文章目录
- 1、简介
- 2、数据集
- 3、构建词典
- 4、构建数据集对象
- 5、构建网络模型
- 6、构建训练函数
- 6.1、多分类交叉熵损失函数🔺
- 6.2、Adam🔺
- 6.3、代码
- 7、构建预测函数
- 8、word_to_index和index_to_word
- 8.1、word_to_index
- 8.2、index_to_word
- 8.3、使用场景
- 9、DataLoader()的参数
- 10、标准深度学习模型训练流程⭐
- 11、案例的完整代码
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、简介
本文目标:掌握文本生成模型构建流程
文本生成任务是一种常见的自然语言处理任务,输入一个开始词能够预测出后面的词序列。
本案例将会使用循环神经网络来实现周杰伦歌词生成预测任务。
2、数据集
免费下载:
链接:https://pan.baidu.com/s/14SJWD_ChjiX0UJ8ncL6a4w?pwd=1234
提取码:1234

数据集如下:
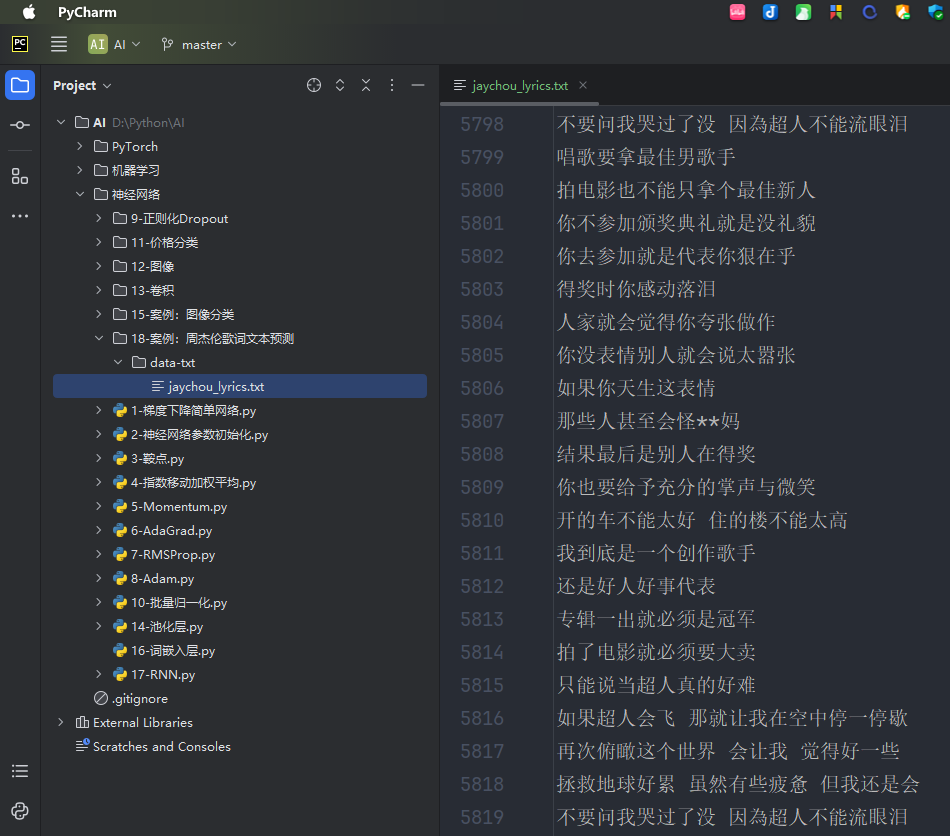
数据集共有 5819 行。
下面是讲解原理之后,用代码依次构建,文末会有完整代码文本。
3、构建词典
我们在进行自然语言处理任务之前,首要做的就是就是构建词表。
所谓的词表就是将 语料进行分词,然后给每一个词分配一个唯一的编号,便于我们送入词嵌入层。
最终,我们的词典主要包含了:
- word_to_index:存储了词到编号的映射
- index_to_word:存储了编号到词的映射
(下文讲解
word_to_index和index_to_word的区别和用处)
一般构建词表的流程如下:
- 语料清洗,去除不相关的内容
- 对语料进行分词
- 构建词表
接下来,我们对周杰伦歌词的语料数据按照上面的步骤构建词表。
代码如下:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/7 16:34
# 构建词典
import re # 导入正则表达式模块,用于文本清洗和处理
import jieba # 导入jieba库,用于中文分词
# 构建词汇表
def build_vocab():
file_name = '../data-txt/jaychou_lyrics.txt'
# TODO 1.清洗文本
# 初始化一个列表,用于存储清洗后的句子
clean_sentences = []
for line in open(file_name, 'r', encoding='utf-8'): # 打开歌词文件,逐行读取,指定编码为UTF-8
line = line.replace('〖韩语Rap译文〗', '') # 去除特定的文本标记
# TODO 使用正则表达式去除无效字符
# 去除 除了 中文、英文、数字、部分标点符号外 的其他字符
line = re.sub(r'[^\u4e00-\u9fa5 a-zA-Z0-9!?,]', '', line)
# 连续空格替换成1个
line = re.sub(r'[ ]{2,}', '', line) # 替换连续的空格为单个空格
# 去除两侧空格、换行
line = line.strip() # 去除行首和行尾的空白字符和换行符
if len(line) <= 1: # 如果行的长度小于等于1,则跳过该行
continue
# 去除重复行
if line not in clean_sentences: # 如果行不在clean_sentences中,则添加
clean_sentences.append(line) # 将清洗后的行添加到clean_sentences列表中
# TODO 2. 语料分词
# TODO 初始化两个列表: index_to_word用于存储词汇表, all_sentences用于存储所有分词后的句子
index_to_word, all_sentences = [], []
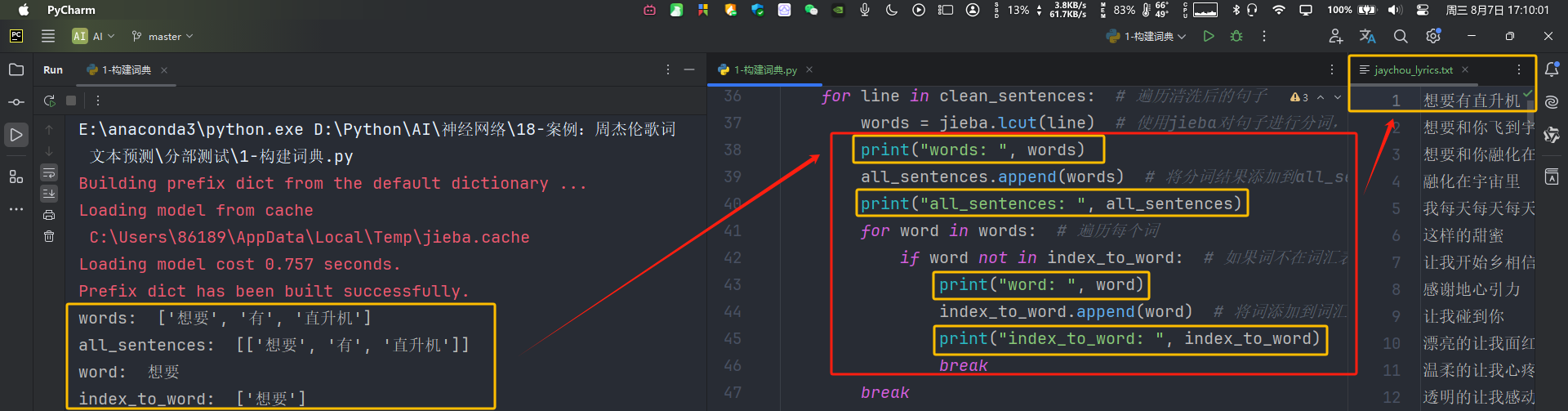
for line in clean_sentences: # 遍历清洗后的句子
words = jieba.lcut(line) # 使用jieba对句子进行分词,返回词汇列表
# print("words: ", words)
all_sentences.append(words) # 将分词结果添加到all_sentences列表中
# print("all_sentences: ", all_sentences)
for word in words: # 遍历每个词
if word not in index_to_word: # 如果词不在词汇表中
# print("word: ", word)
index_to_word.append(word) # 将词添加到词汇表中
# print("index_to_word: ", index_to_word)
# 词到索引映射
word_to_index = {word: idx for idx, word in enumerate(index_to_word)} # 创建词到索引的映射字典
# print("word_to_index_start: ", word_to_index)
# 词的数量
word_count = len(index_to_word) # 计算词汇表中词的数量
# 句子索引表示
corpus_idx = [] # 初始化一个列表,用于存储整个语料的索引表示
for sentence in all_sentences: # 遍历每个分词后的句子
temp = [] # 初始化一个临时列表,用于存储句子的索引
for word in sentence: # 遍历句子中的每个词
temp.append(word_to_index[word]) # 将词转换为索引并添加到临时列表中
# 在每行歌词之间添加空格隔开
temp.append(word_to_index[' ']) # 在每个句子末尾添加空格的索引作为分隔符
# print("temp: ", temp)
# TODO extend()是逐个添加, 区别于extend()
corpus_idx.extend(temp) # 将句子的索引表示添加到corpus_idx列表中
# print("corpus_idx: ", corpus_idx)
# TODO 返回构建的词汇表、索引映射、词数、语料索引
return index_to_word, word_to_index, word_count, corpus_idx
if __name__ == '__main__': # 主程序入口
index_to_word, word_to_index, word_count, corpus_idx = build_vocab() # 调用build_vocab函数,构建词汇表和索引
print("词汇表的大小: ", word_count) # 打印词汇表的大小
print("语料的索引表示: ", corpus_idx[:10]) # 打印语料的索引表示
print("索引到词的映射: ", index_to_word[:10]) # 打印词汇表
print("词到索引的映射: ", word_to_index) # 打印词到索引的映射
输出如下:
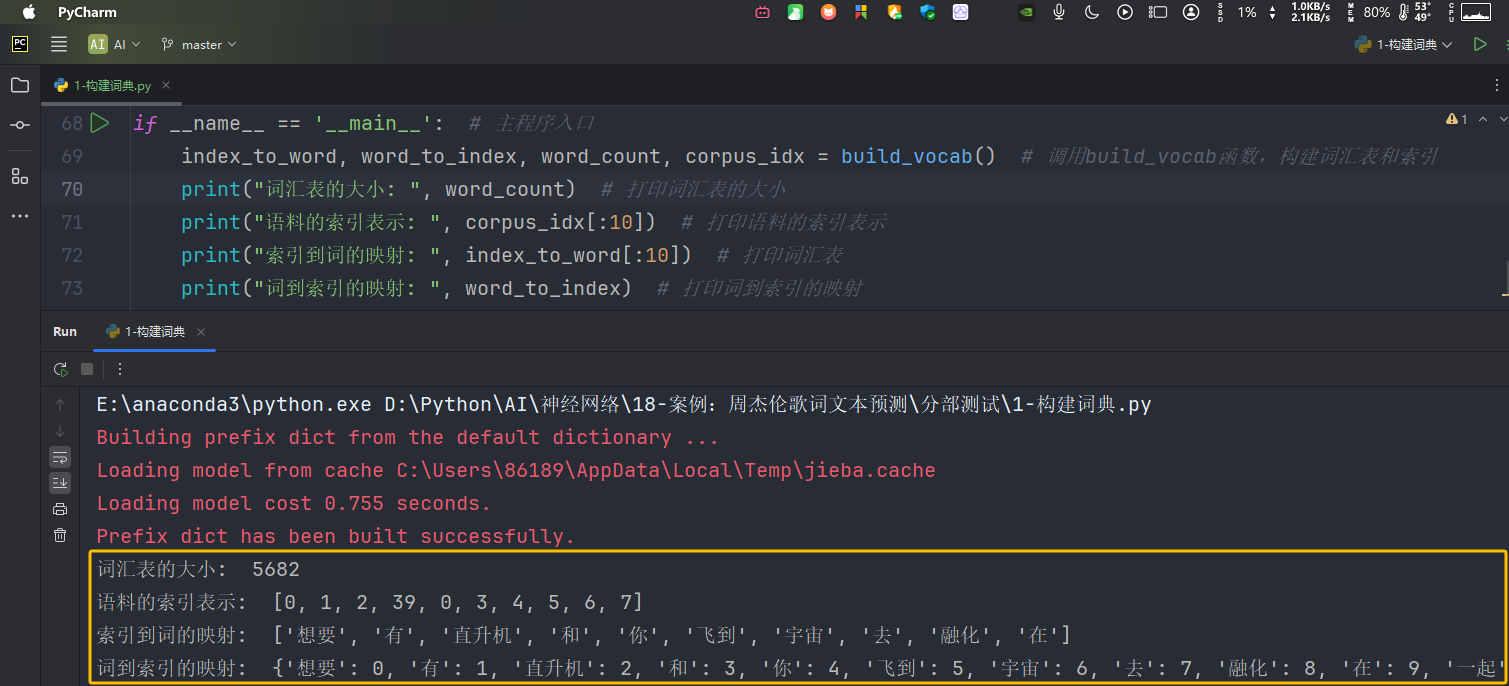
一些代码概念的理解:
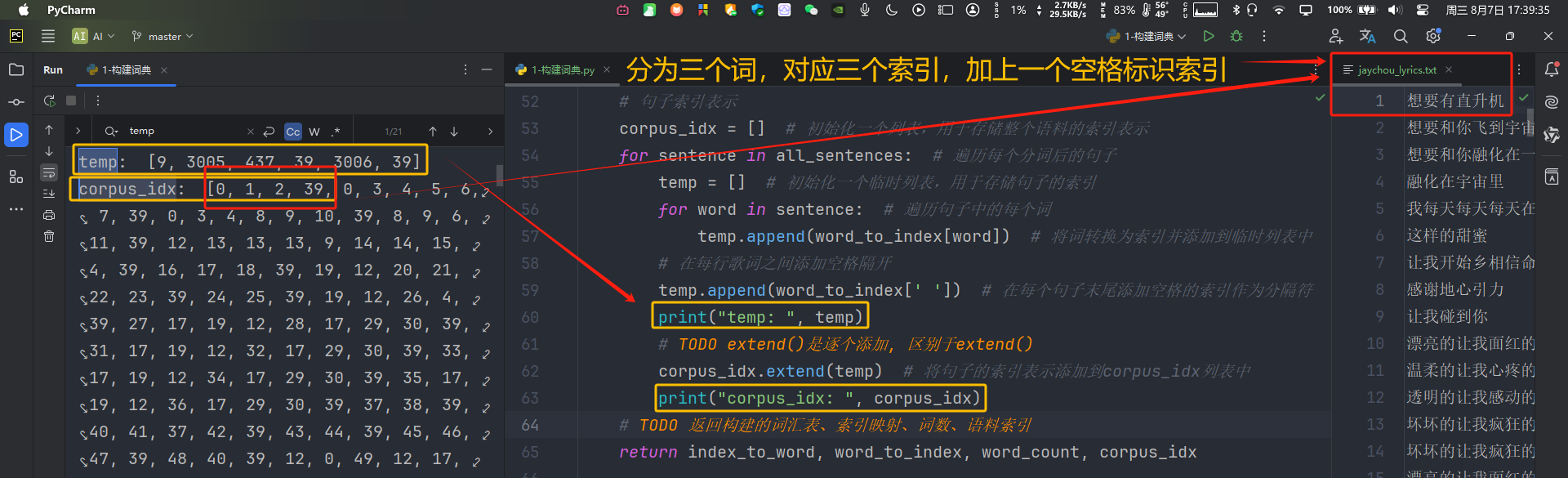
对代码具体实现流程的总结如下:
- 清洗文本:去除特定文本、无效字符、连续空格转为单个空格、去掉换行符和两侧空格
- 分词:构建"
index_to_word"->“索引 : 词”;“all_sentences”->分词后的句子- 对每行进行分词,加如
all_sentences列表 - 对每个词索引映射:
index_to_word
- 对每行进行分词,加如
- 构建"
word_to_index"->“词 : 索引” - 定义
corpus_idx语料集合,存储所有分词后的文本索引(通过添加末尾空格[单个]索引,来辨认哪些索引对应某一句歌词) - 返回
index_to_word,word_to_index,word_count,corpus_idx。
4、构建数据集对象
我们在训练的时候,为了便于读取语料,并送入网络,所以我们会构建一个 Dataset 对象,并使用该对象构建 DataLoader 对象,然后对 DataLoader 对象进行迭代可以获取语料,并将其送入网络
类对象:
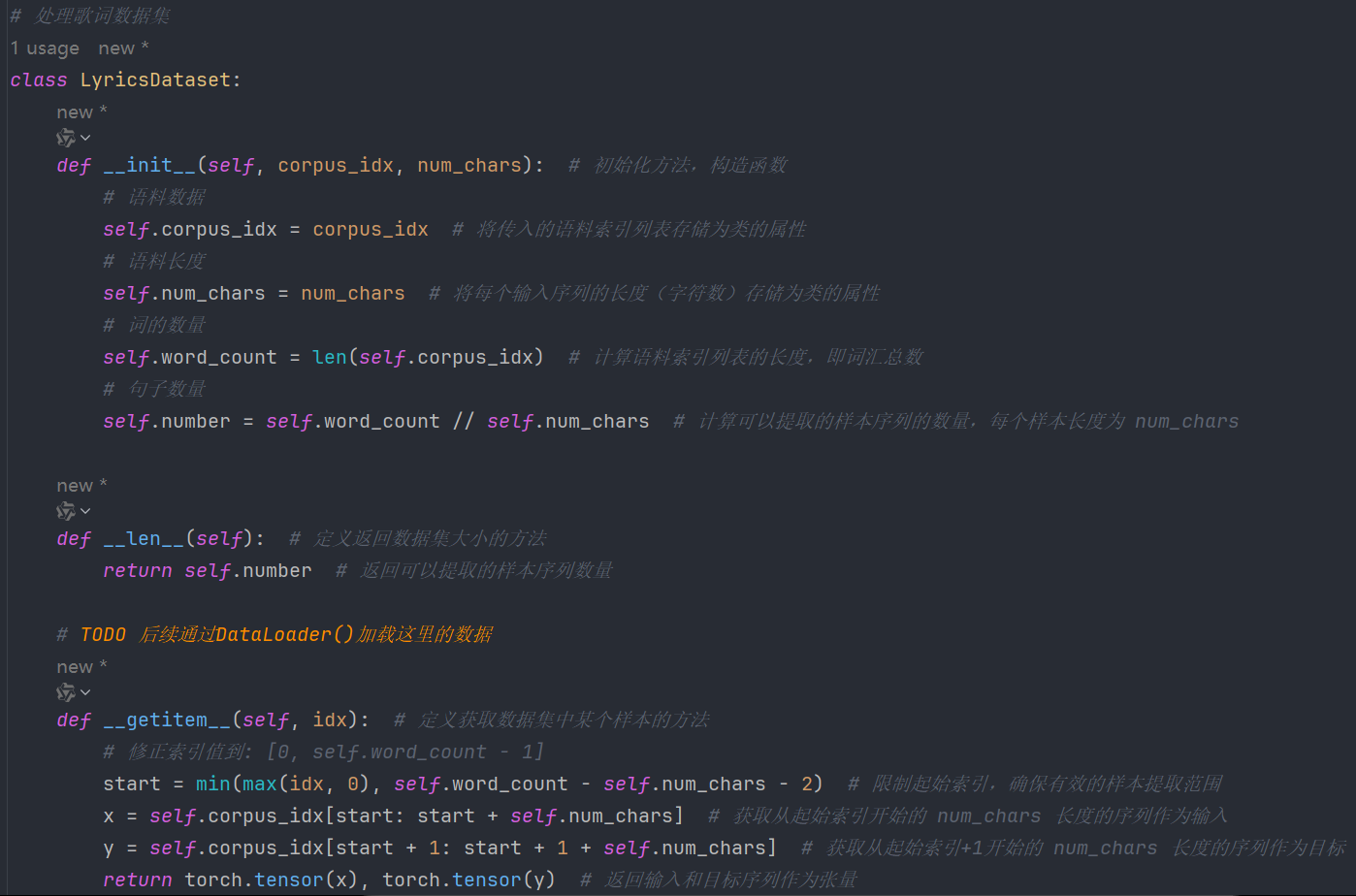
使用:
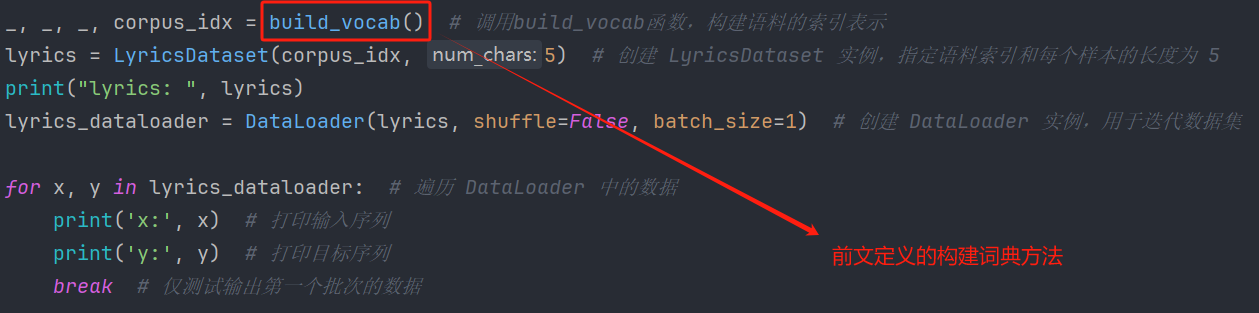
输出:
E:\anaconda3\python.exe D:\Python\AI\神经网络\18-案例:周杰伦歌词文本预测\分部测试\2-构建数据集.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\86189\AppData\Local\Temp\jieba.cache
Loading model cost 0.796 seconds.
Prefix dict has been built successfully.
lyrics: <__main__.LyricsDataset object at 0x000001ACA162BE90>
x: tensor([[ 0, 1, 2, 39, 0]])
y: tensor([[ 1, 2, 39, 0, 3]])
Process finished with exit code 0
对代码具体实现流程的总结如下:
- 先由前文的buid_vocab()获得对应的单个词典
- 把该词典的语料集和想要划分每批次的数值,输入到类中
- 初始化各数值(init)
- 构造样本,构建开始索引。有x输入值和y输出值,转换为tensor张量,为下文的模型构造和训练做准备
5、构建网络模型
我们用于实现歌词生成的网络模型,主要包含了三个层:
- 词嵌入层: 用于将语料转换为词向量
- 循环网络层:提取句子语义
- 全连接层:输出对词典中每个词的预测概率
我们前面学习了 Dropout 层,它具有正则化作用,所以在我们的网络层中,我们会对词嵌入层、循环网络层的输出结果进行 Dropout 计算。
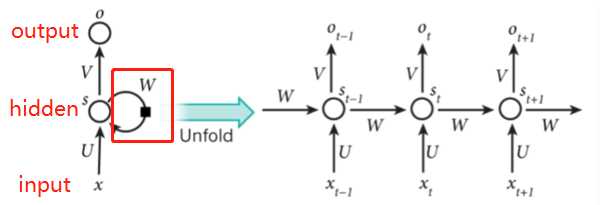
代码:
# 定义一个文本生成模型类,继承自 nn.Module
class TextGenerator(nn.Module):
# 初始化方法,构造函数
def __init__(self, vocab_size):
print("vocab_size: ", vocab_size)
# 调用父类(nn.Module)的构造函数
super(TextGenerator, self).__init__()
# TODO 定义新变量ebd、rnn、out
# 初始化词嵌入层,将词汇表中的每个词映射到一个128维的向量
self.ebd = nn.Embedding(vocab_size, 128)
# 初始化循环神经网络层,输入和输出都是128维,层数为1
self.rnn = nn.RNN(128, 128, 1)
# 初始化线性输出层,将RNN的输出映射到词汇表的大小
# TODO 输出是需要转为词汇, 所以vocab_size多大, 输出就是多大的
self.out = nn.Linear(128, vocab_size)
# 定义前向传播方法
def forward(self, inputs, hidden):
# 将输入的词索引转换为嵌入向量,输出维度为 (1, 5, 128)
embed = self.ebd(inputs)
# 对嵌入向量进行dropout正则化,防止过拟合,概率为0.2
embed = F.dropout(embed, p=0.2)
# 将嵌入向量的维度从 (1, 5, 128) 转置为 (5, 1, 128) 以匹配RNN的输入要求
# TODO 这里会调用rnn.py的forward()方法
output, hidden = self.rnn(embed.transpose(0, 1), hidden) # embed.transpose(0, 1)调整张量维度
# 对RNN的输出进行dropout正则化,防止过拟合,概率为0.2
embed = F.dropout(output, p=0.2)
# 将RNN的输出维度从 (5, 1, 128) 压缩为 (5, 128)
# 然后通过线性层将其转换为词汇表大小的向量 (5, vocab_size)
output = self.out(output.squeeze())
# 返回输出和隐藏状态
return output, hidden
# 初始化隐藏状态的方法
def init_hidden(self):
# 返回一个全零的隐藏状态张量,维度为 (1, 1, 128)
return torch.zeros(1, 1, 128)
测试:
输出:
E:\anaconda3\python.exe D:\Python\AI\神经网络\18-案例:周杰伦歌词文本预测\分部测试\3-构建网络模型.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\86189\AppData\Local\Temp\jieba.cache
Loading model cost 0.764 seconds.
Prefix dict has been built successfully.
词汇表的大小: 5682
语料的索引表示: [0, 1, 2, 39, 0, 3, 4, 5, 6, 7]
索引到词的映射: ['想要', '有', '直升机', '和', '你', '飞到', '宇宙', '去', '融化', '在']
vocab_size: 5682
torch.Size([1, 5])
Process finished with exit code 0
RNN输入要求:

rnn.forward():
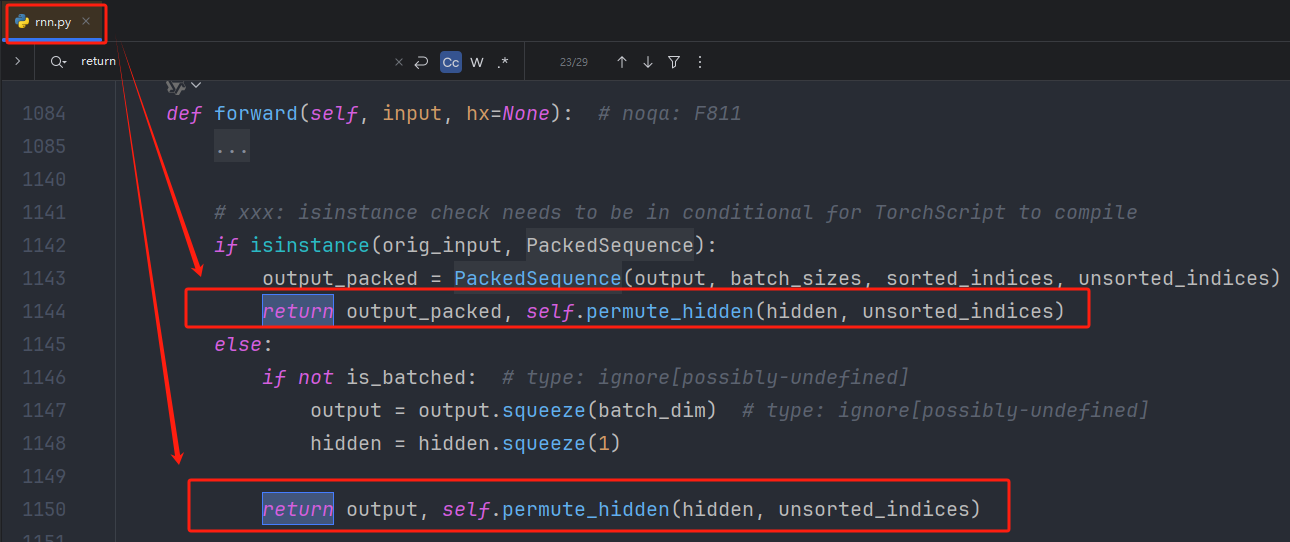
返回结果是一个时间步输出隐藏状态,一个输出最终的隐藏状态
6、构建训练函数
前面的准备工作完成之后,就可以编写训练函数了
训练函数主要负责编写 数据迭代、送入网络、计算损失、反向传播、更新参数,其流程基本较为固定。
由于我们要实现文本生成,文本生成本质上,输入一串文本,预测下一个文本,也属于分类问题,可以看成是一个 多分类问题。
所以,我们使用 多分类交叉熵损失函数;
优化方法这里选择学习率、梯度自适应的 Adam 算法作为我们的优化方法。
训练完成之后,我们使用 torch.save 方法将模型持久化存储。
6.1、多分类交叉熵损失函数🔺
多分类交叉熵损失函数(Multiclass Cross-Entropy Loss)是深度学习中常用的损失函数,特别适用于多分类任务。
它计算模型 输出的概率分布与真实类别分布之间的差异。
对于一个具有
N
N
N 个样本和
C
C
C 类别的多分类问题,多分类交叉熵损失函数定义为:
Loss
=
−
1
N
∑
i
=
1
N
∑
c
=
1
C
y
i
,
c
log
(
y
^
i
,
c
)
\text{Loss} = -\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{C} y_{i,c} \log(\hat{y}_{i,c})
Loss=−N1∑i=1N∑c=1Cyi,clog(y^i,c)
其中:
- N N N 是样本数量。
- C C C 是类别数量。
- y i , c y_{i,c} yi,c 是样本 i i i 的真实标签,如果样本 i i i 的真实类别是 c c c,则 y i , c = 1 y_{i,c} = 1 yi,c=1,否则 y i , c = 0 y_{i,c} = 0 yi,c=0。
- y ^ i , c \hat{y}_{i,c} y^i,c 是模型对样本 i i i 的类别 c c c 的预测概率。
实现:
- 在PyTorch中,多分类交叉熵损失函数可以使用
torch.nn.CrossEntropyLoss类来实现。 - 该类结合了
nn.LogSoftmax和nn.NLLLoss,因此无需手动应用 softmax 函数到模型的输出。 CrossEntropyLoss会自动计算 softmax,然后再计算交叉熵损失。
6.2、Adam🔺
Adam简介:
Adam(Adaptive Moment Estimation)优化器是 深度学习中常用的一种优化算法。
它结合了AdaGrad和RMSProp的优点,既能够适应稀疏梯度,又能够处理非平稳目标。
Adam通过计算梯度的一阶和二阶矩估计来动态调整每个参数的学习率。
一阶动量是梯度的指数加权移动平均。它可以看作是梯度的平均值,表示了梯度的方向和大小。
二阶动量是梯度平方的指数加权移动平均。它可以看作是梯度的方差,表示了梯度的变化范围。
Adam 优化器的关键特点:
- 自适应学习率:每个参数都有独立的学习率,可以根据一阶和二阶梯度估计动态调整。
- 计算效率:相对于简单的随机梯度下降 (SGD),
Adam计算效率高,存储需求小。- 适用于大规模数据集:在处理大规模数据集和高维参数空间时表现优越。
- 默认超参数效果好:在许多情况下,Adam的默认超参数配置能取得很不错的效果。
Adam通过以下公式来更新参数:
- 计算梯度的移动平均:
- m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
- v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
- 其中, g t g_t gt 是当前时间步的梯度, m t m_t mt 和 v t v_t vt 分别是梯度的一阶和二阶矩的移动平均, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是衰减率(通常取 β 1 = 0.9 \beta_1 = 0.9 β1=0.9 和 β 2 = 0.999 \beta_2 = 0.999 β2=0.999)。
- 偏差修正:
- m t ^ = m t 1 − β 1 t \hat{m_t} = \frac{m_t}{1 - \beta_1^t} mt^=1−β1tmt
- v t ^ = v t 1 − β 2 t \hat{v_t} = \frac{v_t}{1 - \beta_2^t} vt^=1−β2tvt
- 参数更新:
- θ t = θ t − 1 − α m t ^ v t ^ + ϵ \theta_t = \theta_{t-1} - \alpha \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} θt=θt−1−αvt^+ϵmt^
- 其中, α \alpha α 是学习率, ϵ \epsilon ϵ 是一个小常数(防止分母为零,通常取 1 0 − 8 10^{-8} 10−8)。
6.3、代码
定义训练函数:
def train(epoch, train_log):
# 构建词典,返回索引到词,词到索引,词汇数量,和语料索引列表
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
# 创建歌词数据集实例,每个输入序列的长度为 32
lyrics = LyricsDataset(corpus_idx, 32)
# 初始化文本生成模型,词汇表大小为 word_count
model = TextGenerator(word_count)
# TODO 正式进入这一阶段代码
# 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义 Adam 优化器,学习率为 1e-3
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 打开日志文件用于写入
file = open(train_log, 'w')
# 开始训练循环
for epoch_idx in range(epoch):
# 数据加载器,打乱顺序,每次取 1 个样本
lyrics_dataloader = DataLoader(lyrics, shuffle=True, batch_size=1)
# 记录训练开始时间
start = time.time()
# 重置迭代次数
iter_num = 0
# 重置训练损失
total_loss = 0.0
# 遍历数据加载器中的数据
for x, y in lyrics_dataloader:
# 初始化隐藏状态
hidden = model.init_hidden()
# 前向传播计算输出和隐藏状态
output, hidden = model(x, hidden)
# 计算损失,y.squeeze() 去掉维度大小为1的维度
# TODO 计算模型输出与实际目标之间的损失(误差)
loss = criterion(output, y.squeeze())
# 梯度清零
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 迭代次数加1
iter_num += 1
# 累加损失
total_loss += loss.item()
# 构建本次迭代的日志信息
message = 'epoch %3s loss: %.5f time %.2f' % \
(epoch_idx + 1, # 当前训练轮数
total_loss / iter_num, # 平均损失
time.time() - start) # 本轮训练时间
# 打印日志信息
print(message)
# 写入日志文件
file.write(message + '\n')
# 关闭日志文件
file.close()
# 保存模型参数到文件
torch.save(model.state_dict(), '../model/lyrics_model_%d.bin' % epoch)
if __name__ == '__main__':
train(epoch=1, train_log='lyrics_training.log') # 设置训练轮数为 200, 训练日志文件名为 lyrics_training.log
7、构建预测函数
到了最后一步,从磁盘加载训练好的模型,进行预测
预测函数,输入第一个指定的词,我们将该词输入网路,预测出下一个词,再将预测的出的词再次送入网络,预测出下一个词,以此类推,直到预测出我们指定长度的内容。
# 构建预测函数
def predict(start_word, sentence_length, model_path):
# 构建词典,返回索引到词,词到索引,词汇数量
index_to_word, word_to_index, word_count, _ = build_vocab()
# 构建文本生成模型实例,词汇表大小为 word_count
model = TextGenerator(vocab_size=word_count)
# 加载训练好的模型参数
model.load_state_dict(torch.load(model_path))
# 初始化隐藏状态
hidden = model.init_hidden()
try:
# 将起始词转换为词索引
word_idx = word_to_index[start_word]
except:
print("该词不在词典中, 请重新输入")
return
# 用于存储生成的句子(词索引序列)
generate_sentence = [word_idx]
# 生成长度为 sentence_length 的句子
for _ in range(sentence_length):
# 前向传播,获取模型输出和隐藏状态
output, hidden = model(torch.tensor([[word_idx]]), hidden)
# print("output: ", output)
# 获取输出中概率最大的词的索引
word_idx = torch.argmax(output).item()
# 将该词索引添加到生成的句子中
generate_sentence.append(word_idx)
# 将生成的词索引序列转换为实际词并打印
for idx in generate_sentence:
print(index_to_word[idx], end='')
print()
if __name__ == '__main__':
predict('分手', 15, '../model/lyrics_model_20.bin')
程序运行结果:
E:\anaconda3\python.exe D:\Python\AI\神经网络\18-案例:周杰伦歌词文本预测\分部测试\5-构建预测函数.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\86189\AppData\Local\Temp\jieba.cache
Loading model cost 0.873 seconds.
Prefix dict has been built successfully.
vocab_size: 5682
分手的话像语言暴力 我已无能为力再提起 决定中断熟悉
Process finished with exit code 0
关于 torch.argmax(output):
这行代码用于从模型的输出中选择
概率最大的词的索引,并将其作为下一个输入词的索引
那么在训练过程中,又是什么时候存储概率的呢?
在训练过程中,模型的输出并不是直接存储概率,而是生成一个未归一化的得分(logits)向量。、通过交叉熵损失函数计算时,这些未归一化的得分会被隐式地转换为概率。
1. 模型输出(Logits)
模型的最后一层通常是一个线性层,它的输出是一个包含词汇表中每个词的未归一化得分(logits)的向量。这些得分代表了每个词在当前上下文中的相对可能性。
2. 交叉熵损失函数:
在训练过程中,使用 nn.CrossEntropyLoss 作为损失函数。nn.CrossEntropyLoss 函数结合了 nn.LogSoftmax 和 nn.NLLLoss,其计算步骤如下:
- Logits to Probabilities:
nn.LogSoftmax将未归一化的得分(logits)转换为对数概率。
- Negative Log-Likelihood Loss:
nn.NLLLoss使用对数概率计算负对数似然损失。
3. 训练过程:
在训练过程中,模型的输出是未归一化的得分,这些得分在计算交叉熵损失时被隐式地转换为概率。训练完成后,模型在预测时会输出这些得分,通过 torch.argmax 找到得分最高的词索引,这个词就是模型预测的下一个词。
8、word_to_index和index_to_word
在自然语言处理(NLP)任务中,文本数据需要转换为数值格式,以便机器学习模型可以处理和理解。 word_to_index 和 index_to_word 是两种常用的数据结构,用于将词汇表中的单词和索引相互映射。这种映射在文本预处理中非常重要,下面是对这两者的详细解释和作用。
8.1、word_to_index
word_to_index 是一个字典,它将每个单词映射到一个唯一的整数索引。这种映射的主要作用有:
- 文本向量化:
- 目的:将文本转换为数字形式,便于输入机器学习模型。
- 实现:每个单词用其对应的整数索引表示,形成数值向量。
- 词汇表管理:
- 作用:在训练模型时,我们需要知道输入数据中有哪些单词。
- 方便查询:通过索引,我们可以快速查找单词在词汇表中的位置。
- 简化计算:
- 优势:数字表示更易于机器处理,比处理字符串更高效。
8.2、index_to_word
index_to_word 是一个字典,它将每个整数索引映射回对应的单词。这种映射的主要作用有:
- 结果解码:
- 目的:在预测阶段,将模型输出的索引转换回可读的文本。
- 模型解释:
- 优势:帮助理解和分析模型的输出结果,尤其是在生成文本时。
- 调试和可视化:
- 作用:便于在训练和调试过程中,查看数值向量对应的实际单词,帮助检查和调整模型性能。
8.3、使用场景
- 构建词汇表:在处理文本数据时,首先需要通过所有文本构建一个词汇表,并使用
word_to_index和index_to_word映射来管理词汇和索引的关系。 - 预处理文本:在将文本数据输入模型前,使用
word_to_index将文本转换为数值形式。 - 解码预测:在生成模型(如文本生成或机器翻译)中,使用
index_to_word将模型的输出转化为可读的文本。
9、DataLoader()的参数
DataLoader 是 PyTorch 中的一个核心类,用于加载数据集并提供迭代器接口来批量访问数据。
它在处理大规模数据集时尤其有用,因为它可以自动处理批量化、打乱顺序、并行加载等任务。
下面是 DataLoader 的一些常用参数及其作用的详细解释:
DataLoader 常用参数:
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None,
generator=None,
prefetch_factor=2,
persistent_workers=False
)
dataset
- 类型:
Dataset类的实例 - 说明:指定数据集,
DataLoader从中读取数据。数据集需要实现__len__和__getitem__方法。
batch_size
- 类型:
int - 默认值:
1 - 说明:每个批次的数据样本数量。
DataLoader会按指定的batch_size从数据集中提取数据。
shuffle
- 类型:
bool - 默认值:
False - 说明:如果为
True,每个epoch在提取数据时会将数据集打乱顺序。打乱顺序有助于打破数据中的顺序依赖,提高模型的泛化能力。
sampler
- 类型:
Sampler类的实例 - 说明:定义了从数据集中抽样的策略。如果设置了
sampler,则shuffle必须为False。
batch_sampler
- 类型:
Sampler类的实例 - 说明:与
sampler类似,但返回的是一个批次的索引,而不是单个索引。与batch_size、shuffle、sampler互斥。
num_workers
- 类型:
int - 默认值:
0 - 说明:用于数据加载的子进程数量。设置为
0时,数据将在主进程中加载。增加此参数的值可以加快数据加载速度,尤其是在IO密集型数据集上
collate_fn
- 类型:
Callable - 说明:用于将一个批次的数据合并为一个单一的张量。如果需要对每个批次的数据进行特殊处理,可以定义自己的
collate_fn
pin_memory
- 类型:
bool - 默认值:
False - 说明:如果设置为
True,DataLoader将会在返回之前,将张量复制到CUDA固定内存中,提高GPU数据加载速度
drop_last
- 类型:
bool - 默认值:
False - 说明:如果为
True,DataLoader会丢弃数据集中无法组成完整批次的最后几个样本。这在确保批次大小一致时很有用
timeout
- 类型:
float - 默认值:
0 - 说明:设置
DataLoader在获取一个批次的数据时的超时时间。超过这个时间将会报错
worker_init_fn
- 类型:
Callable - 说明:每个子进程启动时,会调用这个函数进行初始化。可以用于设置每个工作进程的随机种子
multiprocessing_context
- 类型:
multiprocessing模块的上下文 - 说明:指定使用的多进程上下文,例如
'spawn'、'fork'。在不同平台上,多进程的默认行为可能不同
generator
- 类型:
torch.Generator - 说明:控制
DataLoader随机数生成的状态。可以通过设置随机种子,确保数据加载的一致性和可重复性
prefetch_factor
- 类型:
int - 默认值:
2 - 说明:每个工作进程应预取的样本批次数。仅当
num_workers > 0时使用
persistent_workers
- 类型:
bool - 默认值:
False - 说明:如果设置为
True,则数据加载器将在整个epoch内保持其工作进程的运行状态,而不会在每个epoch后关闭它们
10、标准深度学习模型训练流程⭐
- 数据准备:
- 数据加载:从文件或其他数据源加载数据。
- 数据预处理:清洗数据,分词,构建词汇表,将数据转换为适合输入模型的格式。
- 数据集和数据加载器:将预处理后的数据封装成数据集,并使用数据加载器批量加载数据。
- 模型构建:
- 模型定义:定义模型的架构,包括输入层、隐藏层、输出层等。
- 初始化模型:创建模型实例,设置超参数(如词汇表大小、嵌入维度、隐藏层维度等)。
- 损失函数和优化器:
- 损失函数:选择适合任务的损失函数,如交叉熵损失用于分类问题。
- 优化器:选择优化算法,如 Adam、SGD,并设置学习率等超参数。
- 训练设置:
- 训练轮数:设置训练的轮数(epoch)。
- 批量大小:设置每次训练的批量大小(batch size)。
- 训练循环:
- 外层循环(epoch):遍历每一轮训练。
- 数据加载:通过数据加载器批量加载数据。
- 重置指标:如总损失、迭代次数。
- 内层循环(batch):遍历每个批次数据。
- 初始化隐藏状态:为每个批次数据初始化隐藏状态(对于 RNN 类模型)。
- 前向传播:将输入数据通过模型,计算输出。
- 计算损失:使用损失函数计算模型输出与目标值之间的误差。
- 反向传播:计算梯度,进行梯度清零,执行反向传播。
- 更新参数:通过优化器更新模型参数。
- 记录指标:累加损失、更新迭代次数等。
- 记录日志:每轮结束后,计算平均损失和训练时间,打印并记录日志信息。
- 外层循环(epoch):遍历每一轮训练。
- 保存模型:
- 模型保存:训练结束后,保存模型的参数到文件,以便后续使用。
11、案例的完整代码
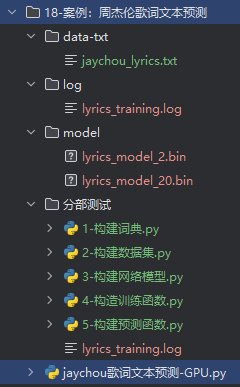
下面奉上本次案例的完整代码。
目录结构如下(gitee地址:https://gitee.com/xzl-it/artificial-intelligence):
完整代码(含注释):
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/8 1:14
import re # 导入正则表达式模块,用于文本清洗和处理
import time
import jieba # 导入jieba库,用于中文分词
import torch # 导入 PyTorch 库,用于深度学习
import torch.nn as nn # 从 PyTorch 中导入神经网络模块
import torch.nn.functional as F # 从 PyTorch 中导入功能模块,用于实现一些常见的神经网络操作
import torch.optim as optim # 导入 PyTorch 的优化器模块
from torch.utils.data import DataLoader # 从 PyTorch 中导入 DataLoader 类,用于批量数据加载
# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device: ", device)
def build_vocab():
file_name = 'data-txt/jaychou_lyrics.txt'
# TODO 1.清洗文本
# 初始化一个列表,用于存储清洗后的句子
clean_sentences = []
for line in open(file_name, 'r', encoding='utf-8'): # 打开歌词文件,逐行读取,指定编码为UTF-8
line = line.replace('〖韩语Rap译文〗', '') # 去除特定的文本标记
# TODO 使用正则表达式去除无效字符
# 去除 除了 中文、英文、数字、部分标点符号外 的其他字符
line = re.sub(r'[^\u4e00-\u9fa5 a-zA-Z0-9!?,]', '', line)
# 连续空格替换成1个
line = re.sub(r'[ ]{2,}', '', line) # 替换连续的空格为单个空格
# 去除两侧空格、换行
line = line.strip() # 去除行首和行尾的空白字符和换行符
if len(line) <= 1: # 如果行的长度小于等于1,则跳过该行
continue
# 去除重复行
if line not in clean_sentences: # 如果行不在clean_sentences中,则添加
clean_sentences.append(line) # 将清洗后的行添加到clean_sentences列表中
# TODO 2. 语料分词
# TODO 初始化两个列表: index_to_word用于存储词汇表, all_sentences用于存储所有分词后的句子
index_to_word, all_sentences = [], []
for line in clean_sentences: # 遍历清洗后的句子
words = jieba.lcut(line) # 使用jieba对句子进行分词,返回词汇列表
# print("words: ", words)
all_sentences.append(words) # 将分词结果添加到all_sentences列表中
# print("all_sentences: ", all_sentences)
for word in words: # 遍历每个词
if word not in index_to_word: # 如果词不在词汇表中
# print("word: ", word)
index_to_word.append(word) # 将词添加到词汇表中
# print("index_to_word: ", index_to_word)
# 词到索引映射
word_to_index = {word: idx for idx, word in enumerate(index_to_word)} # 创建词到索引的映射字典
# print("word_to_index_start: ", word_to_index)
# 词的数量
word_count = len(index_to_word) # 计算词汇表中词的数量
# 句子索引表示
corpus_idx = [] # 初始化一个列表,用于存储整个语料的索引表示
for sentence in all_sentences: # 遍历每个分词后的句子
temp = [] # 初始化一个临时列表,用于存储句子的索引
for word in sentence: # 遍历句子中的每个词
temp.append(word_to_index[word]) # 将词转换为索引并添加到临时列表中
# 在每行歌词之间添加空格隔开
temp.append(word_to_index[' ']) # 在每个句子末尾添加空格的索引作为分隔符
# print("temp: ", temp)
# TODO extend()是逐个添加, 区别于extend()
corpus_idx.extend(temp) # 将句子的索引表示添加到corpus_idx列表中
# print("corpus_idx: ", corpus_idx)
# TODO 返回构建的词汇表、索引映射、词数、语料索引
return index_to_word, word_to_index, word_count, corpus_idx
# 处理歌词数据集
class LyricsDataset:
def __init__(self, corpus_idx, num_chars): # 初始化方法,构造函数
# 语料数据
self.corpus_idx = corpus_idx # 将传入的语料索引列表存储为类的属性
# 语料长度
self.num_chars = num_chars # 将每个输入序列的长度(字符数)存储为类的属性
# 词的数量
self.word_count = len(self.corpus_idx) # 计算语料索引列表的长度,即词汇总数
# 句子数量
self.number = self.word_count // self.num_chars # 计算可以提取的样本序列的数量,每个样本长度为 num_chars
def __len__(self): # 定义返回数据集大小的方法
return self.number # 返回可以提取的样本序列数量
# TODO 后续通过DataLoader()加载这里的数据
def __getitem__(self, idx): # 定义获取数据集中某个样本的方法
# 修正索引值到: [0, self.word_count - 1]
start = min(max(idx, 0), self.word_count - self.num_chars - 2) # 限制起始索引,确保有效的样本提取范围
x = self.corpus_idx[start: start + self.num_chars] # 获取从起始索引开始的 num_chars 长度的序列作为输入
y = self.corpus_idx[start + 1: start + 1 + self.num_chars] # 获取从起始索引+1开始的 num_chars 长度的序列作为目标
return torch.tensor(x), torch.tensor(y) # 返回输入和目标序列作为张量
# 定义一个文本生成模型类,继承自 nn.Module
class TextGenerator(nn.Module):
# 初始化方法,构造函数
def __init__(self, vocab_size):
print("vocab_size: ", vocab_size)
# 调用父类(nn.Module)的构造函数
super(TextGenerator, self).__init__()
# TODO 定义新变量ebd、rnn、out
# 初始化词嵌入层,将词汇表中的每个词映射到一个128维的向量
self.ebd = nn.Embedding(vocab_size, 128)
# 初始化循环神经网络层,输入和输出都是128维,层数为1
self.rnn = nn.RNN(128, 128, 1)
# 初始化线性输出层,将RNN的输出映射到词汇表的大小
# TODO 输出是需要转为词汇, 所以vocab_size多大, 输出就是多大的
self.out = nn.Linear(128, vocab_size)
# 定义前向传播方法
def forward(self, inputs, hidden):
# 将输入的词索引转换为嵌入向量,输出维度为 (1, 5, 128)
embed = self.ebd(inputs).to(device)
# 对嵌入向量进行dropout正则化,防止过拟合,概率为0.2
embed = F.dropout(embed, p=0.2)
# 将嵌入向量的维度从 (1, 5, 128) 转置为 (5, 1, 128) 以匹配RNN的输入要求
# TODO 这里会调用rnn.py的forward()方法
output, hidden = self.rnn(embed.transpose(0, 1), hidden) # embed.transpose(0, 1)调整张量维度
# 对RNN的输出进行dropout正则化,防止过拟合,概率为0.2
embed = F.dropout(output, p=0.2)
# 将RNN的输出维度从 (5, 1, 128) 压缩为 (5, 128)
# 然后通过线性层将其转换为词汇表大小的向量 (5, vocab_size)
output = self.out(output.squeeze())
# 返回输出和隐藏状态
return output, hidden
# 初始化隐藏状态的方法
def init_hidden(self):
# 返回一个全零的隐藏状态张量,维度为 (1, 1, 128)
return torch.zeros(1, 1, 128).to(device)
# 构建训练函数
def train(epoch, train_log):
# 构建词典,返回索引到词,词到索引,词汇数量,和语料索引列表
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
# 创建歌词数据集实例,每个输入序列的长度为 32
lyrics = LyricsDataset(corpus_idx, 32)
# 初始化文本生成模型,词汇表大小为 word_count
model = TextGenerator(word_count).to(device)
# TODO 正式进入这一阶段代码
# 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义 Adam 优化器,学习率为 1e-3
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 打开日志文件用于写入
file = open(train_log, 'w')
# 开始训练循环
for epoch_idx in range(epoch):
# 数据加载器,打乱顺序,每次取 1 个样本
lyrics_dataloader = DataLoader(lyrics, shuffle=True, batch_size=1)
# 记录训练开始时间
start = time.time()
# 重置迭代次数
iter_num = 0
# 重置训练损失
total_loss = 0.0
# 遍历数据加载器中的数据
for x, y in lyrics_dataloader:
# 初始化隐藏状态
hidden = model.init_hidden()
# 前向传播计算输出和隐藏状态
x, y = x.to(device), y.to(device)
output, hidden = model(x, hidden)
# 计算损失,y.squeeze() 去掉维度大小为1的维度
# TODO 计算模型输出与实际目标之间的损失(误差)
loss = criterion(output, y.squeeze())
# 梯度清零
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 迭代次数加1
iter_num += 1
# 累加损失
total_loss += loss.item()
# 构建本次迭代的日志信息
message = 'epoch %3s loss: %.5f time %.2f' % \
(epoch_idx + 1, # 当前训练轮数
total_loss / iter_num, # 平均损失
time.time() - start) # 本轮训练时间
# 打印日志信息
print(message)
# 写入日志文件
file.write(message + '\n')
# 关闭日志文件
file.close()
# 保存模型参数到文件
torch.save(model.state_dict(), 'model/lyrics_model_%d.bin' % epoch)
# 构建预测函数
def predict(start_word, sentence_length, model_path):
# 构建词典,返回索引到词,词到索引,词汇数量
index_to_word, word_to_index, word_count, _ = build_vocab()
# 构建文本生成模型实例,词汇表大小为 word_count
model = TextGenerator(vocab_size=word_count).to(device)
# 加载训练好的模型参数
model.load_state_dict(torch.load(model_path))
# 初始化隐藏状态
hidden = model.init_hidden()
try:
# 将起始词转换为词索引
word_idx = word_to_index[start_word]
except:
print("该词不在词典中, 请重新输入")
return
# 用于存储生成的句子(词索引序列)
generate_sentence = [word_idx]
# 生成长度为 sentence_length 的句子
for _ in range(sentence_length):
# 前向传播,获取模型输出和隐藏状态
output, hidden = model(torch.tensor([[word_idx]]).to(device), hidden)
# print("output: ", output)
# 获取输出中概率最大的词的索引
word_idx = torch.argmax(output).item()
# 将该词索引添加到生成的句子中
generate_sentence.append(word_idx)
# 将生成的词索引序列转换为实际词并打印
for idx in generate_sentence:
print(index_to_word[idx], end='')
print()
if __name__ == '__main__':
train(epoch=1, train_log='log/lyrics_training.log') # 设置训练轮数为 200, 训练日志文件名为 lyrics_training.log
predict('分手', 15, 'model/lyrics_model_1.bin')







![[开端]JAVA抽象类使用到redis观察着](https://i-blog.csdnimg.cn/direct/51f83f92399b4be58ceda36eda342d92.png)









