进来在一个RTOS上移植开发网卡驱动,最终DMA收发包流程打通之后,在使用过程中觉得RTOS的处理逻辑太差了,因此有想法来梳理下Linux中对收发包流程处理,来给一些参考。
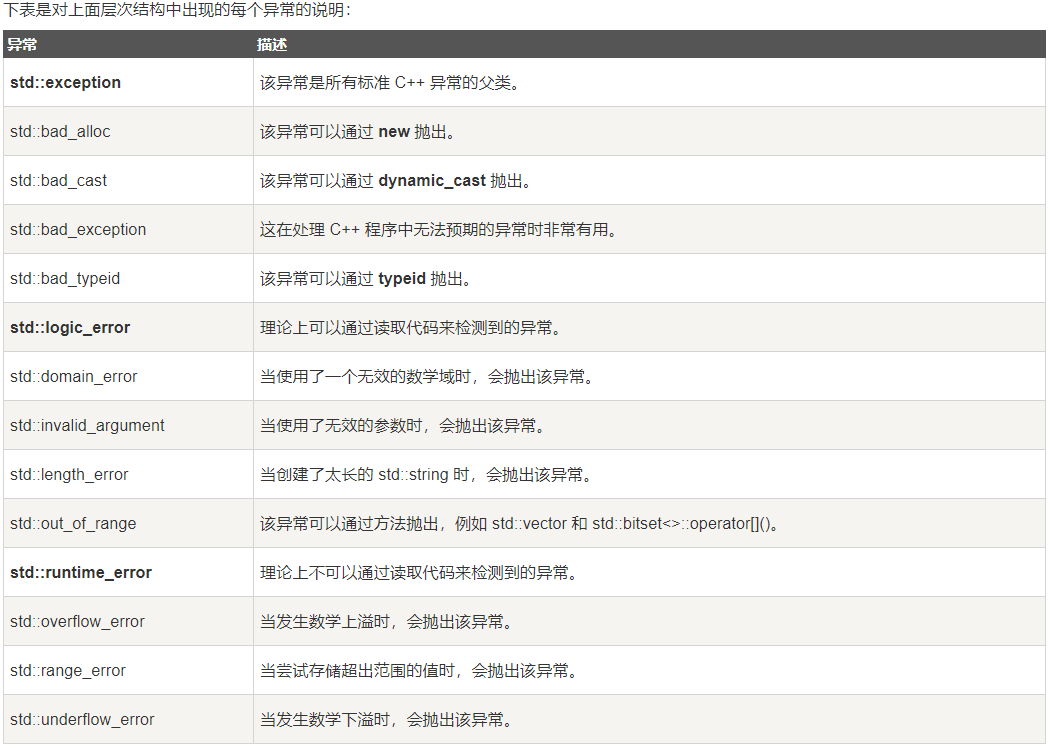
一、Linux接收网络包的流程
网卡是一个计算机的硬件,对应的驱动专门负责接收和发送网络包,当网卡接收到一个网络包后,会通过DMA技术将网络包写入到指定的DMA内存中,也就是Ring Buffer,这是一个环形缓存区。接着会告诉操作系统这个网络包已经到达,但怎么告诉,可以是中断。但在高性能模式下,频繁的触发中断,导致其他任务无法继续进行,从而影响系统的整体效率,为了解决性能开销,在2.6中引入了NAPI机制,核心概念是:中断+轮询,中断唤醒数据接收服务,然后poll轮询数据。
具体可以参考下面:

上图中虚线步骤的解释:
- DMA 将 NIC 接收的数据包逐个写入 sk_buff ,一个数据包可能占用多个 sk_buff , sk_buff 读写顺序遵循FIFO(先入先出)原则。
- DMA 读完数据之后,NIC 会通过 NIC Interrupt Handler 触发 IRQ (中断请求)。
- 首先需要关中断,表示已经知道内存中有数据,避免CPU不停的中断;接着发起软中断,然后恢复刚才屏蔽的中断,实际可以看到硬件中断处理函数做的事情很少,主要在软中断中处理;软中断处理函数:根据三个条件唤起ksoftirqd内核线程,ksoftirqd会轮询的处理数据,从Ring Buffer中获取一个数据帧,用sk_buffer表示,从而可以作为一个网络包交给网络协议栈逐层处理。
- NIC driver 注册 poll 函数。
- poll 函数对数据进行检查,例如将几个 sk_buff 合并,因为可能同一个数据可能被分散放在多个 sk_buff 中。
- poll 函数将 sk_buff 交付上层网络栈处理。
二 、Linux发送网络包的流程
1、调用socket发送数据包时,由于系统调用,陷入到内核态,内核态中的socket层会申请一个sk_buff内存,将用户的数据从用户态拷贝到sk_buff,并加入到发送队列。
2、网络协议栈基于sk_buff从上到下逐层封装,如果使用TCP传输协议发送数据,先要拷贝一个副本,副本发送完会删除,等到收到ACk后,sk_buff才会真正删除。
3、触发软中断告诉网卡驱动程序,有新的网络包需要发送,驱动程序会从发送队列中读取sk_buff,将sk_buff挂到RingBuffer中,接着将sk_buff的数据映射到网卡可以访问的内存DMA区域后,然后触发真实的发送。
4、当数据发送完毕后会触发一个【硬中断】,CPU响应该硬中断,吊起网卡驱动启动时向内核注册的该硬中断对应的处理函数,执行处理函数,在处理函数中最终会发起一个【软中断】。
5、【内核线程ksoftirqd】响应并处理该软中断,该线程会吊起网卡启动时注册的【该类型的软中断】(有很多类型的软中断,他们都对应不同的处理函数)的处理函数,执行处理函数,在处理函数中会执行如下操作:
①、 释放掉RingBuffer中的数组对skb的引用(注意:此时RingBuffer里的数组虽然放弃了对skb的引用,但是该skb并不会被立即清除,因为TCP有重传机制,必须要保证收到了对方的ack应答后再彻底删除该skb,如果没有收到对方的ack,那么传输层还可以重传该skb)
②、清理RingBuffer(以便于下次使用)
三、RTOS收包流程
四、RTOS发包流程
Linux收包参考链接:https://www.cnblogs.com/mauricewei/p/10502300.html
Linux发包参考链接:从内核角度看网络包发送流程_网卡 ringbuffer skb-CSDN博客