B站千亿级点赞系统服务架构设计
原文链接:https://www.bilibili.com/read/cv21576373/
原文作者:哔哩哔哩技术团队-芦文超
点赞的功能太过于简单不再赘述,大家可以点击原文链接简单看下便可知晓。
本讲结合B站知名UP主陆总监的一期视频(https://www.bilibili.com/video/BV1mw4m1k71M)来做对比讲解。
表结构设计
陆总监的视频中提出的表结构方案
点赞关系表:主键ID,用户ID,内容ID,点赞时间。如果需要分表,则可以按照用户ID或内容ID来做。
内容的点赞总数表:内容ID,点赞数量
B站点赞系统的表结构方案
点赞记录表 - likes : 每一次的点赞记录(用户Mid、被点赞的实体ID(messageID)、点赞来源、时间)等信息,并且在Mid、messageID两个维度上建立了满足业务求的联合索引。
点赞数表 - counts : 以业务ID(BusinessID)+实体ID(messageID)为主键,聚合了该实体的点赞数、点踩数等信息。并且按照messageID维度建立满足业务查询的索引。
相同点与不同点
其中的用户Mid中的M为member,B站本身对会员有普通会员与大会员的区别。实体ID与陆总监提出的内容ID意思一样。点赞系统在互联网行业爆发之初就已经存在了,所以表结构的设计方式基本一样。
分库分表的方式也是一样的。不同点是B站的数据库采用TiDB,属于弹性数据库,不需要分库分表。陆总监视频中提到的数据库为MySql,再需要分库分表的场景下可以通过用户ID或内容ID来作为分片Key.
分片key是什么
表分片的意思是把一大张表的数据分割到不同的表中,除了表主键ID外,还需要一个统一的ID作为分片key,这样在操作数据库的时候可以快速的定位到要操作的数据存放在哪一张分片表中,不用一张表一张表的找了。比如用内容id作为分片key,就会尽可能的把内容id相同的数据存放到一个分片中,加快查询速度。

核心争议点-到底用不用缓存?
陆总监视频中说的很明确,俩字:看量!
如果点赞的请求量本来就很小,那么直接使用mysql以及对应的两表设计足够了。
量大了怎么办?会带来怎样的问题呢?
前面的表结构设计中我们了解到,无论是B站还是陆总监给出的方案,都有一张点赞数表:
内容的点赞总数表:内容ID,点赞数量
当有大量的点赞操作高并发的方式修改点赞总数表中的某一条视频的点赞数量时,会针对表中的这条记录产生一个“行锁”,这个行锁是悲观锁,简单说就是只有抢到锁的人才能修改点赞数,其他人要排队等到修改完成锁释放后再取竞争锁。如果点赞请求并发量很高,排队时间就会很长。

排队时间长会导致如下的问题:
1.上下游服务会因为排队问题导致调用接口超时。
2.过多的用户排队也占用了太多的数据库链接,数据库链接被耗尽后会导致系统崩溃。
解决方案:
陆总监给出的解决方案,使用MQ:
把用户的点赞请求交给MQ,让高并发请求变成队列,排队逐个访问数据库,并且加入队列的操作是异步的,能够及时返回上下游服务需要的结果,不会造成上下游服务调用超时,另外,数据库避免了高并发访问,连接池中的数据库链接也没有耗尽风险。

B站技术团队给出的解决方案:
先看原文:
针对写流量,为了保证数据写入性能,我们在写入【点赞数】数据的时候,在内存中做了部分聚合写入,比如聚合10s内的点赞数,一次性写入。如此可大量减少数据库的IO次数。
同时数据库的写入我们也做了全面的异步化处理,保证了数据库能以合理的速率处理写入请求。

原文解析:
把点赞数先在Redis缓存中进行汇总,汇总10秒后一次交给数据库更新。比如评论每秒500次点赞,则先在缓存中汇总10秒,10秒后汇总了5000次点赞后,向点赞总数表的指定字段只发出一条更新命令。
另外数据库写入也做了异步化处理,类似陆总监的MQ方案,写入点赞记录表之前先在缓存中进行汇总,然后交给MQ排队,针对数据库合理速率进行批处理写入。
无论是哪一种方案,只要量大,我们发现都采用了异步操作,异步操作都采用了MQ处理,这就带来一个问题:
我给一个视频点了赞,但是这个操作需要缓存10秒才能更新到数据库,我点赞后对应的视频的点赞按钮应当被点亮对吧,简单的解决方案就是用户点击点赞按钮后,前端做一个动态效果,切换按钮状态即可,但此时如果用户刷新了视频,按钮状态就会被复原。所以,缓存中应当保存用户的点赞列表。
用户点赞后,先存入缓存中的点赞列表里,即便用户刷新页面,前端加载后会调取缓存中的点赞列表,传入该视频的ID和点赞列表中的内容ID对比,如果存在,则点赞按钮被点亮。
具体是不是如此呢,我们展开B站点赞系统的整体架构仔细验证一下吧!
B站点赞系统整体架构
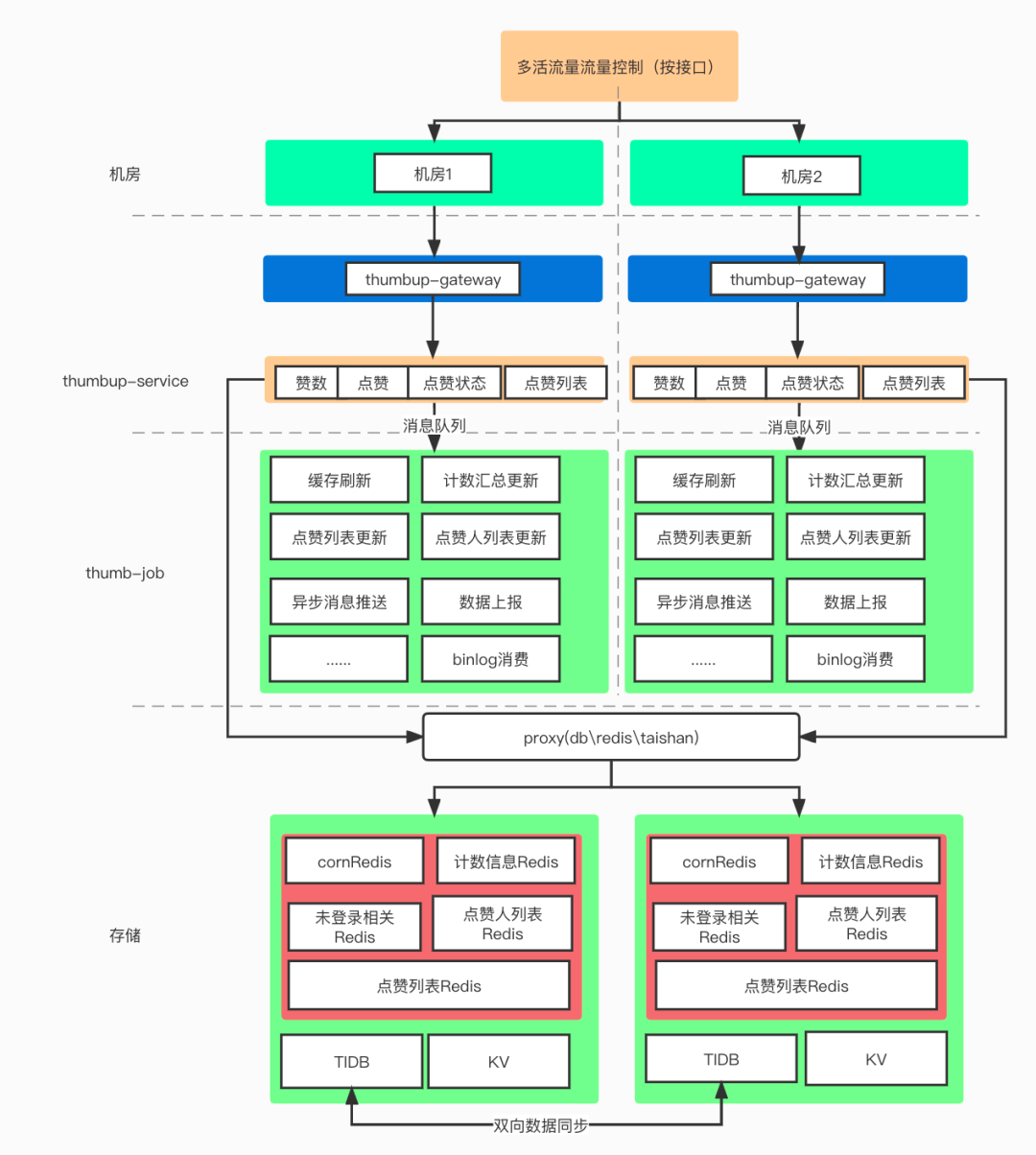
整个点赞服务的系统可以分为五个部分
-
流量路由层(决定流量应该去往哪个机房)
-
业务网关层(统一鉴权、反黑灰产等统一流量筛选)
-
点赞服务(thumbup-service),提供统一的RPC接口
-
点赞异步任务(thumbup-job)
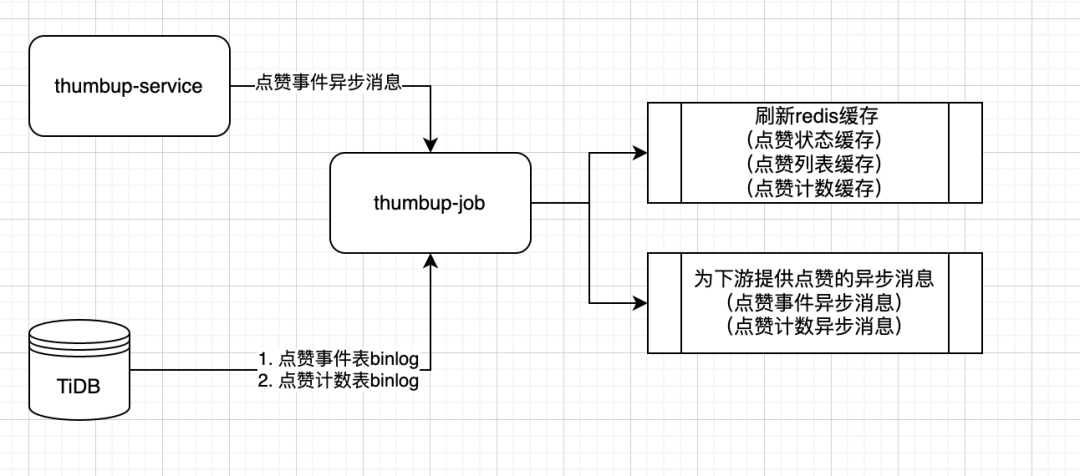
-
数据层(db、kv、redis)
黑灰产:搬运洗稿,刷粉刷量,养号交易等
下文将重点分享下**数据存储层、点赞服务层(thumbup-service)**与 **异步任务层(thumbup-job)**的系统设计
三级数据存储
基本数据模型:
- 点赞记录表:记录用户在什么时间对什么实体进行了什么类型的操作(是赞还是踩,是取消点赞还是取消点踩)等
- 点赞计数表:记录被点赞实体的累计点赞(踩)数量
第一层存储:DB层 - (TiDB)
重点是两张表:点赞记录表(likes)和点赞计数表(counts)
第二层存储
缓存层Cache:点赞作为一个高流量的服务,缓存的设立肯定是必不可少的。点赞系统主要使用的是CacheAside模式。这一层缓存主要基于Redis缓存:以点赞数和用户点赞列表为例
什么是CacheAside模式:Cache Aside(旁路缓存)是一种用于提高数据访问性能的策略,通过在数据仓库和缓存之间进行数据同步。这种模式处理了缓存数据一致性和过期的问题,但无法确保强一致性。比如在应用程序中,当需要访问某个数据时,Cache Aside 首先尝试从缓存中获取数据。如果缓存中不存在该数据,它会从数据库等数据源中获取数据,并将数据写入缓存。
①点赞数
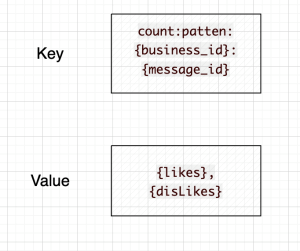
key-value = count:patten:{business_id}:{message_id} - {likes},{disLikes}用业务ID和该业务下的实体ID作为缓存的Key,并将点赞数与点踩数拼接起来存储以及更新
模拟数据如下:
具体的数据示例如下:
- 键:
count:patten:123:456 - 值:
42,10
②用户点赞列表
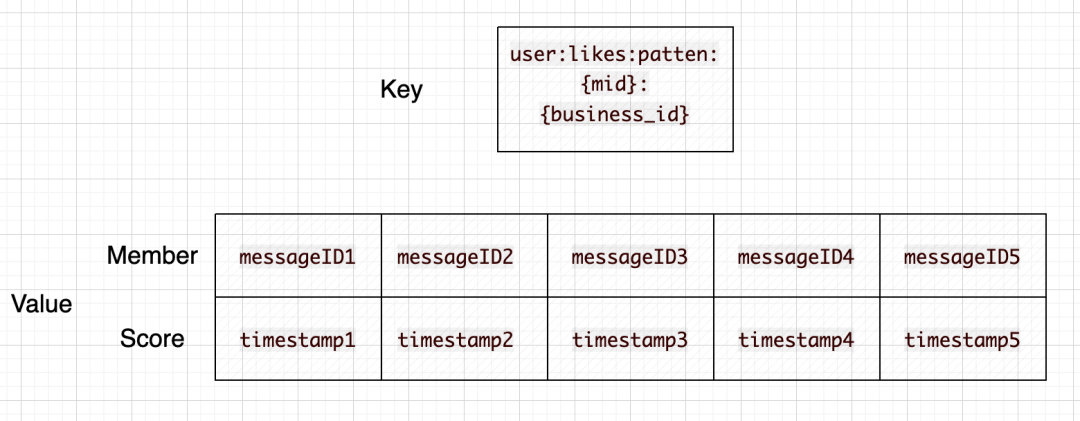
key-value = user:likes:patten:{mid}:{business_id} - member(messageID)-score(likeTimestamp)* 用mid与业务ID作为key,value则是一个ZSet,member为被点赞的实体ID,score为点赞的时间。当改业务下某用户有新的点赞操作的时候,被点赞的实体则会通过 zadd的方式把最新的点赞记录加入到该ZSet里面来为了维持用户点赞列表的长度(不至于无限扩张),需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录
第三层存储
LocalCache - 本地缓存
本地缓存的建立,目的是为了应对缓存热点问题
缓存热点是指大部分甚至所有的业务请求都命中同一份缓存数据。虽然缓存本身的性能比较高,但对于一些特别热点的数据,如果大部分甚至所有的请求都命中同一份缓存数据,则这份数据所在的缓存服务器的压力也会很大。
将热点数据缓存在客户端的本地内存中,并设置一个失效时间。对于每次读请求,首先检查该数据是否存在于本地缓存中,如果存在则直接返回,否则再去访问分布式缓存服务器。本地内存缓存彻底“解放”了缓存服务器,不会对其造成压力,但需要注意数据一致性问题
好了,到这里这篇文章的核心内容就已经介绍完了,剩下的基本都是容灾的内容,我简单给大家介绍一下:
1.在TiDB数据库的基础上,迁徙数据到B站技术团队自研的TaiShan KV数据库,一方面做容灾备份,另一方面未来用于替代TiDB。
2.**点赞服务层(thumbup-service)**采用两地机房互为灾备。机房1承载所有写流量与部分读流量,机房2承载部分读流量。当DB发生故障时,通过db-proxy(sidercar)的切换可以将读写流量切换至备份机房继续提供服务。Redis也同样有多机房集群互为灾备。通过异步任务消费TiDB的binLog维护两地缓存的一致性。(binLog,简单理解就是当tidb的数据发生变化时,会触发binLog,我们可以在触发的binLog事件中写入代码逻辑,本文中就是维护两地缓存一致性的逻辑)
读流量,机房2承载部分读流量。当DB发生故障时,通过db-proxy(sidercar)的切换可以将读写流量切换至备份机房继续提供服务。Redis也同样有多机房集群互为灾备。通过异步任务消费TiDB的binLog维护两地缓存的一致性。(binLog,简单理解就是当tidb的数据发生变化时,会触发binLog,我们可以在触发的binLog事件中写入代码逻辑,本文中就是维护两地缓存一致性的逻辑)