参考:https://github.com/yizhongw/self-instruct
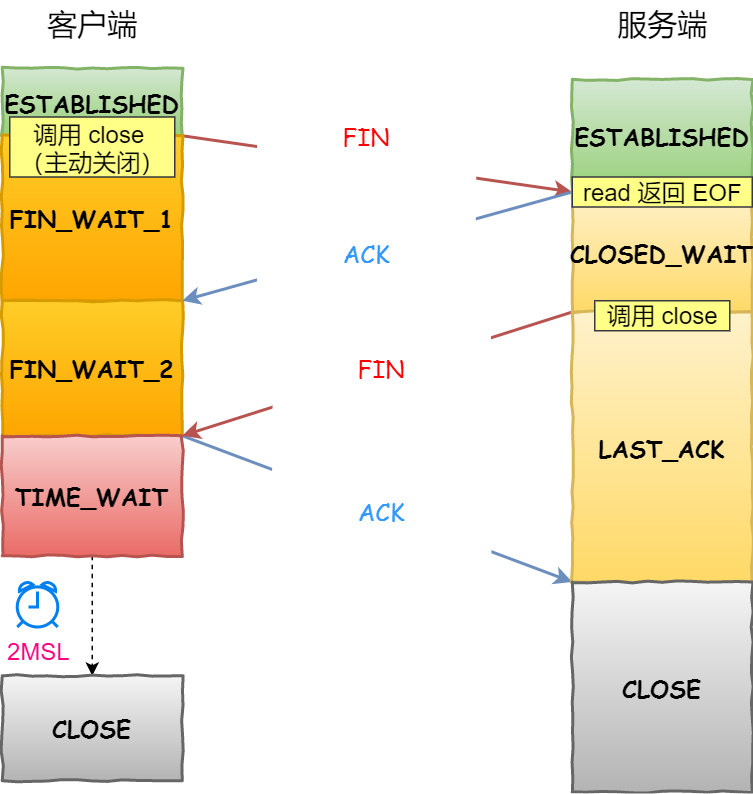
总体来说就是 大模型自己遵循一套流程来生成数据,然后来微调自己。

1.指令生成
每一个迭代都选8个任务的指令作为该任务的提示样本,其中6个是人写的,2个是生成的。
然后组成输入送入模型进行输出引导,直到达到token限制或者够16个任务。

2.指令分类
作者对于分类任务和非分类任务的后续处理是不同的,所以用少样本学习提示的方式让LLM判断是否任务为分类。
3.实例生成
根据指令及其任务类型,独立地为每个指令生成实例。
针对分类和非分类任务,使用两种不同的Prompt构造方法:
1).输入优先:主要针对生成类任务,要求LM根据指令优先 生成实例中的输入X,然后再产生相应的输出Y。
2).输出优先:主要针对分类任务,给定指令,首先生成可能的类别标签,再根据类别标签生成输入X。避免生成偏向某一标签的输入。
4.筛选与后处理
筛选标准:
1.只有当新指令与任何现有指令的ROUGE-L相似度小于0.7时,才将其添加到任务池中。
2.还排除通常不能被语言模型处理的指令,包含某些特定关键词(例如,图像、图片、图表)。
3.在为每个指令生成新实例时,过滤掉完全相同或具有相同输入但不同输出的实例。
总结指标
1.ROUGE-L
来源
ROUGE是一种广泛使用的自动文本评估指标,用于比较生成文本和参考文本之间的相似度。
ROUGE可以看做是BLEU 的改进版,专注于召回率而非精度。换句话说,它会查看有多少个参考译句中的 n 元词组出现在了输出之中。
生成文本C和参考文本S。L代表LCS,最长公共子序列。
R LCS 表示召回率,表示参考文本中有多少内容被生成文本所覆盖。
P LCS 表示精确率,表示生成文本中有多少内容与参考文本匹配。
F LCS 是 ROUGE-L。

取值区间:通常在 0 到 1 之间。0: 表示生成的文本与参考文本完全不匹配。1: 表示生成的文本与参考文本完全匹配,所有的词序列都对齐。
2.BLEU
来源
通过计算生成文本中的 n-gram(n 个连续词语序列)与参考文本中的 n-gram 的匹配情况来评估文本质量。常用的 n 值包括 1(unigram)、2(bigram)、3(trigram)和 4(4-gram)。
1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。

lc是生成文本的长度,lr是参考文本的长度。
wn是指n-gram的权重,默认为1/n。
pn是指n-gram 的精确率,也就是c和r中的n-gram的匹配数量 / c的n-gram数量。
BP指惩罚因子,避免生成文本过短导致精确率过高。当生成文本大于参考文本的长度,设为1;小于等于参考文本的长度时,设为e^(1-lr/lc)。
Self-BLEU 是一个用于评估生成文本集合多样性的指标。它的核心思想是利用 BLEU 指标来衡量一个句子与同一生成集合中其他句子的相似性,从而间接评估整个集合的多样性。
计算方法:
将集合中的每个生成句子分别作为假设句(hypothesis),将集合中的其余句子作为参考句(reference),计算每个句子的 BLEU 分数。
然后对所有句子的 BLEU 分数取平均值,这个平均值就是该集合的 Self-BLEU 分数。
取值区间:通常在 0 到 1 之间。0: 表示生成的文本与参考文本没有任何匹配的 n-gram。1: 表示生成的文本与参考文本完全匹配。
3.Distinct-N
是一种测量句子多样性的指标。它关注一个句子中不同n-gram的数量。不同n-gram的数量越多,文本的多样性越高。

Count(unique ngram)表示回复中不重复的ngram数量,Count(word)表示回复中ngram词语的总数量。
取值区间: Distinct 指标的取值范围在 0 到 1 之间。0: 表示生成文本中的 n-gram 完全重复,没有任何多样性。1: 表示生成文本中的每个 n-gram 都是独一无二的,具有最大的多样性。
参考:
https://zhuanlan.zhihu.com/p/144182853
https://mindnlpdocs-hwy.readthedocs.io/zh-cn/latest/api/engine/metrics.html#module-mindnlp.engine.metrics.distinct
https://github.com/geek-ai/Texygen/blob/master/docs/evaluation.md#self-bleu-score
https://blog.csdn.net/weixin_43937790/article/details/129767661