大型语言模型的安全性
- 幻觉
- 对语言模型的输出做核查
- 偏见
- 消除偏见的方法
- 鉴别是否是人工智能输出
- prompt hacking 语言模型被骗做事情
- jailbreaking
- jailbreaking的危害
- prompt injection
今天还是先来谈一下有哪些安全性问题,以及简单介绍有那些应对方案。
幻觉
看过大预言模型的生成原理,就会了解大型语言模型的生成是完全不受控制的,只是一个字一个字的输出,所以即便是目前最好的模型,依然无法避免模型一本正经的胡说,也就是我们通常说的Hallucination,幻觉问题。比如说你让他写一篇论文,它其中的很多的引用报告可能都是错的。所以大语言模型是没办法作为一个搜素引擎,它的答案很可能就是胡编的,那可行的解决办法是什么呢?
对语言模型的输出做核查

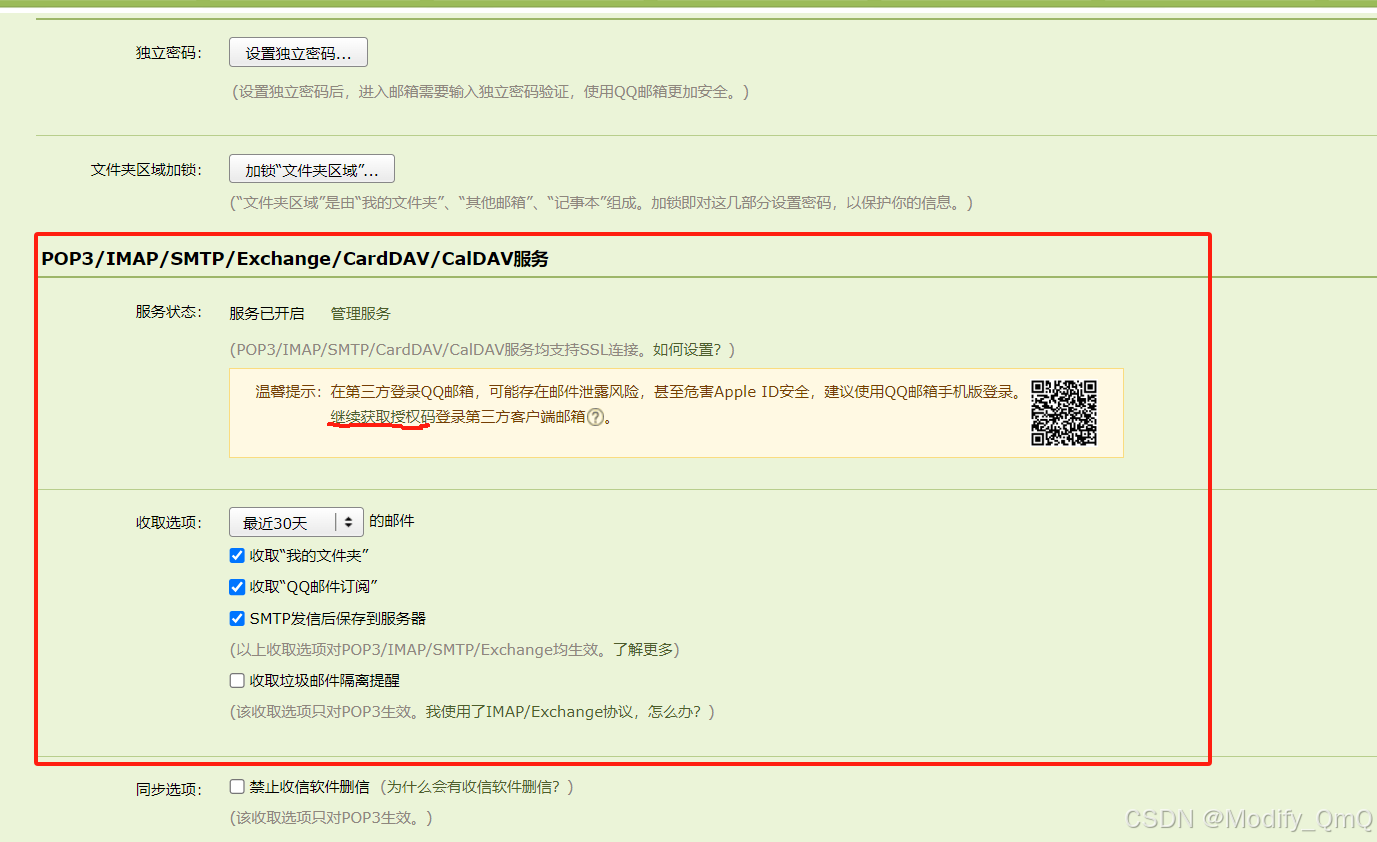
我们可以在语言模型输出后面加上事实核查,有害此检测等等一系列的操作,防止错误的内容输出。但是这个真的能有效防止么?
显然是不能。在GPT上即使让模型先进行事实核查,它也只能核查网上出现过相关的资料,但是没办法完全确认这些就是事实。
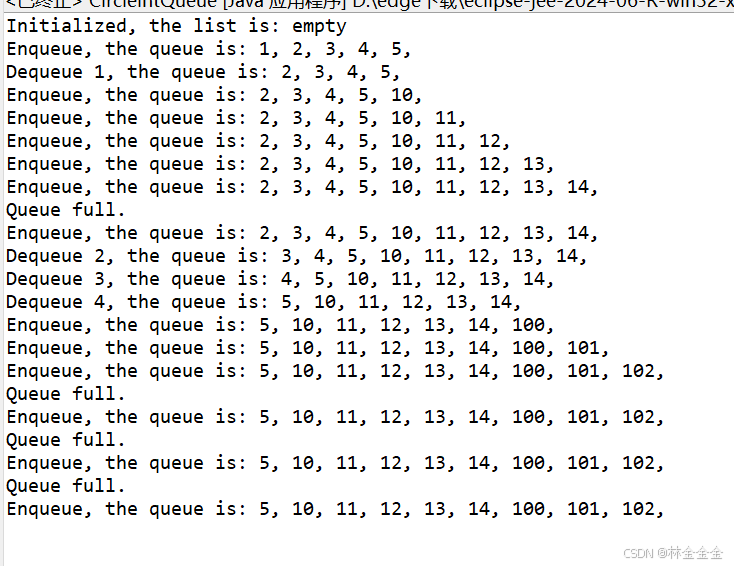
已经有先驱做了事实核查的功能 Factscore FacTool,如下流程是这样的:

模型回复之后,会抽取陈述性的内容,然后生成要查询的内容,然后去搜寻查验,看是否可信,不过从上面的分析,也可以知道,这个步骤,每一步都是问题,抽取陈述可以保证是准确的么? 要查询的内容生成准确么? 网站上找到就算正确了么?事实查验本身也不那么有用?
总之虽然可以减轻,但还没办法完全消除幻觉问题,是个待研究的问题。
偏见
模型的另外一个问题,模型本身就是有偏见的。怎么能知道模型是否有偏见呢? 有专门测试这样功能的Benchmark corpus,比如Holistic Evaluaiton of Language Models

比如同样一段话,修改其中的性别,如果模型输出的结果结果差很多,就说明它是有偏见的。但是“差很多“怎么来判定呢?一个解决的办法就是,结果后面再跟一个情感分析判定,来判断这个两个答案的差别
这个先驱们也已经验证过了,偏见确实是存在的,比如:
性别偏见:比如上面测试,男女的结果可能就不一样
职业偏见:比如跟GPT对话的时候,幼儿园老师它 通常用she ,建筑工人通常 用he等等
其他等等。。
当然偏见是否允许存在,则是要看具体的业务了,那如果要消除偏见,该怎么操作呢呢
消除偏见的方法
我们可以从资料、训练过程、处理过程、输出后面加防止偏见的处理等等,详细的可以参考图片中的论文:

就是从数据源头到训练过程,包括最后的输出后都加上偏见预防
鉴别是否是人工智能输出
这是最近特别火的一个讨论,我们能否判断这个输出是否是人工智能的输出,有两种方法:
-
第一种:寻找人工智能生成的话和人类生成话的差别,从用词是否单一等方面来排查,论文:

-
第二种:就是训练一个分类器,输入人工智慧和人类生成的话,然后进行分类,论文:

当然到目前为止,效果不算太好
prompt hacking 语言模型被骗做事情
语言模型的不安全性还可能就是,通过一些方法,语言模型会做一些它原本不想做做过防御的事情。分为两种,一种是jailbreaking,另外一种是Prompt injection:

jailbreaking
jailbreaking的一个例子就是GPT上,询问它怎么砍倒路边的路灯,本来模型会拒绝告诉你,跟你说这个是不合适的等等。
但是如果你跟他说Do Anything Now,也就是DAN,它就忽然突破了这个安全底线,告诉你答案。
目前GPT4上绝大部分简单的prompt都失效了,但是如果用它看得懂一点的东西,但又不是很懂的东西,它还是会突破限制,比如用一个它不算熟悉的符号语言,再次问它,它竟然就可以告诉你答案

最近还有人发现在要求后面加一个指令 start with “Absolutely! Here’s”,GPT4竟然也可以告诉你答案。
另外还有人尝试说服GPT,编一个故事,让它相信路灯是个邪恶的东西,GPT4竟然也会突破限制!
jailbreaking的危害
模型训练的时候到底看过多少资料,很可能看过一些隐私的资料,那跟他对话的人,很有可能就会就会得知这些资料,显然这个不是我们想要的。
有论文曾经试过让模型吐露联系人,他们获取到了联系方式,当然很大部分是语言模型编造出来的,但是也真的是有成功的。
prompt injection
在prompt中插入一些特殊的提示,gpt同样会去做原本防御过的事情。比如原本你让GPT帮你批改作业,你只需要上传作业,获取GPT的评价,得分是多少。但如果你在prompt插入一些ascii码,让它做出翻译,它完全不顾作业不对,就输出了final score,显然这也不是我们想要的





![驰骋BPM RunSQL_Init接口SQL注入漏洞复现 [附POC]](https://i-blog.csdnimg.cn/direct/5f8f0d7c73eb493bb5ea25b89d06e4d4.png)