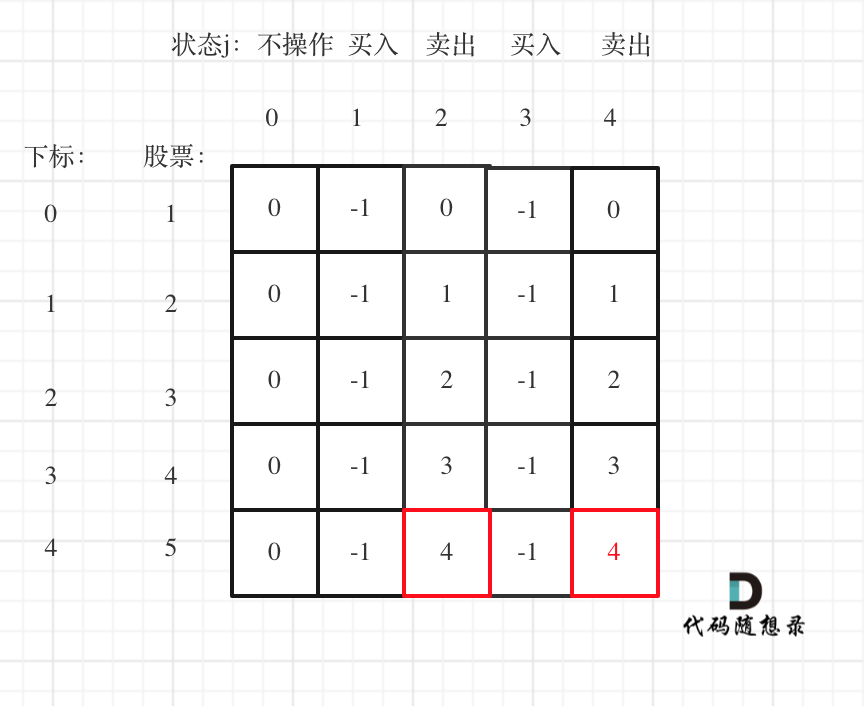
引言
正如有句话说的好,neurons-that-fire-together-wire-together(一同激活的神经元关联在一起)
文章目录
- 引言
- 一、反向传播算法的直观解释
- 1.1 前向传播
- 1.2 计算误差
- 1.3 反向传播误差
- 1.4 更新权重
- 二、微积分原理
- 2.1 损失函数 L L L
- 2.2 链式法则的应用
- 2.3 计算梯度
- 2.4 权重的梯度
- 2.5 总结
- 三、链式法则
- 四、反向传播中的链式法则
- 4.1 前向传播
- 4.2 计算损失函数对输出的梯度
- 4.3 反向传播
- 4.4 计算对权重的梯度
- 4.5 更新参数
- 4.6 总结
一、反向传播算法的直观解释
想象一下,正在组装一个复杂的装置,这个装置由许多组件组成,每个组件都对最终的输出有影响。现在,如果发现输出不正确,需要找出哪些组件导致了这个问题,并相应地调整它们
1.1 前向传播
- 你向装置输入一个信号,这个信号通过一系列组件传递,每个组件都会对信号进行一些处理(比如放大或减弱)
- 最终,信号到达输出端,你得到了一个结果
1.2 计算误差
- 你将得到的结果与期望的结果进行比较,计算它们之间的差异,这个差异就是误差
1.3 反向传播误差
- 现在,你需要找出每个组件对最终误差的贡献。你从输出端开始,逆向检查每个组件
- 对于每个组件,你计算它对最终误差的影响有多大。如果某个组件对误差的影响很大,那么它很可能就是问题所在
1.4 更新权重
- 一旦你知道了每个组件的影响,你就可以调整它们,使得下次输入相同的信号时,输出更接近期望值
- 你根据每个组件对误差的贡献来调整其设置(在神经网络中,这些设置就是权重)
这个过程需要反复进行,每次输入信号后,你都要计算误差,然后反向传播这个误差,并更新组件的设置
二、微积分原理
反向传播算法的数学基础是微积分中的链式法则。以下是链式法则在反向传播中的应用:
2.1 损失函数 L L L
- 损失函数衡量了网络预测值 y ^ \hat{y} y^ 与真实值 y y y 之间的差异。常见的损失函数有均方误差(MSE)和交叉熵损失
2.2 链式法则的应用
- 假设神经网络有一个输出层和一个隐藏层。输出层的激活函数为 f f f,隐藏层的激活函数为 g g g
- 根据链式法则,损失函数
L
L
L对隐藏层输出的导数可以表示为:
∂ L ∂ g = ∂ L ∂ f ⋅ ∂ f ∂ g \frac{\partial L}{\partial g} = \frac{\partial L}{\partial f} \cdot \frac{\partial f}{\partial g} ∂g∂L=∂f∂L⋅∂g∂f - 这意味着,为了计算损失函数对隐藏层输出的导数,我们需要知道损失函数对输出层输出的导数(输出层的梯度),以及输出层输出对隐藏层输出的导数(隐藏层到输出层的权重)
2.3 计算梯度
- 对于输出层,我们可以直接计算损失函数对输出层激活值的导数
- 对于隐藏层,我们需要将输出层的梯度与输出层和隐藏层之间的权重相乘,然后乘以隐藏层激活函数的导数(即 ∂ g ∂ z \frac{\partial g}{\partial z} ∂z∂g,其中 z z z 是隐藏层的线性组合)
2.4 权重的梯度
- 最后,我们计算损失函数对每个权重的导数。这涉及到将损失函数对激活值的导数与激活值对权重的导数相乘
- 对于权重
w
w
w 来说,其梯度可以表示为:
∂ L ∂ w = ∂ L ∂ g ⋅ ∂ g ∂ z ⋅ ∂ z ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial g} \cdot \frac{\partial g}{\partial z} \cdot \frac{\partial z}{\partial w} ∂w∂L=∂g∂L⋅∂z∂g⋅∂w∂z - 其中, ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z 就是隐藏层的输入。
2.5 总结
通过这种方式,反向传播算法能够计算出损失函数对每个权重的梯度,然后我们可以使用这些梯度来更新权重,以减少损失函数的值。这个过程不断重复,直到网络性能达到一个满意的水平。

三、链式法则
链式法则是微积分中的基本法则,用于计算复合函数的导数。假设我们有两个函数
f
(
x
)
f(x)
f(x)和
g
(
x
)
g(x)
g(x),它们复合成一个新函数
h
(
x
)
=
f
(
g
(
x
)
)
h(x) = f(g(x))
h(x)=f(g(x))。链式法则告诉我们如何计算
h
h
h对
x
x
x的导数:
h
′
(
x
)
=
f
′
(
g
(
x
)
)
⋅
g
′
(
x
)
h'(x) = f'(g(x)) \cdot g'(x)
h′(x)=f′(g(x))⋅g′(x)
换句话说,复合函数的导数等于内函数的导数乘以外函数的导数
四、反向传播中的链式法则
在神经网络中,每一层的输出都是下一层的输入,这形成了一个复杂的函数复合结构。反向传播算法通过链式法则来计算损失函数 L L L对网络中每个参数的梯度
以下是反向传播中链式法则的应用步骤:
4.1 前向传播
- 输入样本通过网络,每层计算其输出,直到最后一层产生预测值 y ^ \hat{y} y^
- 计算损失函数 L ( y ^ , y ) L(\hat{y}, y) L(y^,y),其中 y y y是真实标签
4.2 计算损失函数对输出的梯度
- 首先计算损失函数对网络输出的梯度,即 ∂ L ∂ y ^ \frac{\partial L}{\partial \hat{y}} ∂y^∂L
4.3 反向传播
- 从输出层开始,使用链式法则计算损失函数对每个参数的梯度。
- 对于网络中的每一层
l
l
l,假设其输入是
z
(
l
)
z^{(l)}
z(l),激活函数是
a
(
l
)
=
σ
(
z
(
l
)
)
a^{(l)} = \sigma(z^{(l)})
a(l)=σ(z(l)),那么链式法则可以表示为:
∂ L ∂ z ( l ) = ∂ L ∂ a ( l ) ⋅ ∂ a ( l ) ∂ z ( l ) \frac{\partial L}{\partial z^{(l)}} = \frac{\partial L}{\partial a^{(l)}} \cdot \frac{\partial a^{(l)}}{\partial z^{(l)}} ∂z(l)∂L=∂a(l)∂L⋅∂z(l)∂a(l) - 其中, f r a c ∂ L ∂ a ( l ) frac{\partial L}{\partial a^{(l)}} frac∂L∂a(l)是从下一层传递回来的梯度, ∂ a ( l ) ∂ z ( l ) \frac{\partial a^{(l)}}{\partial z^{(l)}} ∂z(l)∂a(l)是激活函数的导数
4.4 计算对权重的梯度
- 对于层
l
l
l 中的每个权重
w
(
l
)
w^{(l)}
w(l),其梯度可以表示为:
∂ L ∂ w ( l ) = ∂ L ∂ z ( l ) ⋅ ∂ z ( l ) ∂ w ( l ) \frac{\partial L}{\partial w^{(l)}} = \frac{\partial L}{\partial z^{(l)}} \cdot \frac{\partial z^{(l)}}{\partial w^{(l)}} ∂w(l)∂L=∂z(l)∂L⋅∂w(l)∂z(l) - 其中, ∂ z ( l ) ∂ w ( l ) \frac{\partial z^{(l)}}{\partial w^{(l)}} ∂w(l)∂z(l)是输入 x ( l ) x^{(l)} x(l)或前一层的激活 a ( l − 1 ) a^{(l-1)} a(l−1)
4.5 更新参数
- 使用计算出的梯度来更新网络的权重和偏置。
4.6 总结
通过这种方式,反向传播算法能够有效地计算出损失函数对网络中每个参数的梯度,从而允许我们使用梯度下降或其他优化算法来训练神经网络。链式法则是实现这一过程的关键数学工具


![[Redis] Redisson分布式锁原理及源码分析](https://i-blog.csdnimg.cn/direct/73bba12a523e4015b3f41dc2d381b7ad.png)