1.源IP地址和目的IP
计算机网络中的源地址和目的地址是用来标识网络中的不同主机的。
源地址是指发送数据包的主机的地址,而目的地址则是指接收数据包的主机的地址,在数据包传输过程中,每经过一个路中器感交换机,都会根据目的地址讲行转发,直到到达目的主机。
但是我们先来理解一下
目标主机中存在很多进程,网络通信实际是不同主机中的进程在进行通信,并非主机与主机直接通信
 我们如果仅仅使用
我们如果仅仅使用 IP 只能定位到目标主机,并且目标主机不是最终目的地,最终目的地是目标主机里的某个进程,数据包传到B主机的传输层的时候,上层的进程很多,就不知道该传给上层的哪个进程了。这个时候要想定位这个目标进程,需要依靠 端口号。
抛开网络其他知识,将信息从主机
A中的进程A发送至主机B中的 进程B,这不就是 进程间通信 吗?之前学习的 进程间通信 是通过 匿名管道、命名管道、共享内存 等方式实现,而如今的 进程间通信 则是通过 网络传输 的方式实现进程间通信的本质是让两个进程看到同一份资源,那么今天这个同一份资源就是网络。
2.端口号(Port)
2.1.什么是端口号
数据链路和IP中的地址,分别指的是MAC地址和IP地址。前者用来识别同一链路中不同的计算机,后者用来识别TCP/IP网络中互连的主机和路由器。
在传输层中也有这种类似于地址的概念,那就是端口号。端口号用来识别同一台计算机中进行通信的不同应用程序。因此,它也被称为程序地址。
传输层会解析这个端口号,然后将数据传向特定进程。

端口号由其使用的传输层协议决定。因此,不同的传输协议可以使用相同的端口号。例如,TCP与UDP使用同一个端口号,但使用目的各不相同。这是因为端口号上的处理是根据每个传输协议的不同而进行的。
数据到达IP层后,会先检查IP首部中的协议号,再传给相应协议的模块。如果是TCP则传给TCP模块、如果是UDP则传给UDP模块去做端口号的处理。即使是同一个端口号,由于传输协议是各自独立地进行处理,因此相互之间不会受到影响。
2.2.IP+端口号标识进程
两台主机进行网络通信,首先需要定位。
我们知道IP能标识一台主机,端口号Port能标识主机里特定进程,那么IP+Port就能标识唯一的一个进程!!!!
实际上两台计算机通信其实是通过IP地址、端口号、协议号进行通信识别
我们可以一步一步去推断
- 仅凭目标端口识别某一个通信是远远不够的。

如图所示,①和②的通信是在两台计算机上进行的。它们的目标端口号相同,都是80。例如打开两个Web浏览器,同时访问两个服务器上不同的页面,就会在这个浏览器跟服务器之间产生类似前面的两个通信。在这种情况下也必须严格区分这两个通信。因此可以根据源端口号加以区分。

上图中③跟①的目标端口号和源端口号完全相同,但是它们各自的源IP地址不同。此外,还有一种情况上图中并未列出,那就是IP地址和端口全都一样,只是协议号(表示上层是TCP或UDP的一种编号)不同。这种情况下,也会认为是两个不同的通信。
因此,TCP/IP或UDP/IP通信中通常采用5个信息来识别(这个信息可以在Unix或Windows系统中通过netstat -n 命令显示。) 一个通信。它们是“源IP地址”、“目标IP地址”、“协议号”、“源端口号”、“目标端口号”。只要其中某一项不同,则被认为是其他通信。
也就是说,必须包含下面这些东西
网络传输中的必备信息组 [目的IP 源 IP || 目的 Port 源 Port]
- 目的
IP:需要把信息发送到哪一台主机 - 源
IP:信息从哪台主机中发出 - 目的
Port:将信息交给哪一个进程 - 源
Port:信息从哪一个进程中发出
这个就是套接字socket啊
2.3.端口号和PID的区别和关系
1.端口号 用于标识进程,进程 PID 也是用于标识进程,为什么在网络中,不直接使用进程 PID 呢?
- 进程 PID 隶属于操作系统中的进程管理,如果在网络中使用 PID,会导致网络标准中被迫中引入进程管理相关概念(进程管理与网络强耦合)
- 进程管理 属于 OS 内部中的功能,OS 可以有很多标准,但网络标准只能有一套,在网络中直接使用 PID 无法确保网络标准的统一性
- 并不是所有的进程都需要进行网络通信,如果端口号、PID 都使用同一个解决方案,无疑会影响网络管理的效率
所以综上所述,网络中的 端口号 需要通过一种全新的方式实现,也就是一个 2 字节的整数 port,进程 A 运行后,可以给它绑定 端口号 N,在进行网络通信时,根据 端口号 N 来确定信息是交给进程 A 的
- 端口号与进程
PID并不是同一个概念进程
PID就好比你的身份证号,端口号 相当于学号,这两个信息都可以标识唯一的你,但对于学校来说,使用学号更方便进行管理
- 2.主机(操作系统)是如何根据 端口号 定位具体进程的?
这个实现起来比较简单,创建一张哈希表,维护 <端口号, 进程
PID> 之间的映射关系,当信息通过网络传输到目标主机时,操作系统可以根据其中的 [目的Port],直接定位到具体的进程PID,然后通过PID来对这个进程进行通信整个过程就是端口号->PID->进程
- 3.我们怎么知道我们要通信的那个进程的目标端口号?
这个端口号是公开的,所以一开始就能知道
- 4. 一个进程可以绑定多个 端口号 吗?一个 端口号 可以被多个进程绑定吗?
端口号 的作用是配合 IP 地址标识网络世界中进程的唯一性,如果一个进程绑定多个 端口号,依然可以保证唯一性(因为无论使用哪个 端口号,信息始终只会交给一个进程);但如果一个 端口号 被多个进程绑定了,在信息递达时,是无法分辨该信息的最终目的进程的,存在二义性
所以一个进程可以绑定多个端口号,一个 端口号 不允许被多个进程绑定,如果被绑定了,可以通过 端口号 顺藤摸瓜,找到占用该 端口号 的进程
如果某个端口号被使用了,其他进程再继续绑定是会报错的,提示 该端口已被占用
3.认识传输层协议——TCP/UDP
传输层是用户层下面的第一层,我们使用网络通信时调用的接口基本就是这层的
主流的传输层协议有两个:TCP 和 UDP
两个协议各有优缺点,可以采用不同的协议,实现截然不同的网络程序,关于 TCP 和 UDP 的详细信息将会放到后面的博客中详谈,先来看看简单这两种协议的特点
TCP 协议:传输控制协议
- 传输层协议
- 有连接
- 可靠传输
- 面向字节流
字节流就像水龙头,用户可以根据自己的需求获取水流量
UDP 协议:用户数据协议
- 传输层协议
- 无连接
- 不可靠传输
- 面向数据报
数据报则是相当于包裹,用户每次获取的都是一个或多个完整的包裹
关于 可靠性
- TCP 的可靠传输并不意味着它可以将数据百分百递达,而是说它在数据传输过程中,如果发生了传输失败的情况,它会通过自己独特的机制,重新发送数据,确保对端百分百能收到数据;
- 至于 UDP 就不一样,数据发出后,如果失败了,也不会进行重传,好在 UDP 面向数据报,并且没有很多复杂的机制,所以传输速度很快
总的来说TCP可靠性高,速度相对慢,UDP可靠性低,速度快。
总结起来就是:TCP 用于对数据传输要求较高的领域,比如金融交易、网页请求、文件传输等,至于 UDP 可以用于短视频、直播、即时通讯等对传输速度要求较高的领域
如果不知道该使用哪种协议,优先考虑 TCP,如果对传输速度又要求,可以选择 UDP
4.网络字节序
4.1.高低位和高低地址
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
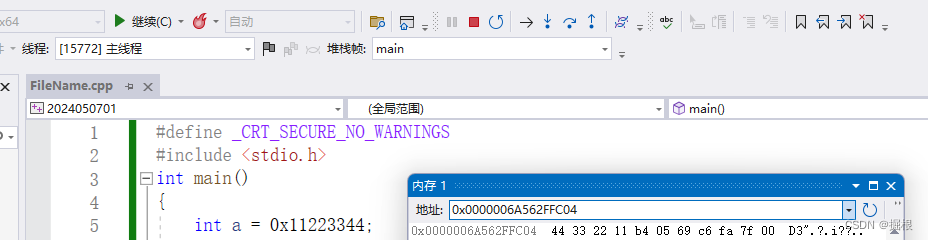 我们发现内存里存的怎么是44332211呢?
我们发现内存里存的怎么是44332211呢?
这个就和大小端有关系了
C语言中的大小端(Endianness)指的是字节顺序的不同方式,即如何将多字节的数据类型(如整数、浮点数)在内存中存储。
- 数字的高低位
先来了解数字的高低位
0x12345678 高位 低位越靠近1这边的位就叫高位,越靠近8那边的位叫低位
- 高低地址
什么是高地址,什么是低地址,举举例说明?
可以把主存看成一本空白的作业本,你现在要在笔记本上记录一些内容,他的页码排序是
第一页 : 0x0000001 第二页 : 0x0000002 … 最后一页: 0x0000092下面有两种使用情况
第一种:如果你选择
从前向后记录(用完第一页,用第二页,类推)这就是先使用低地址,后使用高地址.0x0000001 -> 0x0000002-> … -> 0x0000092业内有这样表述:动态内存分配时堆空间向高地址增长,说的就是这种情况.
这个向高地址增长就是先使用低地址,后使用高地址的意思.第二种:如果你选择
从后往前记录(先用笔记本的最后一页,用完后使用倒数第二页,类推) 这就是先使用高地址,后使用低地址0x0000092 -> … ->0x0000002 -> 0x0000001业内表述:
0xbfac 5000-0xbfad a000是栈空间,其中高地址的部分保存着进程的环境变量和命令行参数,低地址的部分保存函数栈帧,栈空间是向低地址增长的.这个向低地址增长就是先使用高地址,后使用低地址的意思.
这个
高地址与低地址容易与高位低位产生混淆.我们从小就知道,数字是从左往右读的,这符合人类的普遍阅读习惯。
比如十进制数 65535,数位从高到低依次是万,千,百,十,个。对十进制数而言,最左边是高位数位,最右边是低位数位。我们类比到16进制数
0x12345678,也从左往右来阅读这个数。那么,对十六进制数而言,最左边就是高位字节,最右边是低位字节。

4.2.大小端字序
首先,你可能需要对内存有一些基本的认识:
- 一个内存单元可以存储一个字节的内容,因此内存单元也常常被称为字节单元。
- 一个内存单元可以存储8个比特,即8个二进制数。但是,如果换算成16进制,一个内存单元仅能容纳2个16进制数。
如图所示,我们在画内存示意图的时候,我们用一个绿色矩形表示一个内存单元,每一个内存单元都有一个内存地址,方便计算机的处理器找到这块内存单元。
另外,我们也习惯于内存地址将低地址端放在下面,高地址端放在上面。
这个习惯,我猜测可能与古人建房子的习惯类似,所谓“万丈高楼平地起”,最先建的总是低层,然后再建高层。高层究竟建多高,这个总是不断发展和变化的,但是最底层总是从零开始,这个是相对稳定的。
还是以十六进制数 0x12345678 为例,当它以大端字节序存储在内存中时,低地址端 0x0000 存储该数的高位字节 0x12;高地址端 0x0003 存储的是该数的低位字节 0x78。

当 0x12345678 以小端字节序存储在内存中时,低地址端 0x0000 存储该数的低位字节 0x78;高地址端 0x0003 存储的是该数的高位字节 0x12。

4.3.从网络传输看待字节序
在网络出现之前,使用大端或小端存储都没有问题,网络出现之后,就需要考虑使用同一种存储方案了,因为网络通信时,两台主机存储方案可能不同,会出现无法解读对方数据的问题。
所以在TCP/IP协议规定了在网络上必须采用网络字节顺序,也就是大端模式。
- 对于char型数据只占一个字节,无所谓大端和小端。
- 而对于非char类型数据,必须在数据发送到网络上之前将其转换成大端模式。
接收网络数据时按符合接受主机的环境接收。
简而言之,网络字节序是大端字节序。
发送数据时,将 主机字节序 转化为 网络字节序,接收到数据后,再转回 主机字节序 就好了,完美解决不同机器中的大小端差异,可以用下面这批库函数进行转换,在发送/接收时,调用库函数进行转换即可
#include <arpa/inet.h>
// 主机字节序转网络字节序
uint32_t htonl(uint32_t hostlong); // l 表示32位长整数
uint32_t htons(uint32_t hostshort); // s 表示16位短整数
// 网络字节序转主机字节序
uint32_t ntohl(uint32_t netlong); // l 表示32位长整数
uint32_t ntohs(uint32_t netshort); // s 表示16位短整数
我们通常编写和阅读的电脑文件中,总是习惯于从上到下,从左到右。此时低地址在左边或者在上边,高地址在右边或者下边。

十进制数 40190 等于十六进制数 0x9cfe,十进制数 5222 等于十六进制数 0x1466。
我们聚焦抓包的内容的第 4 行,即起始地址为 0x0040,最后一个地址为 0x004f。
0x9cfe的高位字节0x9c保存在低地址端0x0045,低位字节是0xfe保存在高地址端0x0046。0x1466的高位字节0x14保存在低地址端0x0047,低位字节是0x66保存在高地址端0x0048。