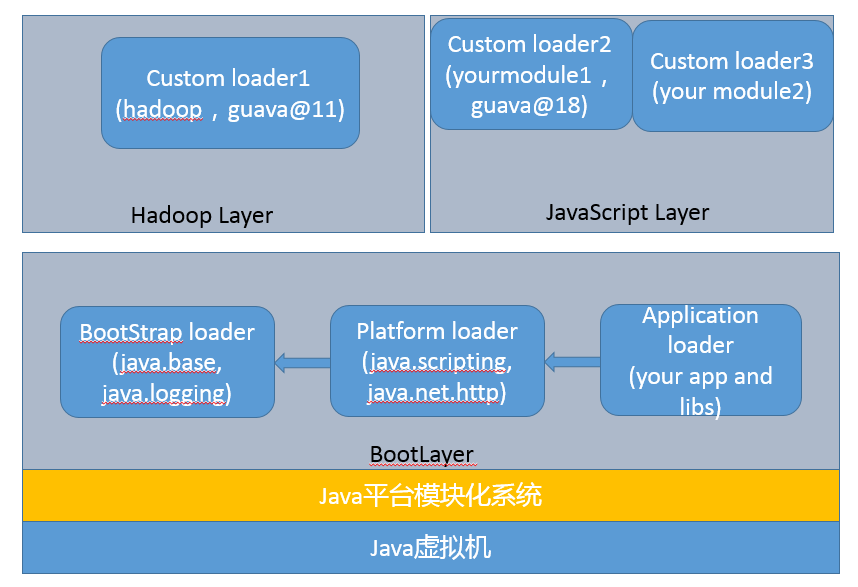
这可不是目录
- 入门
- 定义与说明
- 数据分析
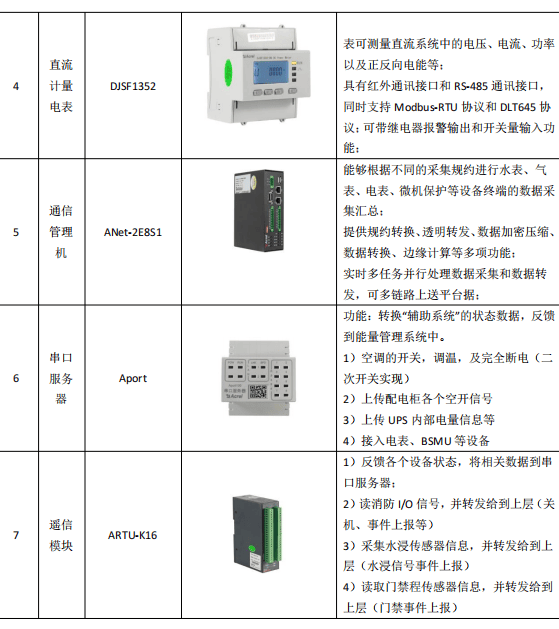
- Map和Reduce阶段的任务
- <Kn,Vn>分析
- MapReduce的数据类型
- 其他说明(持续更新)
- 开发案例(持续更新)
- 自定义的wordcount
- csv文件操作
- 序列化操作
入门
定义与说明
数据分析
以下未数据分析示意图

Map和Reduce阶段的任务
- Map阶段的任务:一个map通常处理一个切片,当数据量过大时会存在多个map
- Reduce阶段的任务:对Map输出的键值对进行汇总、聚合,但reduce的数量根据输出要求决定
- Map和Reduce没有一一对应的关系
- 一个job允许有多个·Map和多个Reduce,部分情况允许没有Reduce
<Kn,Vn>分析
接上述Map和Reduce阶段的任务和数据分析
Map
一般而言,Map阶段会产生两个<k,v>键值对
<k1,v1>通常表示数据的输入,k1:偏移量(不重要,一般指输入);v1:原始数据
<k2,v2>是这个Map阶段的切片输出,k2:类别(按需要切分);v2:自定义输出的切片结果
Reduce
一般而言,Reduce阶段会产生两个<k,v>键值对
<k3,v3>一般是承接的map阶段的输入,k3:来自于k2,和k2类型相同;v3:集合形式的v2
<k4,v4>MapReduce的输出,k4:一般来源于k3,和k3类型相同;v4:自定义的汇总、聚合输出
MapReduce的数据类型

使用时可以考虑先转String类型进行操作,在进行输出时,可以再转为MapReduce的数据类型
其他说明(持续更新)
- org.apache.hadoop.mapred是Hadoop 1.x的版本
- 打包时,请将所有需要的jar包一起
- 每一阶段的输出类型必须是hadoop定义的类型(如上)
- k1一般不重要,基本是你的文件或者数据输入
- Reduce阶段一般是最后的输出阶段,当然前提是你的MapReduce流程中含有Reduce
开发案例(持续更新)
自定义的wordcount
这可不是链接 = =
csv文件操作
这可不是链接 = =
序列化操作
这可不是链接