我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
第二课: PMPP 书的第1-3章
这节课非常基础,讲的都是基本概念和初级的注意事项,有CUDA基础的朋友可以不用花时间看。
PMPP 第一章

这一页没什么好说的,就是介绍一些大模型和AI的背景,CPU和GPU的架构区别,以及GPU的出现是为了解决CPU无法通过硬件技术解决的大规模计算性能问题。
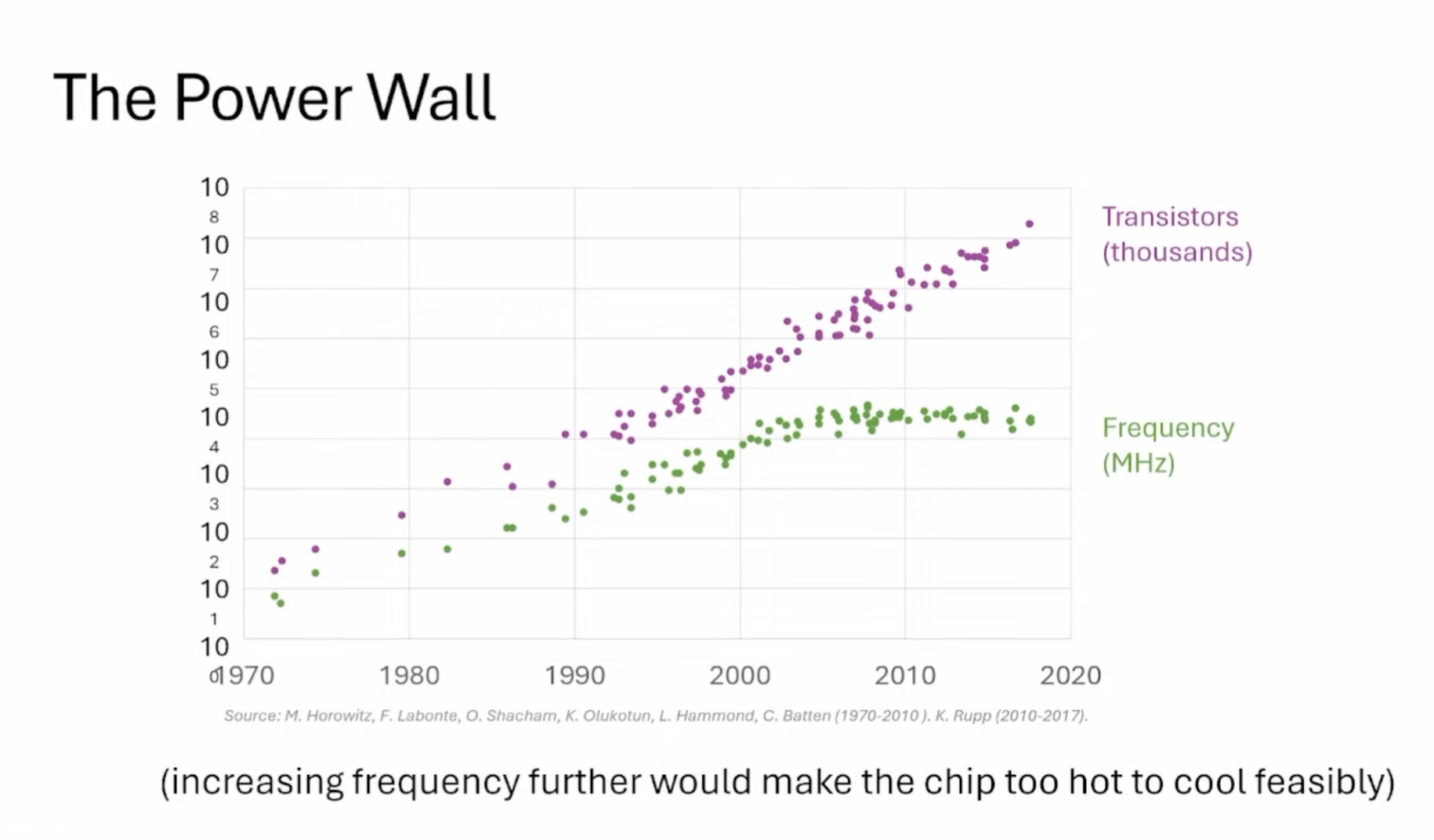
这张图名为"The Power Wall"(功耗墙),展示了从1970年到2020年间计算机芯片技术的两个关键参数的发展趋势:
晶体管数量(紫色线):以千为单位,呈指数增长趋势。
频率(绿色线):以MHz为单位,显示了处理器时钟速度的变化。
"功耗墙"现象:图表底部的注释解释了为什么频率不再持续增长 —— “进一步提高频率会使芯片变得太热而无法有效散热”。

这张slides介绍了CUDA的兴起及其关键特性:
- CUDA 专注于并行程序,适用于现代软件。
- GPU 的峰值 FLOPS 远高于多核 CPU。
- 主要原则是将工作分配给多个线程。
- GPU 注重大规模线程的执行吞吐量。
- 线程较少的程序在 GPU 上表现不佳。
- 将顺序部分放在 CPU 上,数值密集部分放在 GPU 上。
- CUDA 是 Compute Unified Device Architect(统一计算设备架构)。
- 在 CUDA 出现前,使用图形 API(如 OpenGL 或 Direct3D)进行计算。
- 由于 GPU 的广泛可用性,GPU 编程对开发者变得更具吸引力。

这张slides介绍了CUDA编程中的一些挑战:
- 如果不关注性能,并行编程很容易,但优化性能很难。
- 设计并行算法比设计顺序算法更困难,例如并行化递归计算需要非直观的思维方式(如前缀和)。
- 并行程序的速度通常受到内存延迟和吞吐量的限制(内存瓶颈,比如LLM推理的decode)。
- 并行程序的性能可能因输入数据的特性而显著变化。(比如LLM推理有不同长度的序列)。
- 并非所有应用都能轻松并行化,很多需要同步的地方会带来额外的开销(等待时间)。例如有数据依赖的情况。

《Programming Massively Parallel Processors》这本书的三个主要目标是:
- 教大家并行编程和计算思维
- 并且以正确可靠的形式做到这一点,这包括debug和性能两方面
- 第三点指的应该是如何更好的组织书籍,让读者加深记忆之类的。
虽然这里以GPU作为例子,但这里介绍到的技术也适用于其它加速器。书中使用CUDA例子来介绍和事件相应的技术。
PMPP 第二章

题目是 CH2: 异构数据并行编程
- 异构(Heterogeneous):结合使用CPU和GPU来进行计算,利用各自的优势来提高处理速度和效率。
- 数据并行性(Data parallelism):通过将大任务分解为可以并行处理的小任务,实现数据的并行处理。这种方式可以显著提高处理大量数据时的效率。
- 应用示例:
- 向量加法:这是并行计算中常见的例子,通过将向量的每个元素分别相加,可以并行处理,提高计算速度。
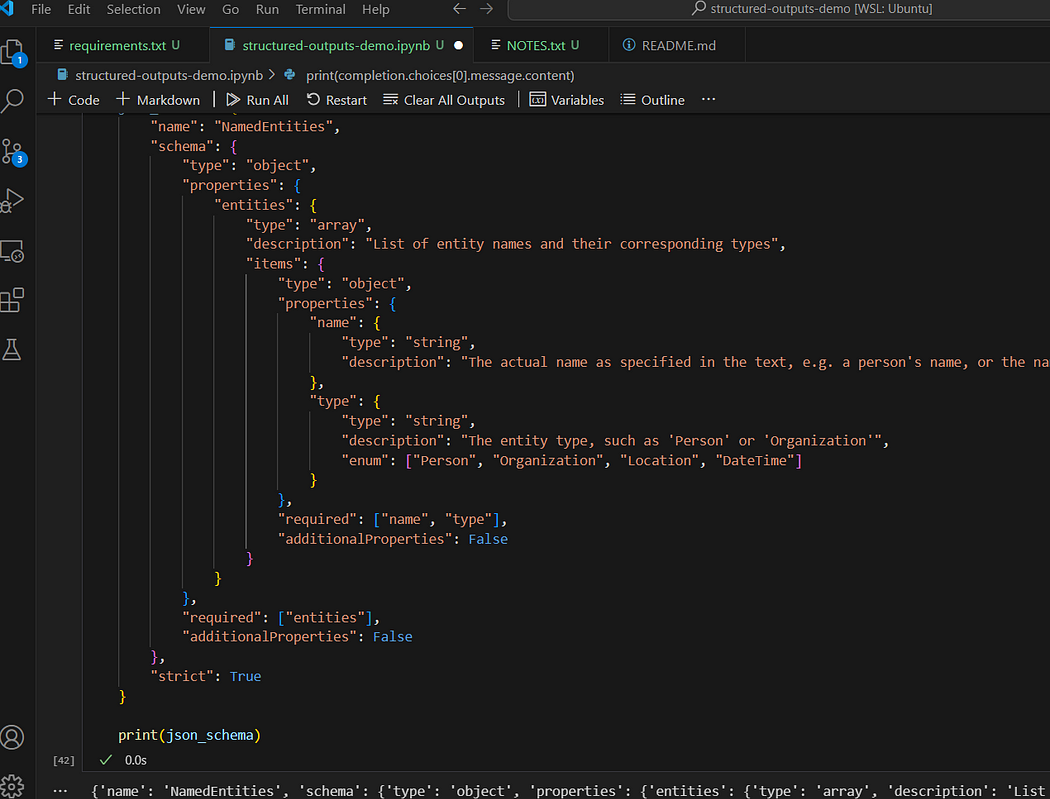
- 将RGB图像转换为灰度图:这个过程通过应用一个核函数,根据每个像素的RGB值计算其灰度值。公式为
L = r*0.21 + g*0.72 + b*0.07,其中L代表亮度(Luminance)。这个转换是基于人眼对不同颜色的感光敏感度不同,其中绿色部分权重最高。
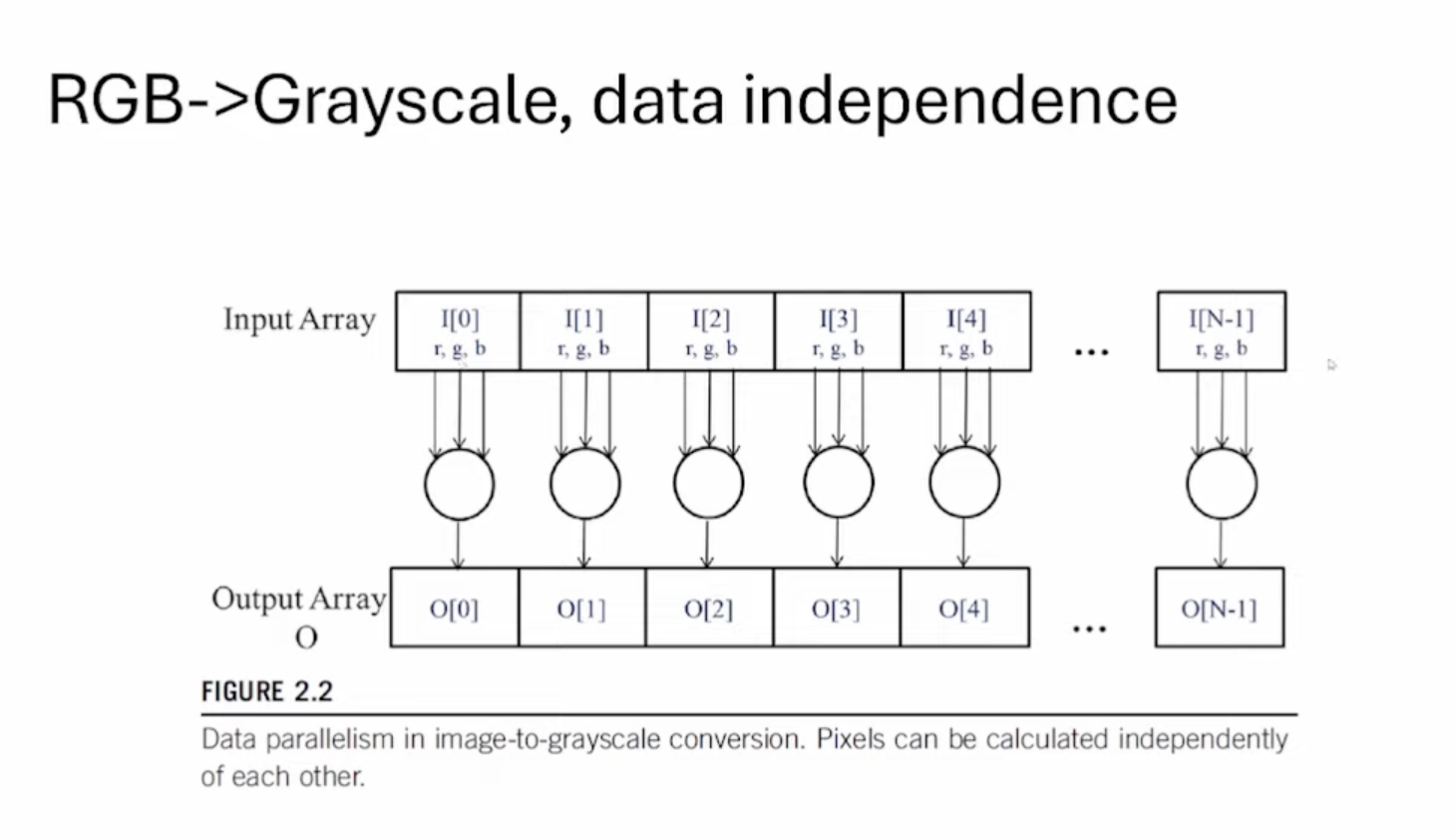
这张Slides可以看到所有像素点的计算都是独立的。

这张Slides介绍了CUDA C的一些特点:
- 扩展了ANSI C的语法,增加了少量的新的语法元素。
- 术语中,CPU表示主机,GPU表示设备。
- CUDA C源代码可以是主机代码和设备代码的混合。
- 设备代码函数称为内核(kernels)。
- 使用线程网格(grid of threads)来执行内核,多个线程并行运行。
- CPU和GPU代码可以并发执行(重叠)。
- 在GPU上可以大量启动多个线程,不需要担心。
- 对于输出张量的每一个元素启动一个线程是很正常的。

这张Slides给出了一个向量加法的CUDA C编程示例:
- 向量加法的并行化: 主要概念循环会被映射到多个线程进行独立计算,从而实现易于并行化。
- Naive 的GPU 向量加法步骤:
- 为向量分配设备内存
- 将输入从主机传输到设备
- 启动内核(kernel)进行向量加法运算
- 将计算结果从设备拷贝回主机
- 释放设备内存
- 保持数据在GPU上尽可能长的时间,以支持并发的内核启动。这可以最大限度地提高性能。
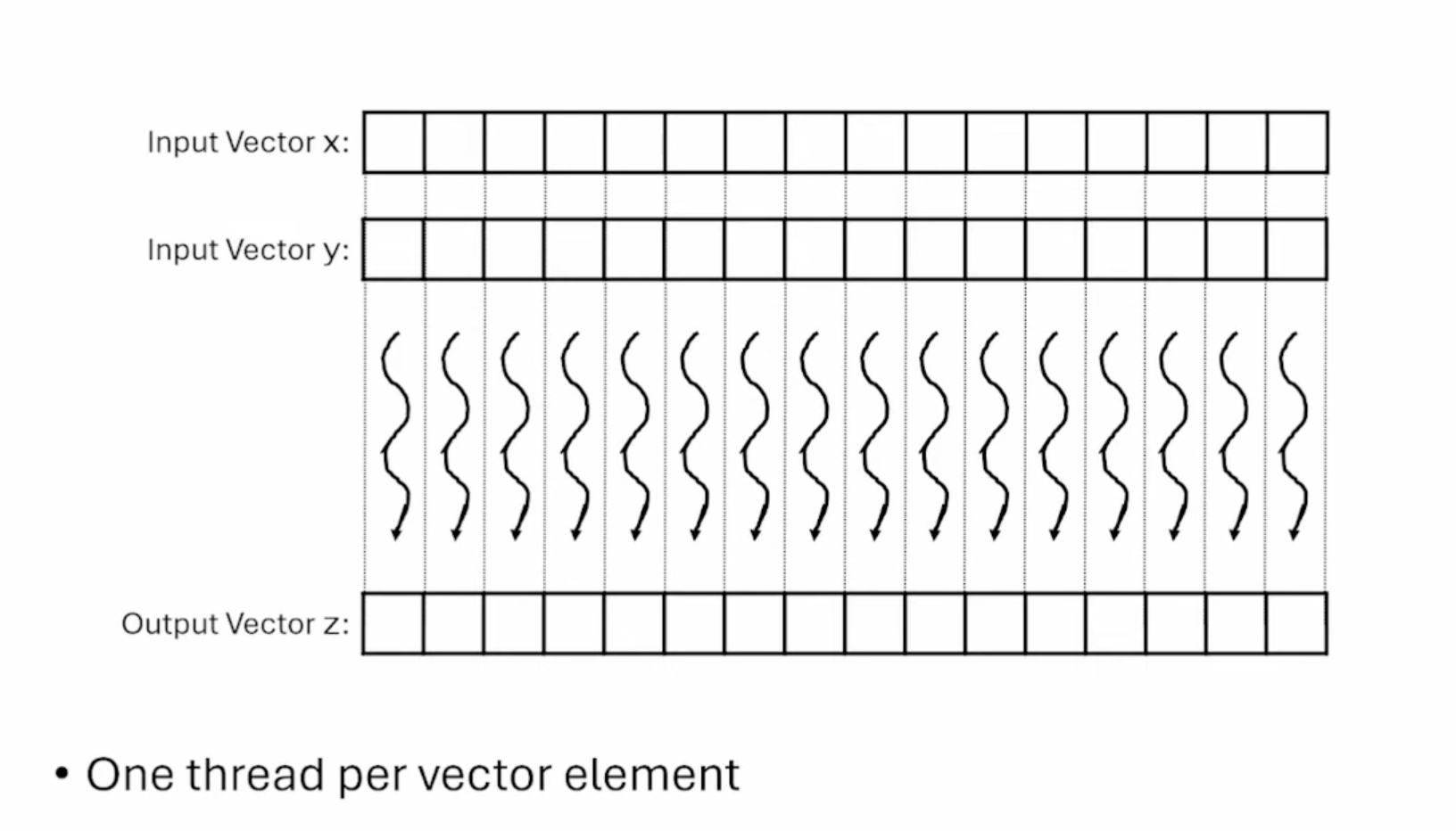
这张Slides展示了每个线程处理一个输出元素的计算,并且是相互独立的。

这张Slides介绍了CUDA编程中内存分配的重要概念:
- NVIDIA设备拥有自己的DRAM(设备全局内存)。
- CUDA提供了两个重要的内存分配函数
- cudaMalloc(): 在设备全局内存上分配内存空间。
- cudaFree(): 释放设备全局内存上的内存空间。
- 代码示例中展示了如何使用这两个函数来动态分配和释放浮点型数组的内存空间。
- size_t size = n * sizeof(float);//计算数组所需的字节数
- cudaMalloc((void**)&A_d, size);//在设备上分配内存
- cudaFree(A_d);//释放设备内存

这张Slides介绍了CUDA中内存搬运的API,包括D2H和H2D。一般来说,CUDA程序会先执行H2D的Memcpy把数据搬运到GPU上,然后kernel执行完之后再把结果通过D2H的Memcpy搬运回主机端。

这张Slides介绍了CUDA编程中的错误处理机制:
- CUDA函数如果出现错误,会返回一个特殊的错误代码 cudaError_t。如果不是 cudaSuccess,则表示发生了问题。也可以通过这个错误代码获得它的字符串表示形式。
- 编程时,我们需要始终检查 CUDA 函数的返回值,并处理可能出现的错误。
我们在 https://github.com/cuda-mode/lectures/blob/main/lecture_002/vector_addition/vector_addition.cu 这里可以到如何处理错误码:
// https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char *file, int line, bool abort = true) {
if (code != cudaSuccess) {
fprintf(stderr, "GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) {
exit(code);
}
}
}
inline unsigned int cdiv(unsigned int a, unsigned int b) {
return (a + b - 1) / b;
}
void vecAdd(float *A, float *B, float *C, int n) {
float *A_d, *B_d, *C_d;
size_t size = n * sizeof(float);
cudaMalloc((void **)&A_d, size);
cudaMalloc((void **)&B_d, size);
cudaMalloc((void **)&C_d, size);
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);
const unsigned int numThreads = 256;
unsigned int numBlocks = cdiv(n, numThreads);
vecAddKernel<<<numBlocks, numThreads>>>(A_d, B_d, C_d, n);
gpuErrchk(cudaPeekAtLastError());
gpuErrchk(cudaDeviceSynchronize());
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}

这张Slides介绍了CUDA编程中内核函数(kernel)的基本特点:
- 启动内核函数相当于启动一个由多个线程组成的网格(grid of threads)。
- 所有的线程执行同样的代码,实现了单程序多数据(SPMD)的并行模式。
- 线程以分层的方式组织,分为网格块(grid blocks)和线程块(thread blocks)。
- 每个线程块最多可以包含1024个线程。

这张Slides讲解了Kernel坐标的几个点:
- 内核中可用的内置变量:blockIdx, threadIdx:这些是CUDA编程中用来标识线程位置的内置变量。blockIdx表示当前线程块的索引,而threadIdx表示当前线程在其所在块中的索引。
- 这些“坐标”允许所有执行相同代码的线程识别要处理的数据部分:通过使用blockIdx和threadIdx,每个线程可以确定它应该处理数据的哪一部分。这对于并行处理非常重要,因为不同的线程可以同时处理不同的数据片段。
- 每个线程可以通过threadIdx和blockIdx唯一标识:threadIdx和blockIdx的组合可以唯一确定一个线程的位置,从而避免不同线程处理相同的数据片段。
- 电话系统类比:将blockIdx视为区号,将threadIdx视为本地电话号码:这种类比帮助理解:blockIdx相当于更大的区域(类似于区号),而threadIdx是在这个区域内的具体线程(类似于本地电话号码)。
- 内置的blockDim告诉我们块中的线程数:blockDim表示每个线程块中包含的线程数。这个变量对于计算每个线程的全局索引是必要的。
- 对于向量加法,我们可以计算线程的数组索引:示例代码:int i = blockIdx.x * blockDim.x + threadIdx.x; 这行代码展示了如何计算每个线程在整个数据数组中的位置。blockIdx.x * blockDim.x计算的是当前块之前所有线程的总数,加上threadIdx.x得到当前线程的全局索引。
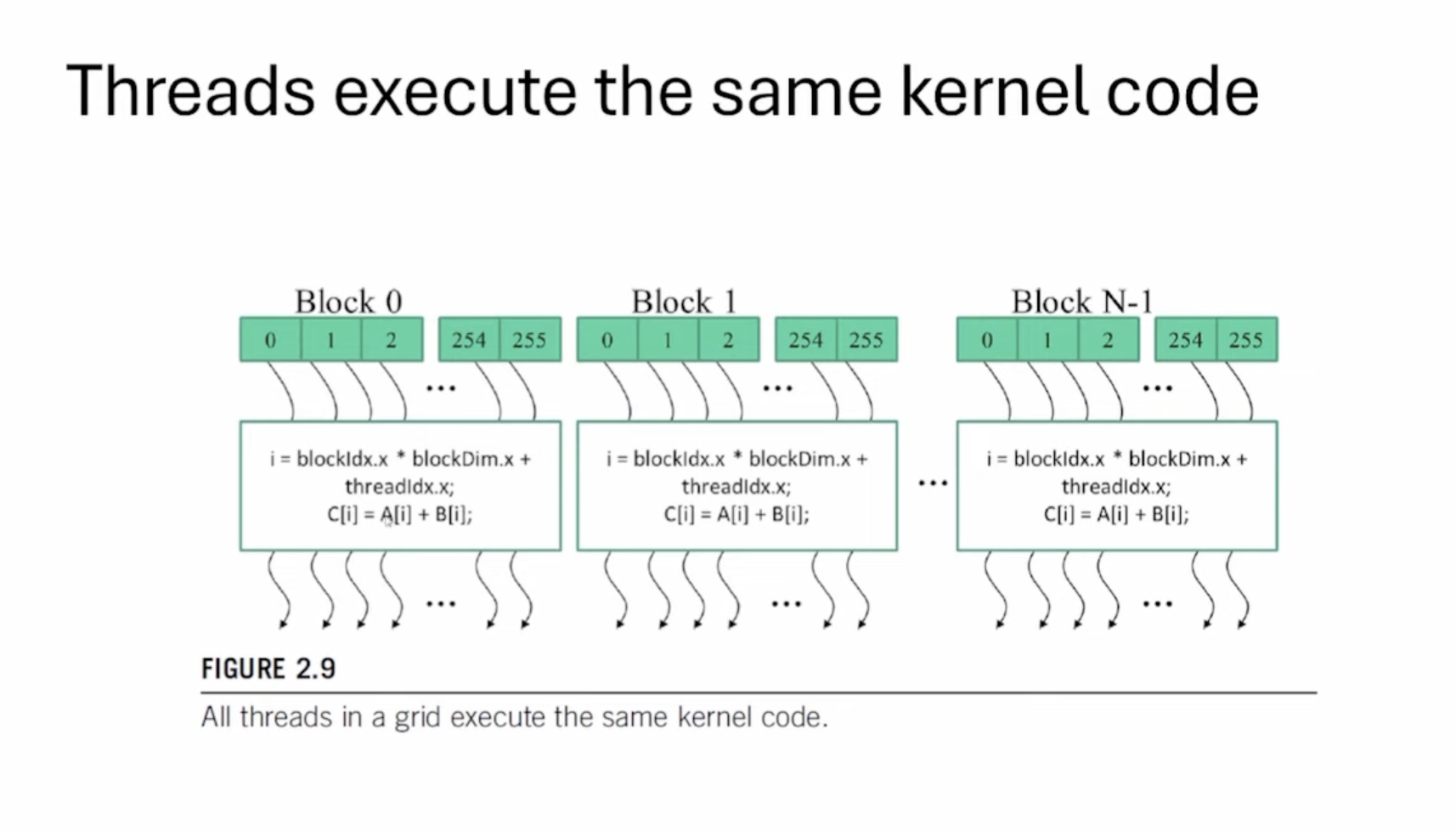
这张Slides是对Kernel坐标定位的可视化。我们可以看到每个线程执行相同的代码,仅仅是数据的位置不同。

这张Slides解释了CUDA C中的几个关键函数声明修饰符:__global__,__device__和__host__,以及它们的用法和特性。
-
__global__修饰符:- 用
__global__声明的函数是一个kernel函数。 - 调用
__global__函数会启动一个新的CUDA线程网格(grid of cuda threads)。 - 从Host(CPU)端调用,在Device(GPU)上执行。
- 用
-
__host__修饰符:- 用
__host__声明的函数在CPU上执行。 - 从Host(CPU)端调用。
- 用
-
__device__修饰符:- 用
__device__声明的函数可以在CUDA线程内部被调用。 - 在Device(GPU)上执行。
- 用
-
组合使用:
- 如果在函数声明中同时使用
__host__和__device__修饰符,编译器会为该函数生成CPU和GPU两个版本。
- 如果在函数声明中同时使用

这张Slides讲解了在CUDA编程中进行向量加法的一个示例,并提供了一些重要的策略和注意事项:
- 总体策略:用线程网格(grid of threads)替代循环。这是CUDA并行编程的核心思想。
- 数据大小考虑:数据大小可能不能被块大小完美整除,因此总是需要检查边界条件。
- 内存访问安全:防止边界块的线程读写分配内存之外的区域,这是为了避免内存访问错误。
- 代码示例:展示了一个向量加法的CUDA kernel函数:
- 函数计算向量和:C = A + B
- 每个线程执行一次对应元素的加法操作
- 使用
__global__修饰符声明kernel函数 - 函数参数包括输入向量A和B,输出向量C,以及向量长度n
- 使用线程和块的索引计算每个线程负责的元素位置
- 进行边界检查,确保不会访问超出向量范围的元素
- 执行实际的加法操作

这张Slides讲解了CUDA调用kernel的一些注意的点。
- kernel配置是在
<<<和>>>之间指定的。这个配置主要包括两个参数:块的数量和每个块中的线程数量。 - 代码块中,设置每个块的线程数为256:dim3 numThreads(256); 计算所需的块数:dim3 numBlocks((n + numThreads - 1) / numThreads); 这个计算方式确保了即使n不能被numThreads整除,也能覆盖所有的数据。
- 后续将会学习其他启动参数,如共享内存大小(shared-mem size)和CUDA流(cudaStream)。

这张Slides介绍了CUDA编程中的编译器和相关概念:
- NVCC是NVIDIA的C编译器,它用于将CUDA内核代码编译成PTX (Parallel Thread Execution)
- PTX是一种低级虚拟机(VM)和指令集,它是CUDA代码编译过程中的一个中间表示
- 图形驱动程序负责将PTX转译成可执行的二进制代码(SASS),SASS (Streaming Assembly) 是GPU上实际执行的机器代码
PMPP 第三章

这张Slides和Lecture 2是几乎重复的。

这张Slides为我们展示了启动kernel的2D线程网格(Grid)和3D线程块(Block)的结构,我们可以在同一个设备上启动多个kernel。

这张Slides继续讨论了CUDA中的网格(Grid)概念:
- 每次内核启动可以使用不同的网格配置,例如根据数据形状来决定。
- 典型的网格包含数千到数百万个线程。
- 常用的策略是每个输出元素对应一个线程(如每个像素一个线程,每个张量元素一个线程)。
- 线程可以以任意顺序被调度执行。
- 可以使用少于3维的网格配置(未使用的维度设为1)。
- 例如:1D用于序列处理,2D用于图像处理等。
- 代码例子展示了如何定义一个1D的网格和块配置,总共启动4096个线程。

CUDA已经有了这些内置变量在里面了,第二章反复提到过。
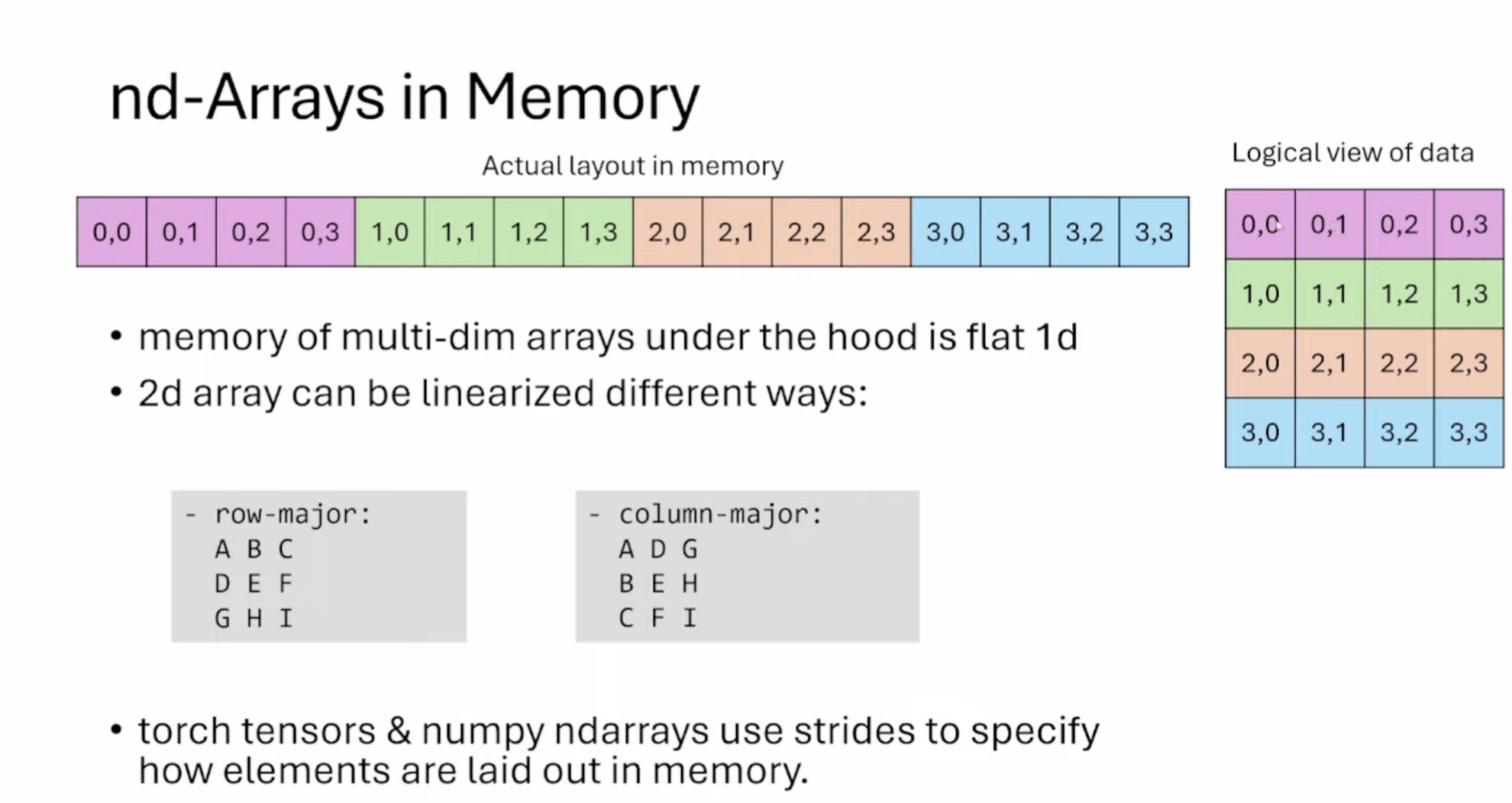
这张Slides讲解了多维数组在内存中的存储方式,主要内容如下:
- 多维数组在内存中实际上是以扁平的一维方式存储的。图中展示了一个4x4的二维数组如何在内存中线性存储。
- 左侧显示了实际的内存布局(一维);右侧显示了数据的逻辑视图(二维)
- 二维数组可以通过不同方式线性化:
- a) 行主序(Row-major):按行存储,如 ABC DEF GHI
- b) 列主序(Column-major):按列存储,如 ADG BEH CFI
- Torch tensors 和 NumPy ndarrays 这些库使用步长(strides)来指定元素在内存中的布局方式。
- 理解内存布局对于优化数据访问和提高计算效率非常重要,特别是在并行计算和GPU编程中。

这张Slides讲解了一个图像模糊(Image blur)的例子,主要内容如下:
- 实现了名为blurKernel的均值滤波器。
- 每个线程负责写入一个输出元素,但需要读取多个输入值。
- 示例中处理的是单个平面(指灰度图像),但可以轻松扩展到多通道(如RGB图像)。
- 展示了行主序(row-major)的像素内存访问方式(输入和输出指针)。
- 跟踪了多少个像素值被累加。
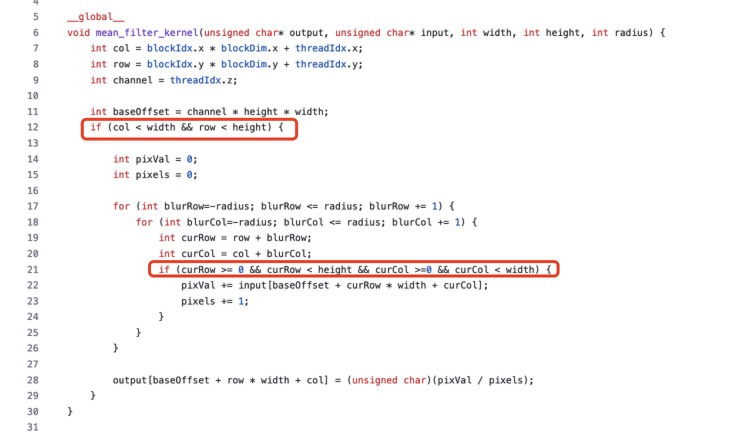
- 在kernel的第5行和第25行处理了边界条件。具体看下面截图里面的两个红色框部分,代码在 https://github.com/cuda-mode/lectures/blob/main/lecture_002/mean_filter/mean_filter_kernel.cu 。
- 实际效果:Slides展示了原始图像(左)和模糊处理后的图像(右)。原图是一束秋季花卉,模糊后的图像显示了典型的模糊效果。
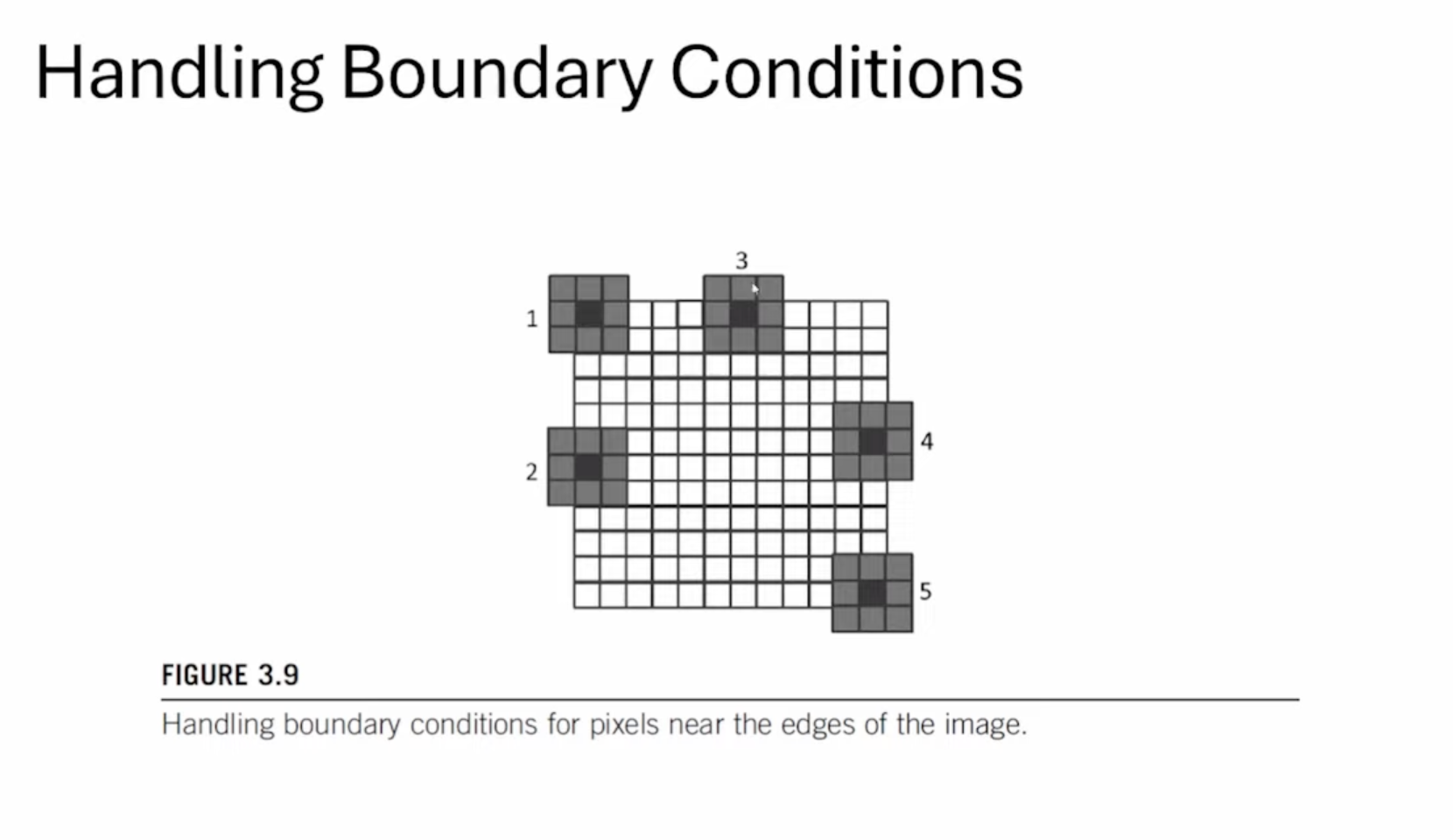
这张Slides展示了边界处理的示意图,对于图中不同位置的像素,实际有效的需要平滑的像素点数也有可能不一样。

这里展示了一个仍然一个线程计算一个输出元素的矩阵乘cuda kernel实现例子。
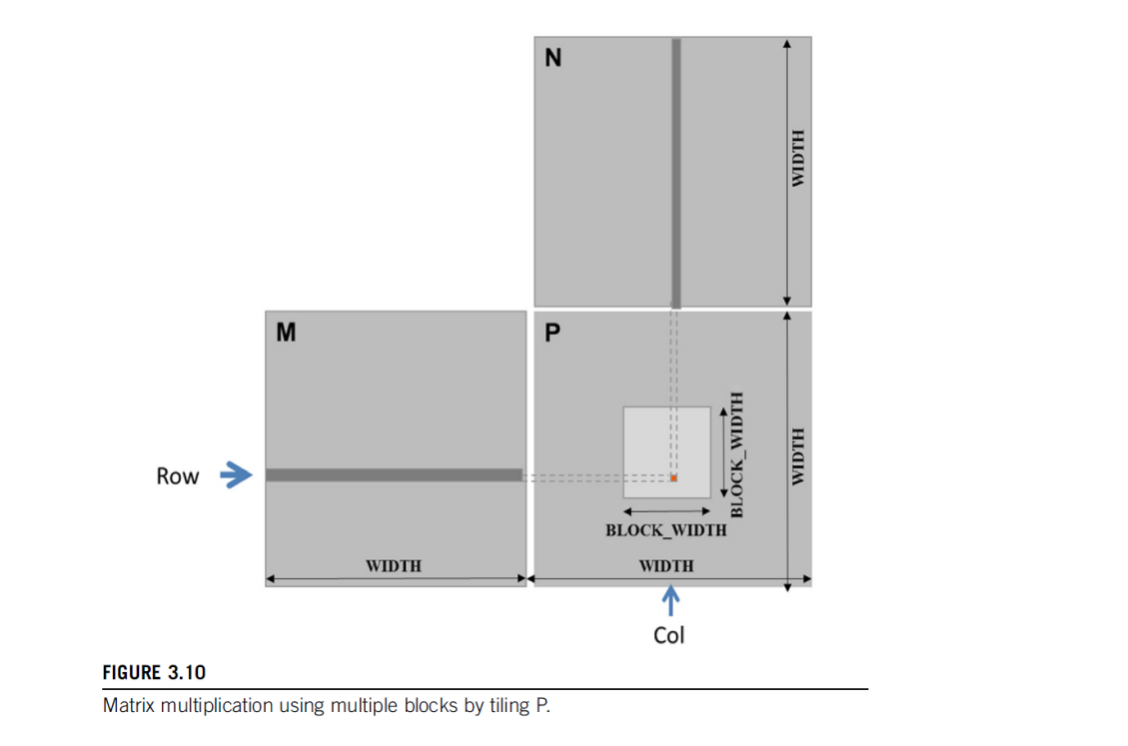
这张图展示了启动kernel的Tiling策略,相比于naive的启动方式可以有更好的数据cache。关于矩阵乘法,这节课就不再深入了。
关于矩阵乘法有很多非常猛的优化,大家可以参考 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/README.md 学习资料收集一节关于矩阵乘法的博客或者参考Triton的矩阵乘法优化教程,我之前也解读过一篇:【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一。靠自学了。
总结就是,这节课非常基础,讲的都是基本概念和初级的注意事项,有CUDA基础的朋友可以不用看。