前言
ALB(Another Load Balancer)是一款由灵雀云基于 OpenResty 开发的开源Kubernetes(K8s) 网关,拥有多年的生产环境使用经验。Openresty框架高性能的基础上,提供了一系列高级特性,包括多租户支持、Ingress 和 Gateway API 支持、灵活的用户自定义路由规则以及对多种协议(HTTP, HTTPS, TCP 和 UDP,GRPC,Websocket)的管理能力。ALB 已经开源,未来将分享更多使用指南,期待你的持续关注。
今天我们将带来深入探究 lj-lua-stacks:如何生成 Lua 代码级别的火焰图?
什么是Lua级别的火焰图,我们为什么要关心它?
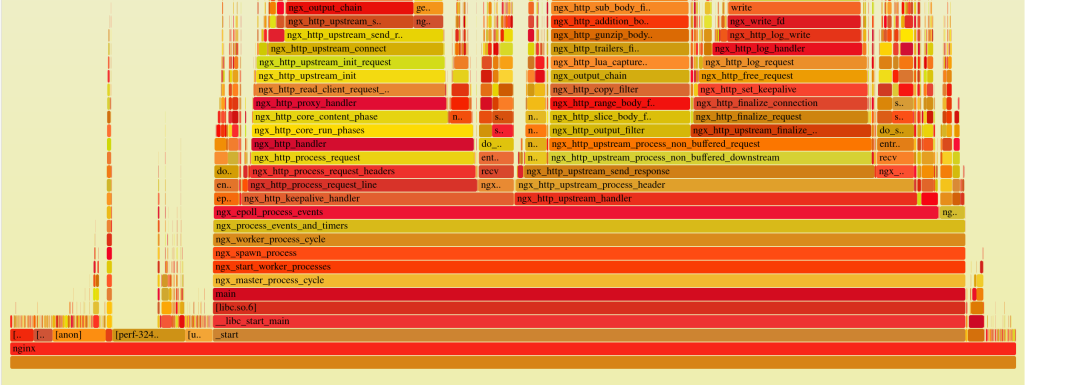
Nginx火焰图

Openresty lua 火焰图
作为一个在K8s上运行的网关,ALB[1]非常关注性能,我们希望了解,由于我们的 Lua 代码所引起的性能损耗究竟有多大,以及这些损耗主要出现在哪些部分?这些问题对我们来说至关重要。
如果直接从Nginx火焰图来分析,很难找到重点。使用perf工具,我们则可以轻松生成任意进程的火焰图,但是我们的lua代码在哪里?perf会解析调用栈的符号,对C函数很有用,但是对Lua函数则不那么直观。
我们需要的是OpenResty的Lua代码火焰图,通过它我们可以轻松地发现一些异常之处。例如,为什么在记录日志时,处理Prometheus指标的部分耗时如此之长?
原理及工具
Openresty社区中用于绘制火焰图的工具是stapxx[2]中的lj-lua-stacks。
其工作原理可以概括为:借助SystemTap在perf时注入代码Nginx进程上,遍历LuaJIT中的Lua函数调用堆栈,解析Lua函数名称,从而生成Lua代码级别的火焰图。
接下来,我将介绍一些具体的技术细节。
SystemTap
首先介绍的是SystemTap,它是2009年推出的动态追踪工具,它允许我们在用户函数和内核函数上执行自定义代码。
从当前的角度来看,SystemTap与bpftrace的功能定位有些相似,但与在内核中运行以确保安全的eBPF虚拟机不同。
SystemTap实际上是一种多阶段编译器,它将STAP脚本语言编译成C语言,再编译成内核模块,并最终在内核中执行。
# the stap script lang.
index = @var("ngx_http_module", "/xxx/nginx")->index
# struct of ngx_http_module
struct ngx_module_s {
ngx_uint_t ctx_index;
ngx_uint_t index;
char *name;
# the kernel module c code which stap compiled to.
l->__retvalue = uderef(8, ((((((int64_t) (/* pragma:vma */ (
{
unsigned long addr = 0;
addr = _stp_umodule_relocate ("/usr/local/openresty/nginx/sbin/nginx", 0x2704e0, current);
addr;
}
))))) + (((int64_t)8LL)))));STAP脚本语言中提供很多有用的语法糖,比如@var,用来指定一个可执行文件和其中的全局变量,在STAP中就可以直接访问这个这个变量的任意属性。
STAP编译器会帮助我们定位该变量在进程中的实际地址,并解析该变量所代表的数据结构的内存布局,最终真正找到我们想去访问的字段的偏移值。使用uderef这种直接读取用户进程内存的系统调用,来获取我们想访问的,ngx_http_module的index。
stapxx
index = @var("ngx_http_module", "$^exe_path")->index
V
index = @var("ngx_http_module", "/xxx/nginx")->index
sudo stap \
-k \ -x $NG_PID \
-d $target/nginx/sbin/nginx \
-d $target/luajit/lib/libluajit-5.1.so.2.1.0 \
-d /usr/lib/ld-linux-x86-64.so.2 \
... 省略
./all-in-one.stap在实际使用场景中,我们更倾向于通过stapxx工具集中的stap++[3]来写STAP脚本。
直接写STAP脚本需要指定具体的可执行文件路径,并且在运行参数中使用-d选项来指定所有需要的符号文件。
相比之下,stapxx 能够自动执行变量替换、文件合并和符号查找等任务,使得使用过程更加便捷。基本上,我们只需要指定 Nginx 的进程 ID(PID)即可。
lj-lua-stacks就是这样一个使用stap++编写的STAP脚本。
Lua级别的火焰图
Nginx/Openresty/LuaJIT 在进程内存中的数据结构

每个 Nginx 工作进程的上下文都是由 ngx_cycle 结构作为根,其中包含了所有 Nginx 模块的指针,包括 ngx_http_module。在 ngx_http_module 中,就包含了 OpenResty 的 ngx_http_lua 模块。
在ngx_http_lua中的Lua指针,指向的是lua_state,一个代表luavm所有状态的结构。
对于一个luavm来说,有一个所有协程共享的global_state,每个协程有一个自己的lua_state,在global_state上cur_L指向当前在执行的那个协程的lua_state。
我们当前执行的函数可能是Lua函数(纯Lua或者被JIT编译的Lua),可能C函数。
在执行纯 Lua 函数的情况下,cur_L 的栈(stack)和基指针(base)之间的地址范围定义了我们函数调用的堆栈地址范围。
对于 JIT 编译过的代码,全局状态的 jit_base 到 cur_L 的栈顶是其函数调用栈的地址范围。
总的来说,在任何给定时刻,进入一个 Nginx 进程,我们总是可以从 ngx_cycle 开始,找到当前正在执行的 Lua 函数的调用栈。
Lua虚拟机的调用栈(call stacks)

对于每个调用栈,它的每一层都由一个帧(frame)组成,每个帧相当于链表中的一个节点,链接指向下一个帧。
对于每个帧,我们可以通过它指向的 gcobj(垃圾回收对象)来访问 gcfunc(垃圾回收的函数)。如果是 Lua 函数,我们最终可以获取该函数所在的 Lua 文件名以及该函数在文件中的行号。这里的 chunkname 就是指文件名。
如果 gcfunc 表示的是 C 函数,我们可以通过 usysname(用户系统名称)来获取 C 函数的名称。
实际上,这里最终获得的是 Lua 文件名和函数的行号。之后,我们还需要依据这两个信息来确定 Lua 函数的名称。只有找到 Lua 函数名之后,我们才能生成火焰图。
看看代码
这就是luajit_debug_dumpstack的具体过程。有兴趣的同学可以读下面的代码。
function luajit_debug_dumpstack(L, T, depth, base, simple)
bot = $*L->stack->ptr64 + @sizeof_TValue //@LJ_FR2
for (nextframe = frame = base - @sizeof_TValue; frame > bot; ) {
if (@frame_gc(frame) == L) { tmp_level++ }
if (tmp_level-- == 0) {
size = (nextframe - frame) / @sizeof_TValue
found_frame = 1
break
}
nextframe = frame
if (@frame_islua(frame)) {
frame = @frame_prevl(frame)
} else {
if (@frame_isvarg(frame)) { tmp_level++;}
frame = @frame_prevd(frame); }
}
if (!found_frame) { frame = 0 size = tmp_level }
if (frame) {
nextframe = size ? frame + size * @sizeof_TValue : 0
fn = luajit_frame_func(frame)
if (@isluafunc(fn)) {
pt = @funcproto(fn)
line = luajit_debug_frameline(L, T, fn, pt, nextframe)
name = luajit_proto_chunkname(pt) /* GCstr *name */
path = luajit_unbox_gcstr(name)
bt .= sprintf("%s:%d\n", path, line)
}
} else if (dir == 1) { break } else { level -= size }谜题揭晓
发现问题后,解决问题就变得相对容易。经过我们的排查,最终确定 Lua 火焰图中 metrics 部分处理时间长的原因是,我们使用的 Prometheus 客户端库没有针对多线程环境进行优化。
在升级了这一依赖库之后,metrics 部分的性能损耗降低到了一个可以接受的水平。
畅想未来
★随着软件架构的越来越复杂,完全的理解业务过程中,从用户使用到系统内核的每个关键路径的每个链条的每个细节越来越难。软件技术栈所搭建的巨塔越垒越高。我们需要更多的可观测性,照亮层层抽象导致的深渊。
”
SystemTap的问题所在
SystemTap存在一个无法回避的问题,即它最终是通过内核模块来执行的。由于在其脚本语言中可以编写原生的C函数,这可能导致如果脚本执行出现问题,可能会影响整个内核的稳定性。换句话说,如果SystemTap脚本引发错误,它有可能使整个系统崩溃。
尽管 SystemTap 在其编译过程中进行了严格的检查,但存在潜在的系统崩溃风险,这本身就是一个值得关注的问题。
可以发现,实际上我们要做的是:
-
在内存空间内,通过追踪指针来读取不同数据结构中的字段,以此遍历调用栈。
-
寻找方法来捕获每次调用栈中的函数名称。
理论上,eBPF完全有能力实现这些功能。鉴于此,既然已经到了2024年,我们为什么不考虑使用 eBPF进行重写呢?
构建模块
我们所需要的是:
1、将 eBPF附加到perf事件上。eBPF已经具备了这项能力,我们可以将一个eBPF程序附加到perf事件上。
2、确定每个变量的位置,了解每个需要访问的字段在内存中的确切位置。
Pahole
每个字段在结构体中的偏移量(offset),实际上已经以 DWARF 格式存在于可执行文件的符号表中。尽管存在像 pyelftools 这样的库可以简化解析过程,但手动编写一个解析器仍然是一项繁琐的工作。
所幸,我们有pahole[4]。只要提供可执行文件和我们想要查询的结构体名称,pahole 就能生成这些结构体的头文件。因此,实际上我们可以直接将生成的头文件包含(include)进来,然后开始访问各个字段。
pahole --compile -C GCobj,GG_State,lua_State,global_State /xx/luajit/lib/libluajit-5.1.so.2.1.0 >$out
sed -i '/.*typedef.*__uint64_t.*/d' $out
sed -i '/.*typedef.*__int64_t.*/d' $out
sed -i 's/Node/LJNode/g' $out
struct global_State {
lua_Alloc allocf; /* 0 8 */
void * allocd; /* 8 8 */
GCState gc; /* 16 104 */
/* --- cacheline 1 boundary (64 bytes) was 56 bytes ago --- */
GCstr strempty; /* 120 24 */
/* --- cacheline 2 boundary (128 bytes) was 16 bytes ago --- */
uint8_t stremptyz; /* 144 1 */
// ... 省略
}使用eBPF重写
作为一个Demo,理论上我们可以在 eBPF 中将 stap++ 脚本中的函数逐一翻译回 C 语言,并采用 eBPF 技术实现一个安全的观测nginx状态的工具。
#include <nginx.h>
#define READ_SRTUCT(ret, ret_t, p, type, access) \
do { \
type val; \
bpf_probe_read_user(&val, sizeof(type), p); \
ret = (ret_t)((val)access); \
} while (0)
void *GLP = (void *)0x7cc2e558c380; // TODO
void *luajit_G(){
void *ret;
READ_SRTUCT(ret, void *, GLP, lua_State, .glref.ptr64);
return ret;
}
void *luajit_cur_thread(void *g){
void *gco;
size_t offset = offsetof(struct global_State, cur_L);
READ_SRTUCT(gco, void *, g + offset, struct GCRef, .gcptr64);
// gco is a union, th is lua_State and the point of th is gco itself
// return &@cast(gco, "GCobj", "")->th
return gco;
}