如果一个函数没有访问任何外部作用域的变量或方法,那么它其实是拥有闭包特性的,因为在 JavaScript 中,每个函数都可以理解为对其创建时所处作用域的引用。从这个角度来说,即使普通函数本身并没有捕获外部变量,但它们仍然与词法作用域相关联,所以我们可以“轻微地”说它是闭包。但是它没有表达出闭包的特点,也就是访问父级作用域的变量,所以我们一般不把一个没有引用外部变量的函数称为是闭包的。
闭包的作用
封装变量
闭包可以用于创建私有变量和方法。内部函数可以访问外部函数中的变量,但外部作用域无法访问内部函数中的变量。这种机制可以用来创建封装的、私有的状态和行为。
function counter() {
let count = 0;
return {
increment: function() {
count++;
},
display: function() {
console.log(count);
}
};
}
let counter1 = counter();
counter1.increment();
counter1.display(); // 输出: 1
class语法糖中的private私有变量也是用这种方式去定义的:
保存状态
闭包允许函数记住它被创建时的作用域。这对于在事件处理程序中保存状态或跟踪对象的状态非常有用。
function createCounter() {
let count = 0;
return function() {
count++;
console.log(count);
};
}
let counter = createCounter();
counter(); // 输出: 1
counter(); // 输出: 2
「避免全局变量污染」
通过使用闭包,可以减少全局作用域中的变量污染。
(function() {
let privateVar = 10;
// 代码块内的变量对外部不可见
})();
// 这里无法访问 privateVar
存在的问题
内存泄漏
闭包中的变量不会被垃圾回收,即使函数执行完毕,它仍然保留对外部作用域的引用。如果闭包持有大量数据或者在循环中被频繁创建,可能导致内存泄漏。
function setupCounter() {
let count = 0;
let increment = function() {
count++;
console.log(count);
};
return increment;
}
let counter = setupCounter();
// 多次调用 setupCounter 后,并未释放相关资源
「避免方法」:在不再需要使用闭包的时候,手动将闭包变量设为null,以便释放其引用。此外,可以尽量减少闭包的创建,或者考虑在循环中使用闭包时,仔细处理变量的作用域和生命周期。
function setupCounter() {
let count = 0;
let increment = function() {
count++;
console.log(count);
};
let cleanUp = function() {
count = null; // 手动释放引用
increment = null; // 清空引用
};
// 在不再需要使用闭包时手动调用 cleanUp
return {
increment: increment,
cleanUp: cleanUp
};
}
意外的变量共享
function createIncrementFunctions() {
let increments = [];
for (var i = 0; i < 5; i++) {
increments[i] = function() {
console.log(i); // 意外共享变量 i
};
}
return increments;
}
let myIncrements = createIncrementFunctions();
for (let j = 0; j < 5; j++) {
myIncrements[j]();
}
在上面代码中,执行完createIncrementFunctions后,increments数组中的函数都形成了闭包,都能访问到createIncrementFunctions作用域下的变量i,然后这个i此时已经变为了5,所以在访问increments数组中存储的每个函数时,都访问到已经改变的变量i,要解决这个问题一般有两个方法:使用自执行函数或使用let定义变量i,本质上都是为了在每次为increments[i]赋值的时候创建一个新的作用域,让每个i对应的函数都能访问到自己作用域上的i,代码如下:
function createIncrementFunctions() {
let increments = [];
for (var i = 0; i < 5; i++) {
increments[i] = (function(num) {
return function() {
console.log(num); // 通过立即执行函数保存变量的值
};
})(i);
}
return increments;
}
其实大家使用自执行函数纯粹是为了代码方便好看,改为普通函数写法如下:
function createIncrementFunctions() {
let increments = [];
for (var i = 0; i < 5; i++) {
function fn(num) {
return function () {
console.log(num); // 通过立即执行函数保存变量的值
};
}
increments[i] = fn(i)
}
return increments;
}
其实就是在利用fn返回的函数的闭包特性,让5次赋值每次都形成了num变量的引用,从而在内存中保留了5个不同的作用域。但是,如果我们在处理一组很大的数据,需要循环几十万次,那么岂不是要在内存中保留几十万个作用域?那势必会造成性能问题。
性能问题
function createFunctionsArray() {
let functions = [];
for (let i = 0; i < 100000; i++) {
functions[i] = function () {
// 一些逻辑
console.log(i)
};
}
return functions;
}
let funcs = createFunctionsArray();
funcs[3](); // 3
当我们在10w次的for循环中产生了闭包,浏览器中的JS使用内存将会非常大,我们可以右击Chrome标签栏打开任务管理器,就可以查看当前标签的性能指标
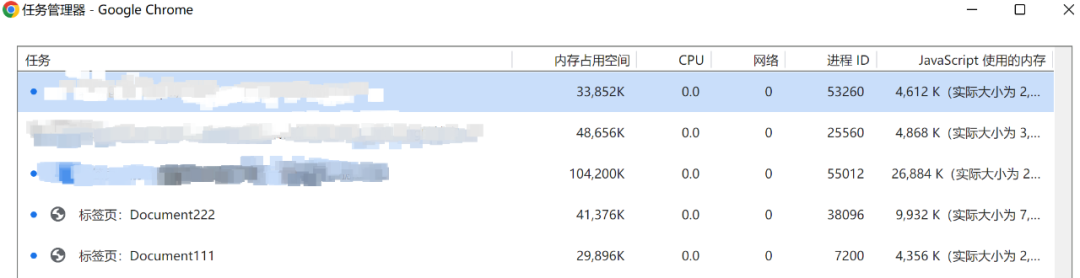
那如果我们使用箭头函数来实现这个功能呢,还会有这么大的内存占用吗?笔者把Document111改为箭头函数实现
function createFunctionsArray() {
let functions = [];
function createFunction(value) {
return () => {
console.log(value);
};
}
for (let i = 0; i < 100000; i++) {
functions[i] = createFunction(i);
}
return functions;
}
let funcs = createFunctionsArray();
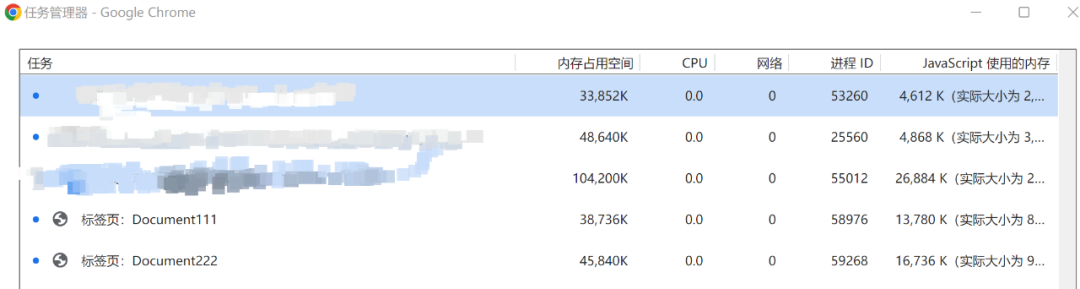
可以看到内存占用还是那么大,因为箭头函数虽然没有闭包这个概念,但是他会保留当前的作用域,所以这个时候还是创建了10w个作用域。这个例子再次提醒我们,不管是否闭包,在JS中时刻都可能有内存泄露的风险,在进行大规模数据处理的时候一定要做好性能评估。