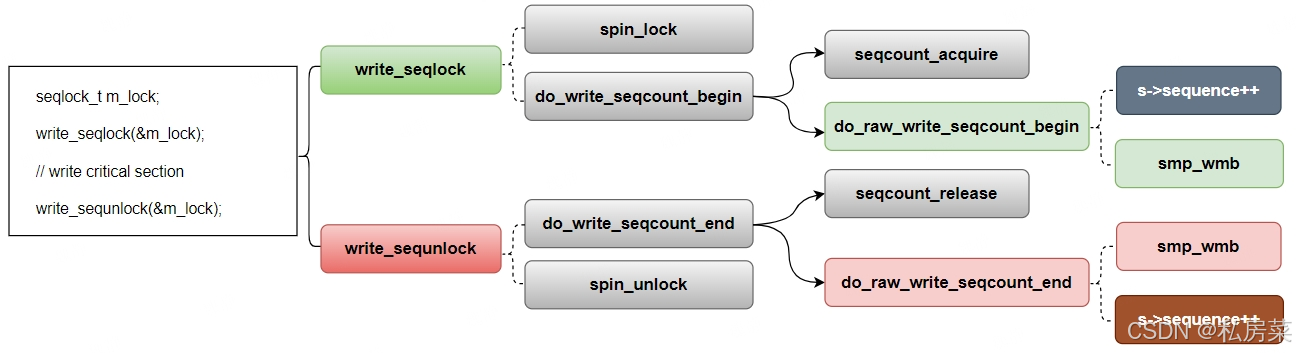
2.3 反向传播算法
2.4 优化器(Optimizer)
2.5 评估指标(Metrics)
2.5.1 准确率、精确率、召回率
2.5.2 F1 Score
2.5.3 IoU
2.6 内存布局
2.6.1 输入
2.6.2 中间结果
2.6.3权重
2.7 CNN 参数量与层数
3. Tiny-VGG
3.1 构建模型
3.2 模型详细参数
3.3 可视化结构图
4. Resnet18
4.1 模型详细参数
4.2 ResNet18的层数
4.3 极简残差网络
5. 总结
1. 目的
- 分享一个名为 CNN Explainer 的交互式可视化系统,该系统通过直观的方式展示了CNN的工作原理,读者很容易理解复杂的神经网络结构和运算过程。
CNN ExplainerAn interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs).![]() https://poloclub.github.io/cnn-explainer/
https://poloclub.github.io/cnn-explainer/
- 理解一些CNN的常用概念:优化器(Optimizer)、损失函数(Loss function)、评估指标(Metrics)、反向传播算法、权重系数、计算图。
- 通过具体的实例分析了Tiny-VGG和ResNet18模型,展示了如何构建和优化这些网络架构。
2. 概念解释
2.1 计算并行度
在 DPUCZDX8G 卷积架构中有 3 个维度的并行度:
- 像素并行度(Pixel Parallel, PP)
- 输入通道并行度(Input Channel Parallel, ICP)
- 输出通道并行度(Output Channel Parallel, OCP)
输入通道并行度始终等于输出通道并行度。

理解三个维度的并行度(ICP=3,OCP=3,PP=2):

对于上图的详细解释:
- ICP:此 CNN 第一层有3个通道(RGB),如果 DPU 的 ICP=3(支持3个并行数),那么单周期内同时执行三个通道的乘法运算;如果 DPU 的 ICP=8,那么第一层并没有完全利用 DPU 的并行算力。
- OCP:此 CNN 的输出有三个 kernel,意味着有三个输出通道;如果 OCP=3,那么三个输出通道并行计算。
- PP:每个 pixcel 都会一次或者多次参与卷积运算,DPU 每次处理的pixel数量。
- 虚线框内表示每周期同时执行的操作。
- 卷积阵列都会执行一次乘法和一次累加,这计作 2 次运算。每个周期的峰值运算数量等于PP*ICP*OCP*2。
2.2 超参数
卷积神经网络(CNN)中的超参数是指在训练过程中需要手动设置的参数,而不是通过训练数据自动学习得到的参数。以下是一些常见的超参数及其作用:
学习率(Learning Rate):
- 作用:控制每次更新模型参数时步长的大小。学习率过大可能导致训练过程不稳定,学习率过小则可能导致收敛速度过慢。
批次大小(Batch Size):
- 作用:决定每次迭代时使用的训练样本数量。较大的批次大小可以更稳定地更新参数,但需要更多的内存;较小的批次大小则可以更频繁地更新参数。
迭代次数(Epochs):
- 作用:指整个训练集被输入到模型中进行训练的次数。更多的迭代次数可以让模型更充分地学习,但也可能导致过拟合。
卷积核大小(Kernel Size):
- 作用:决定卷积操作中滤波器的大小。较小的卷积核可以捕捉到更细微的特征,而较大的卷积核则可以捕捉到更全局的特征。
卷积核数量(Number of Filters):
- 作用:决定每一层卷积层中滤波器的数量。更多的滤波器可以捕捉到更多的特征,但也会增加计算量。
步长(Stride):
- 作用:决定卷积核在输入图像上移动的步长。较大的步长会减少输出特征图的尺寸,而较小的步长则会保留更多的细节信息。
填充(Padding):
- 作用:在输入图像的边缘添加额外的像素,以控制输出特征图的尺寸。常见的填充方式有“valid”(无填充)和“same”(填充使输出尺寸与输入相同)。
激活函数(Activation Function):
- 作用:决定每个神经元的输出。常用的激活函数有ReLU、Sigmoid和Tanh等。
优化器(Optimizer):
- 作用:决定如何更新模型的参数。常用的优化器有SGD、Adam、RMSprop等。
CNN ExplainerAn interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs).![]() https://poloclub.github.io/cnn-explainer/
https://poloclub.github.io/cnn-explainer/

2.3 反向传播算法
通过一个简单的线性拟合的例子进行说明:
- 输入:x
- 权重:w, b
- 输出:y = wx + b
- 损失函数:
- t为真实值,比如该线性函数需要经过点(1.5, 0.8),则x=1.5,t=0.8

我们的目的是要更新权重系数w,b,为此,我们进行如下操作:
1. 权重初始化(随机生成):w=0.8,b=0.2
2. 第一次迭代:输入x=1.5,t=0.8,则经过计算y=1.4,L=0.18
3. 如图,利用链式法则,计算L对w的偏导:
4. 同样,计算L对b的偏导:
5. 学习率设为r=0.1
6. 更新权重
7. 更新权重
8. 更新权重后,y=1.205,L=0.082,y更接近真实值0.8,而损失函数也变小了
观察黄色箭头,这种从后向前计算梯度的方法,就是反向传播算法。
下图是一个稍微复杂一点的计算过程,核心思路是一致的:

2.4 优化器(Optimizer)
随机梯度下降(SGD):
- 基本思想:在每一步使用一批数据计算梯度,并用这个梯度更新模型参数。
- 特点:
- 简单易实现。
- 容易陷入局部最小值或鞍点。
带动量的SGD(Momentum SGD):
- 基本思想:引入“动量”概念,通过累积过去梯度的指数衰减平均来调整更新方向,使其更加平滑。
- 特点:
- 可以更快地收敛。
- 动量项可以帮助克服SGD的停滞问题。
自适应学习率优化器(如Adagrad, RMSprop, Adam):
- Adagrad:
- 基本思想:为每个参数分别适应其学习率,对于出现频率较低的特征给予更大的学习率。
- 特点:非常适合处理稀疏数据。
- RMSprop:
- 基本思想:修改Adagrad以改善其在非凸设置下的性能,通过使用梯度的滑动平均的平方根来调整学习率。
- 特点:能够解决Adagrad学习率急剧下降问题。
- Adam:
- 基本思想:结合了Momentum和RMSprop的优点,对梯度的一阶矩估计(即均值)和二阶矩估计(即未中心化的方差)进行综合。
- 特点:
- 自动调整学习率。
- 通常被认为是对大多数问题都表现良好的优化器。
AdaDelta:
- 基本思想:改进Adagrad以减少其激进的、单调递减的学习率。
- 特点:不需要设置默认的学习率,使用参数的窗口变化率来调整学习率。
Adamax:
- 基本思想:是Adam的变种,使用无穷范数来替代二阶矩的估计。
- 特点:在某些情况下,比Adam表现更稳定。
Nadam:
- 基本思想:结合了Nesterov加速梯度(NAG)和Adam的优点。
- 特点:提供了一种更快的收敛方法,尤其在模型的早期阶段。
在选择优化器时,常常需要根据具体问题的性质和数据的特点来决定。例如,对于大多数常规问题,Adam是一个不错的起点,而在处理非常稀疏的数据时,Adagrad可能表现更好。实践中,通常建议尝试几种不同的优化器,以找到最适合问题的那一个。
2.5 评估指标(Metrics)
2.5.1 准确率、精确率、召回率
TP(True Positive)、TN(True Negative)、FP(False Positive)、FN(False Negative)。
准确率(Accuracy):模型预测正确的样本数量占总样本数量的比例。
精确率(Precision):模型预测为正类的样本中实际为正类的比例。
召回率(Recall):实际为正类的样本中被模型正确预测为正类的比例。
区别
- 准确率:衡量整体预测的正确性。
- 精确率:又叫“查准率”,关注正类预测的准确性,以预测结果为判断依据,此标准来评估预测正类的准确度,适用于减少误报的场景。
- 召回率:又叫“查全率”,关注正类样本的全面识别,以实际样本为判断依据,适用于减少漏报的场景。
2.5.2 F1 Score
F1-Score又称为平衡F分数(balanced F Score),他被定义为精准率和召回率的调和平均数。
2.5.3 IoU
在进行目标检测和分割任务时,IoU(Intersection over Union,交并比)是一个常用的性能评估指标。IoU用于衡量预测边界框与真实边界框之间的重叠程度。
这里的“Area of Overlap”是指预测边界框与真实边界框重叠的区域面积,而“Area of Union”是指预测边界框和真实边界框合并后的总面积。
IoU广泛应用于目标检测算法中,如R-CNN、SSD、YOLO等。在这些算法中,IoU常用来评估预测的准确性,以及在训练过程中用于非极大值抑制(Non-maximum Suppression, NMS)来选择最佳的边界框。
2.6 内存布局
在CNN(卷积神经网络)中,输入、中间结果(特征图)以及权重数据的存储方式在内存中主要依赖于使用的具体深度学习框架(如TensorFlow, PyTorch等)以及底层硬件(如CPU, GPU)。
这些数据都是以多维数组(张量)的形式存储的。
2.6.1 输入
输入图片通常以三维张量的形式存储,其维度通常是 (高度, 宽度, 通道数)。在某些框架中,尤其是在使用批处理时,可能会添加一个额外的维度,即成为四维张量 (批大小, 高度, 宽度, 通道数)。例如,一批数量为64的彩色图片(使用RGB三通道),每张图片分辨率为224x224,将会存储在一个 (64, 224, 224, 3) 形状的张量中。
2.6.2 中间结果
在 CNN 中,每一层卷积操作的输出被称为特征图。这些也是以多维数组的形式存储。对于每一层,特征图的维度可能不同,依赖于该层的过滤器大小、步长、填充策略等。例如,如果某层输出64个特征图,且每个特征图的大小为112x112,则其存储形式是 (批大小, 112, 112, 64)。
2.6.3权重
权重数据是 CNN 中学习得到的参数,通常是以四维张量的形式存储,其维度为 (卷积核高度, 卷积核宽度, 输入通道数, 输出通道数)。例如,一个3x3卷积核,输入通道数为3,输出通道数为64的卷积层,其权重张量的形状将是 (3, 3, 3, 64)。

2.7 CNN 参数量与层数
网络层数是指具有学习参数的层。
这通常包括:
- 卷积层(Convolutional layers)
- 全连接层(Fully connected layers,也称为密集层或dense layers)
- 某些情况下的递归层(Recurrent layers)
通常不将池化层(Pooling layers)、归一化层(Normalization layers)和激活层(Activation layers)计入网络的“层数”中,因为它们不含学习参数。
通过 kera 构建一个极简的 CNN 网络:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense
mini_model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
Flatten(),
Dense(10, activation='softmax')
])查看模型的详细参数和网络结构:
mini_model.summary()
---
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
flatten (Flatten) (None, 28800) 0
dense (Dense) (None, 10) 288010
=================================================================
Total params: 288,906
Trainable params: 288,906
Non-trainable params: 0
_________________________________________________________________各层参数量计算的详细解释:
1. 卷积层 (Conv2D)
参数数量=(卷积核宽度×卷积核高度×输入通道数+1)×卷积核数量
参数数量=(3×3×3+1)×32=896
2. Flatten层
Flatten层没有学习参数,它仅仅是改变数据的形状(从多维转换为一维),因此参数数量为0。
3. 全连接层 (Dense)
输入单元数:由前一层的输出决定。由于前一层是Flatten层,其输出是卷积层输出的展平形式。卷积层输出的尺寸为30x30(因为32x32的输入经过3x3的卷积核后尺寸减小),并且有32个过滤器,所以输出尺寸是30x30x32。
输出单元数:10(有10个分类标签)
参数数量=(输入单元数+1)×输出单元数
参数数量=(30×30×32+1)×10=288010
总参数数量为896 + 0 + 288010 = 288,906个参数。
3. Tiny-VGG
3.1 构建模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Activation
tiny_vgg = Sequential([
Conv2D(10, (3, 3), input_shape=(64, 64, 3), name='conv_1_1'),
Activation('relu', name='relu_1_1'),
Conv2D(10, (3, 3), name='conv_1_2'),
Activation('relu', name='relu_1_2'),
MaxPool2D((2, 2), name='max_pool_1'),
Conv2D(10, (3, 3), name='conv_2_1'),
Activation('relu', name='relu_2_1'),
Conv2D(10, (3, 3), name='conv_2_2'),
Activation('relu', name='relu_2_2'),
MaxPool2D((2, 2), name='max_pool_2'),
Flatten(name='flatten'),
Dense(10, activation='softmax', name='output')
])3.2 模型详细参数
tiny_vgg.summary()
---
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_1_1 (Conv2D) (None, 62, 62, 10) 280
relu_1_1 (Activation) (None, 62, 62, 10) 0
conv_1_2 (Conv2D) (None, 60, 60, 10) 910
relu_1_2 (Activation) (None, 60, 60, 10) 0
max_pool_1 (MaxPooling2D) (None, 30, 30, 10) 0
conv_2_1 (Conv2D) (None, 28, 28, 10) 910
relu_2_1 (Activation) (None, 28, 28, 10) 0
conv_2_2 (Conv2D) (None, 26, 26, 10) 910
relu_2_2 (Activation) (None, 26, 26, 10) 0
max_pool_2 (MaxPooling2D) (None, 13, 13, 10) 0
flatten (Flatten) (None, 1690) 0
output (Dense) (None, 10) 16910
=================================================================
Total params: 19,920
Trainable params: 19,920
Non-trainable params: 0
_________________________________________________________________3.3 可视化结构图

4. Resnet18
4.1 模型详细参数
summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------4.2 ResNet18的层数
1. 初始卷积层和池化层:
- 1个卷积层
- 1个池化层(不计入权重层)
2. 残差块(Residual Blocks):
- 每个残差块包含2个卷积层
- ResNet18有4个阶段,每个阶段包含2个残差块
- 总共:4个阶段 × 2个残差块/阶段 × 2个卷积层/残差块 = 16个卷积层
3. 最终全连接层:
- 1个全连接层
总计:1(初始卷积层) + 16(残差块中的卷积层) + 1(全连接层) = 18个权重层
4.3 极简残差网络
导入必要的包:
from tensorflow.keras.layers import Input, GlobalAveragePooling2D, Dense, Conv2D, BatchNormalization, Activation, add
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
import tensorflow.keras as keras定义残差块:
# 定义残差块基本结构
def res_block_v1(x, input_filter, output_filter, block_id):
res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same', name=f"conv_{block_id}_1")(x)
res_x = BatchNormalization(name=f"bn_{block_id}_1")(res_x)
res_x = Activation('relu', name=f"act_{block_id}_1")(res_x)
res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same', name=f"conv_{block_id}_2")(res_x)
res_x = BatchNormalization(name=f"bn_{block_id}_2")(res_x)
if input_filter == output_filter:
identity = x
else:
identity = Conv2D(kernel_size=(1,1), filters=output_filter, strides=1, padding='same', name=f"conv_id_{block_id}")(x)
x = add([identity, res_x], name=f"add_{block_id}")
output = Activation('relu', name=f"out_act_{block_id}")(x)
return output
定义极简残差网络:
# 定义输入层
input_shape = (64, 64, 3) # 64x64的RGB图像
inputs = Input(shape=input_shape, name='input_layer')
# 创建两个残差块堆叠
x = res_block_v1(inputs, input_filter=3, output_filter=64, block_id=1)
x = res_block_v1(x, input_filter=64, output_filter=64, block_id=2)
# 使用全局平均池化
x = GlobalAveragePooling2D(name='global_avg_pool')(x)
# 添加输出层
outputs = Dense(10, activation='softmax', name='output_layer')(x)
# 创建模型
model = Model(inputs=inputs, outputs=outputs)
# 模型总结
model.summary()模型总结:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_layer (InputLayer) [(None, 64, 64, 3)] 0 []
conv_1_1 (Conv2D) (None, 64, 64, 64) 1792 ['input_layer[0][0]']
bn_1_1 (BatchNormalization) (None, 64, 64, 64) 256 ['conv_1_1[0][0]']
act_1_1 (Activation) (None, 64, 64, 64) 0 ['bn_1_1[0][0]']
conv_1_2 (Conv2D) (None, 64, 64, 64) 36928 ['act_1_1[0][0]']
conv_id_1 (Conv2D) (None, 64, 64, 64) 256 ['input_layer[0][0]']
bn_1_2 (BatchNormalization) (None, 64, 64, 64) 256 ['conv_1_2[0][0]']
add_1 (Add) (None, 64, 64, 64) 0 ['conv_id_1[0][0]',
'bn_1_2[0][0]']
out_act_1 (Activation) (None, 64, 64, 64) 0 ['add_1[0][0]']
conv_2_1 (Conv2D) (None, 64, 64, 64) 36928 ['out_act_1[0][0]']
bn_2_1 (BatchNormalization) (None, 64, 64, 64) 256 ['conv_2_1[0][0]']
act_2_1 (Activation) (None, 64, 64, 64) 0 ['bn_2_1[0][0]']
conv_2_2 (Conv2D) (None, 64, 64, 64) 36928 ['act_2_1[0][0]']
bn_2_2 (BatchNormalization) (None, 64, 64, 64) 256 ['conv_2_2[0][0]']
add_2 (Add) (None, 64, 64, 64) 0 ['out_act_1[0][0]',
'bn_2_2[0][0]']
out_act_2 (Activation) (None, 64, 64, 64) 0 ['add_2[0][0]']
global_avg_pool (GlobalAverage (None, 64) 0 ['out_act_2[0][0]']
Pooling2D)
output_layer (Dense) (None, 10) 650 ['global_avg_pool[0][0]']
==================================================================================================
Total params: 114,506
Trainable params: 113,994
Non-trainable params: 512
__________________________________________________________________________________________________可视化网络:
plot_model(model, to_file='model_structure.png', show_shapes=True, show_layer_names=True)
5. 总结
这篇文档介绍了一个名为CNN Explainer的交互式可视化系统,旨在帮助非专业人士学习卷积神经网络(CNN)。该系统通过直观的方式展示了CNN的工作原理,使用户能够更好地理解复杂的神经网络结构和运算过程。
文档首先解释了并行度的概念,包括像素并行(PP)、输入通道并行(ICP)和输出通道并行(OCP)。这些并行度参数决定了在每个周期内同时执行的操作数量。例如,ICP表示输入通道的并行度,如果DPU的ICP=3,意味着单周期内可以同时处理三个输入通道的运算。
接下来,文档详细分析了一个名为 Tiny-VGG 的 CNN 模型。该模型由多个卷积层、激活层、池化层和全连接层组成。每个卷积层使用3x3的过滤器,通过ReLU激活函数进行非线性变换。最大池化层用于降低特征图的空间维度,从而减少计算量并提取重要特征。最后,全连接层使用 softmax激活函数输出每个类别的预测概率。
进一步,我们探讨了 ResNet18 架构的层数和参数量,并通过定义残差块展示了极简残差网络的构建过程。这些内容不仅帮助我们理解了 CNN 的工作原理,还展示了如何通过具体的代码实现和可视化工具来构建和分析深度学习模型。
通过这种逐层分析,读者可以清晰地了解每一层的功能和作用,以及它们如何协同工作来完成图像分类任务。










![[CSS3]2D与3D变换技术详解](https://img-blog.csdnimg.cn/img_convert/e337d2c193be28382334d0789e7b8663.png)


![【BUU】[Dest0g3 520迎新赛]Really Easy SQL](https://img-blog.csdnimg.cn/img_convert/7a4df6d2916cfcceb82f92b58b4f577c.png)