在LLM的推理和部署中,低精度量化对于性能的提升十分关键,本次分享将为大家介绍TRT-LLM中是如何基于CUTLASS 2.x来实现PerChannel/AWQ/SmoothQuant等量化方法在模型推理过程的计算。Slides来自BiliBili NVIDIA英伟达频道 上传的《TensorRT-LLM中的 Quantization GEMM(Ampere Mixed GEMM)的 CUTLASS 2.x 实现讲解》视频讲解。这里参考视频并更详细记录了每一页Slides的要点,通过这个视频了解下在TRT-LLM中如何使用CUTLASS 2.x来自定义Mixed GEMM算子。我将其作为CUDA-MODE的CUTLASS课程的前置学习内容。
总览&目录


课程目录如本章Slides所示,作者首先会介绍一下TRT-LLM推理的一些量化方法,然后通过没有代码的方式介绍了一下CUTLASS 2.x的整体流程以及如果我们想实现Mixed GEMM需要做什么修改,最后挑重点讲了一下为什么TRT-LLM里面关于Mixed GEMM在Ampere上要这么设计Weight Layout,主要是从性能以及CUTLASS 2.x本身的限制来考虑的。
TRT-LLM中的量化

在TensorRT中量化方法主要分为2类,一类是Mixed GEMM,也就是Activation和Weight的数据类型是不同的,例如AWQ,GPTQ,PerChannel。另外一类是Universal GEMM,例如SmoothQuant和FP8,它们的Activation和Weight的数据类型是相同的。
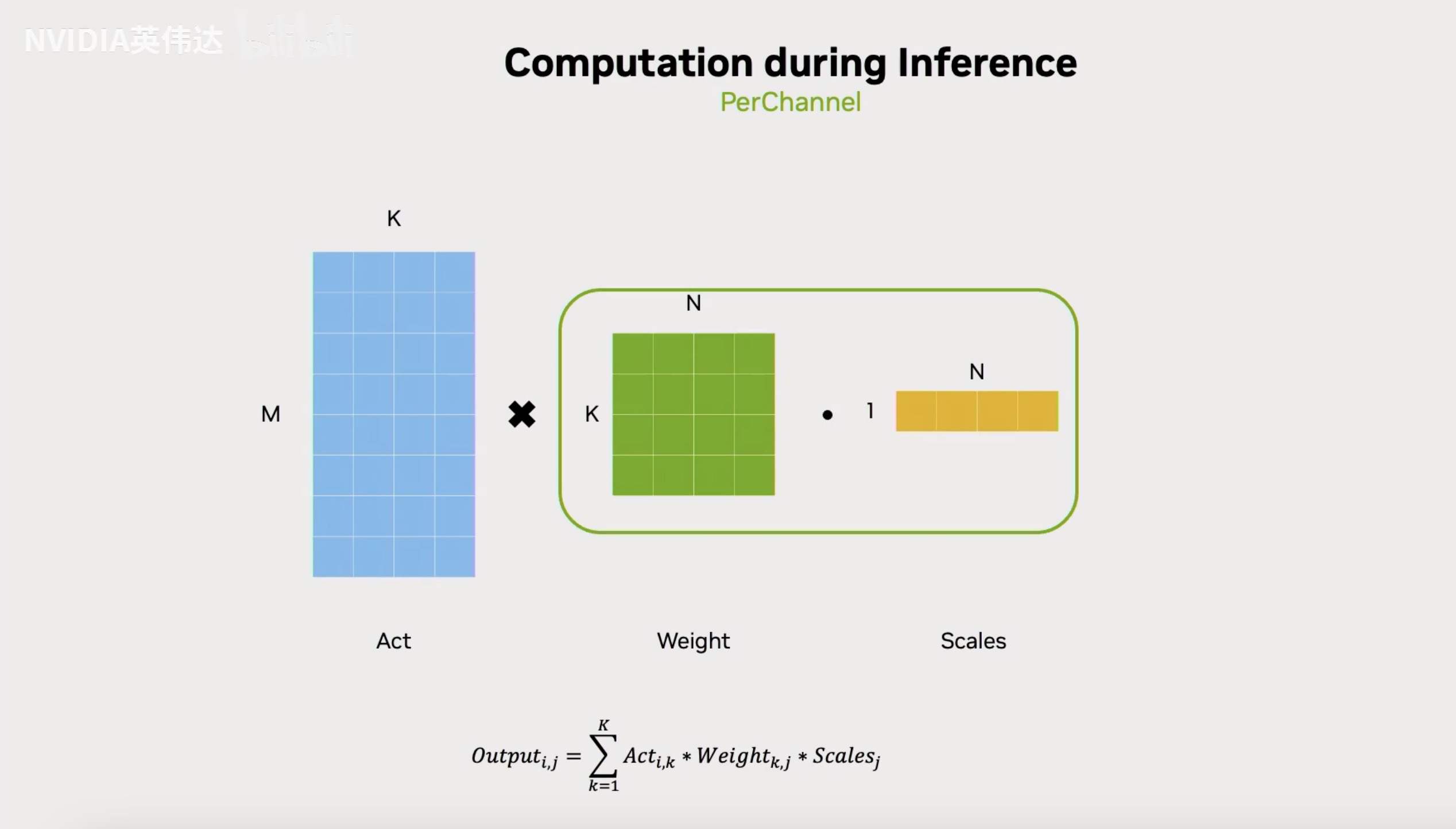
首先来看PerChannel在推理时的计算流程,可以看到它在推理时会先对Weight进行乘Scales的反量化,然后再执行一个正常的GEMM,流程比较简单。

对于AWQ/GPTQ来说,权重的量化不再是PerChannel的而是GroupWise的,也就是在K方向会有GS组Scales和Zeros,例如假设K/GS=128,那就是在K方向有128行的Weight共享一个Scales和Zeros。因此,它和PerChannel的差异就是需要在反量化的时候乘以Scales并加上Zeros。除此之外,AWQ本身需要在Activation计算之前乘以它自己的ActScale。
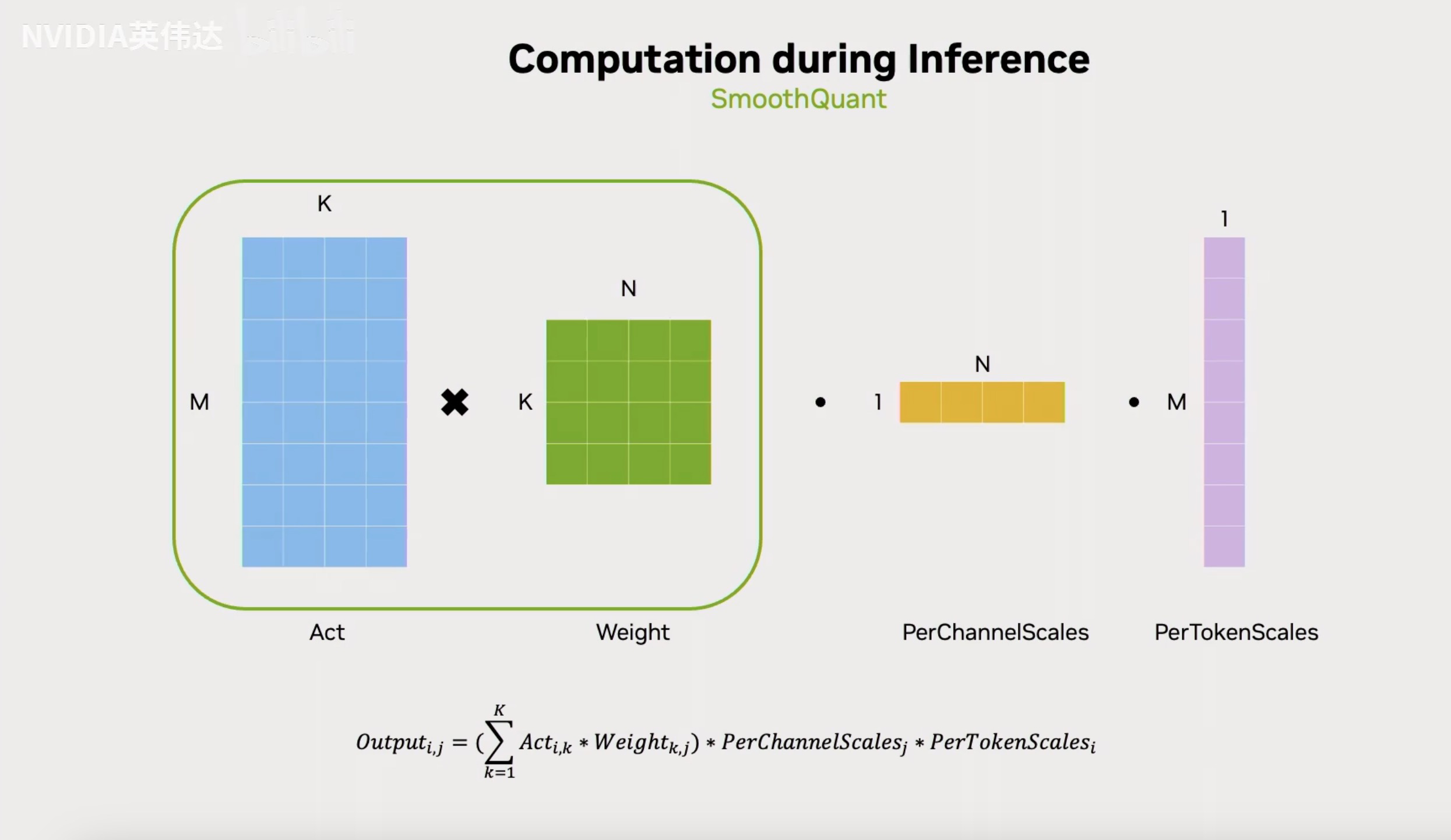
SmoothQuant不需要像之前的Mixed GEMM量化方法在计算GEMM之前做反量化,它的Scale可以在最后输出的时候apply。它前面的计算部分就是普通的Int8 GEMM,然后再输出的时候乘以PerChannelScales和PerTokenScales。

这张Slides讨论了使用CUTLASS如何实现不同的量化技术,并指出了它们与常规GEMM(通用矩阵乘法)的区别。主要内容包括:
- PerChannel/AWQ/GPTQ技术:
- A/B的数据类型不同:A/B数据所需的位宽不同,提出如何使用ld.global.b128来完成这个操作(在算GEMM的时候,我们首先要保证同一个线程或者warp从A,B矩阵加载的元素个数是相同的,因为它们要在K方向进行一个类似于向量点积的运算。假设我们都用128 bit的load,A矩阵假设16bit那么一下load进来了8个元素,但对于B矩阵如果你要load 8个元素,那么只能用ld.global.b32,也就是说无法使用效率更高的ld.global.b128指令。那么我们需要注意怎么调整Layout或者使用其它的方法尽量让B矩阵也用上效率更高位宽的load指令)
- 需要额外的输入张量:scales/zeros
- 需要更多的Shared Memory(我们从之前《CUTLASS 2.x & CUTLASS 3.x Intro 学习笔记》可以知道,我们也需要把scales和zeros也放到shared memory里面里用MultiStage让计算和访存Overlap起来)
- 如何处理分组(group-wise)情况?
- 在进行矩阵乘法(MMA)之前需要反量化
- 需要额外的CUDA核心fma指令(在算GEMM前需要把一个低比特的数据反量化回和Activation的数据类型一致)
- SmoothQuant技术:
- 需要额外的输入张量:PerTokenScales/PerChannelScales
- 在GEMM计算之后需要应用特定的缩放。(对于SmoothQuant只需要在Epilogue阶段把这两个Tensor load进来乘一下,然后写回global memory)。
CUTLASS 2.x kernel计算的整体流程

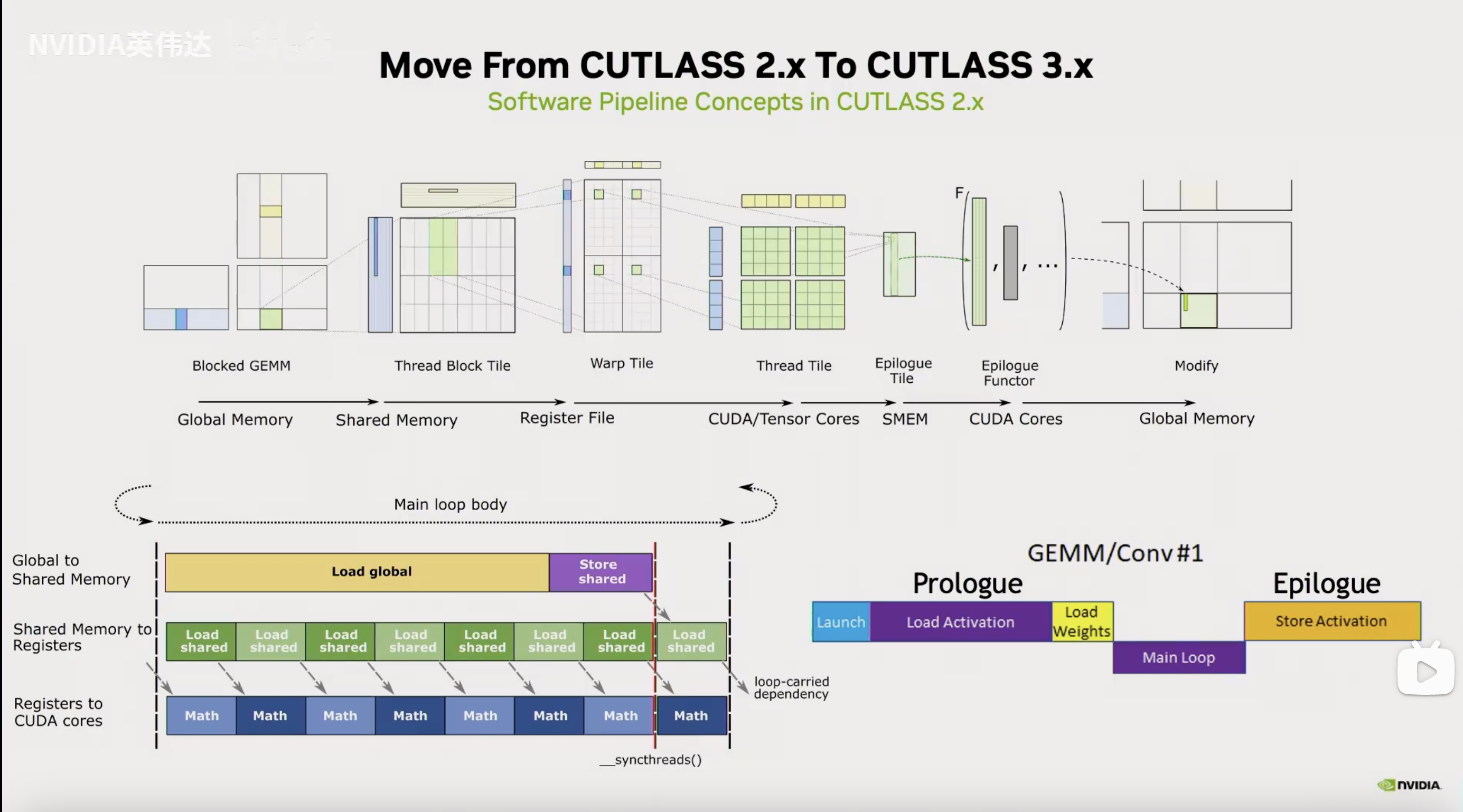
这张是CUTLASS GEMM的核心概念图。我们以C矩阵为视角,我们把矩阵C切成小块让每个BLOCK去认领一块做计算。接着要指定WARP去做计算,WARP会认领这个小块中的某一块,比如图中Thread Block Tile的绿色块。每个WARP有32个线程,每个线程又应该做哪一部分计算呢?Warp Tile这个图进一步放大细节,其中4个绿色块代表其中一个线程需要负责计算矩阵C的的部分。最后到线程级别,每个线程都有自己的寄存器去负责做自己的工作。再往右就是Epilogue,这个是很多人使用CUTLASS的第一步比如在GEMM后面做一个Activation后处理。最后把数据写回Global Memory完成整个运算过程。分块的关键参数以及Epilogue的操作类型由图上的using语句所指定。
这个图是CUTLASS的概念,但这里还画出了数据流动,数据需要从Global Memory逐级传递的。除了Tiling之外另外一个重要的概念是我们需要把数据尽可能的复用在高级缓存上,享受到更高的带宽,避免频繁的读取global memory的数据。因此,我们要把数据放在Shared Memory, 寄存器上,然后Tensor Core在寄存器上算完后写回Shared Memory(为了合并内存访问,用上更大位宽的load指令),对齐后再从Shared Memory以连续合并缓存的形式写回Global Memory。
在CUTLASS 2.x(类Ampere架构风格)中还提到,除了Tiling和复用内存层级,我们还希望使用软流水的方法把global memory读写latency和计算隐藏起来。也就是做当前计算的时候去读后续计算轮次需要的数据,这个过程可以流水起来。在进入稳定流水之前,也就是图中的Main loop body会有一个建立流水的过程。做了计算预取,当前计算的数据肯定在上几轮计算就取出来了,数据预取叫Prologue,GEMM的整个计算过程分为Prologue, Main Loop和Epilogue部分,使用Tensor Core的GEMM计算发生在Main Loop部分。

接下来展示了一下CUTLASS 2.x的流程,我们需要确定thread block怎么分,比如一个thread block它计算多大的一块数据,这块数据位于矩阵里面的哪个位置。首先需要设定一个CTAShapeM和CTAShapeN表示一个线程块需要计算的一个Tile的大小,但是如何确定哪一个thread block计算哪一个块呢?如果ThreadblockSwizzle这个参数为默认值1,那就不会对从thread block到实际计算块的映射有任何改变。那么它的计算就是沿着m的方向,第0个Block去算最左上角这个块,然后沿着m方向顺序排列。如果ThreadblockSwizzle这个参数为2,那么它的映射方式就会变成上面Slides最右边这张图的样子,这样做的好处是什么?我们来了解一下GPU上thread block和实际SM的对应关系,一般会连续发射一系列Block到一系列相邻的SM上,我们知道L2 Cache在所有的SM上都是共享的,所以我们希望尽可能的在不同的SM里面能够更高概率的命中L2 Cache。如果发射的是bid0/1/2/3这4个block,上面Slides中右图的行方向和列方向的Cache命中率会更高,但如果是按照中间图的方式发射,某个放的Cache命中率会很低。总结一下就是让相邻的SM尽可能的去访问一些在空间位置上相邻的数据来提升L2 Cache命中率。这就是BlockSwizzling(块交织)的作用。
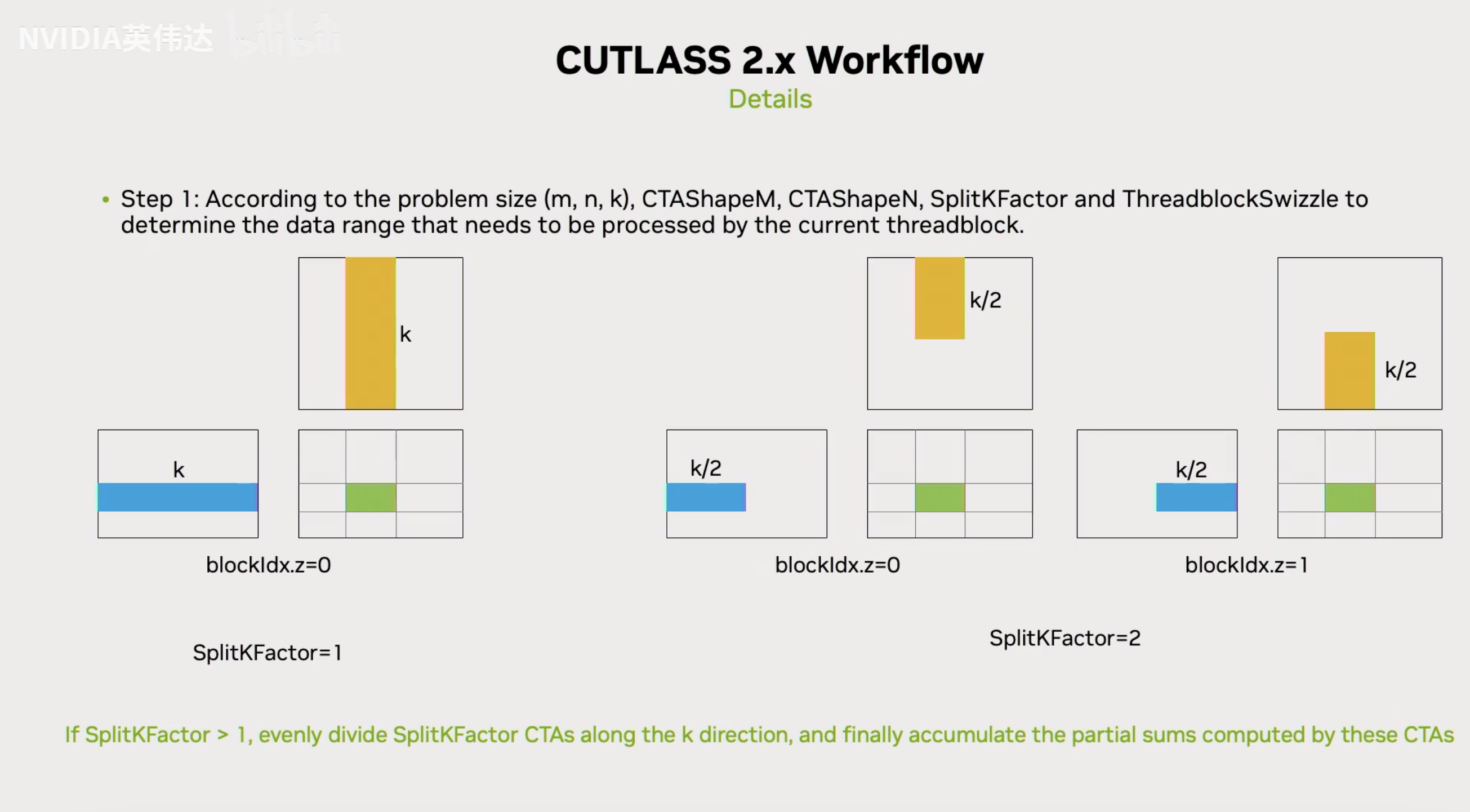
我们在实现CUTLASS GEMM kernel的时候有一个叫做SplitKFactor的参数,这个参数表示它会沿着GEMM的K方向进行切分。例如当SplitKFactor=2的时候就会把K纬度切分成2半,就会在K纬度上产生2个Block,当K维度上blockIdx.z=0的时候会处理前k/2的数据,当blockIdx.z=1的时候会处理后k/2的数据,算完之后,这两个Block就分别只持有最后输出数据的部分和(partial sum)。在Epilogue阶段结束之后会通过一系列的形式把这两个Block里面的数据累加回global memory。这样的形式在CUTLASS的实现中一般有两种,一种叫SplitK Serial,也就是一个串行的形式,会通过信号量或者锁的方式先保证第一个Block写到Global Memory里面去,再去控制第二个Block继续执行这部分,然后把它累加到对应的Global Memory位置。
另外一种形式叫SplitK Parallel,它就是把这两个Block分别写到不同的Buffer里面,然后再用一个reduce的kernel把这两个buffer累加起来。这一页Slides解释了K纬度上是怎么对Block进行划分的。
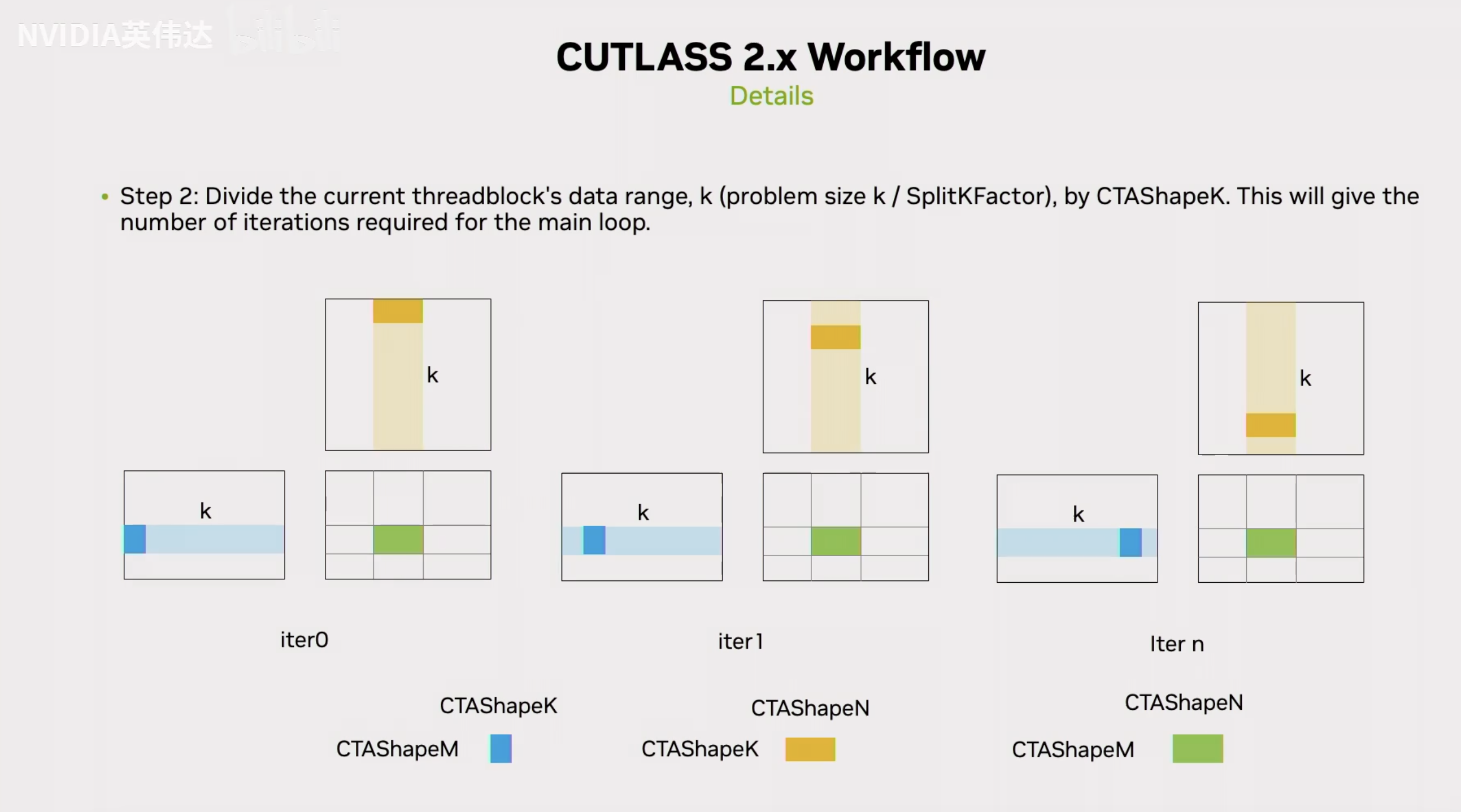
然后在确定了Block实际计算哪一个Tile之后,它需要确定在MainLoop中迭代的步数,也就是沿着K方向要迭代多少次。CTAShapeK就决定了在整个GEMM计算过程中沿着K方向循环,它的每一次迭代计算K方向上多少个元素,也就是计算CTAShapeK个元素。然后之前也提到了一个叫Stage Memory的东西,可能会每个Stage就对应了一个CTAShapeK,比如有5个Stage,它就会Prefetch 5个CTAShapeK的数据进来。也就是说它会提前把下面5次计算的数据全部prefetch到Shared Memory里面去。

然后我们需要进一步从BlockShape里面再把WarpShape划分出来,也就是一个Thread Block里面的Warp怎么去排布。这个排布方式在《CUTLASS 2.x & CUTLASS 3.x Intro 学习笔记》也简单介绍了,就是拿MNK三个方向的BlockShape去除上WarpShape就得到了MNK三个方向的warp数。MN方向上的Warp数很好理解,就像刚才的CTAShape一样对应到了最终输出的Thread Block里输出的某一块数据。例如BlockShapeM除以WarpShapeM等于2的话就意味着M方向分成2块,这个方向上的一个Warp计算其中一块输出,N方向也是类似。
但是K方向有一些区别,因为K方向是进行累加的一个方向,因此如果在K方向的WarpShape大于1的话,那么每个Warp只会计算当前这一轮迭代里面的累加和。比如这个BlockShapeK等于64,然后WarpShapeK等于32,K方向上的Warp分别只计算前32个累加和后32个累加和。这样在沿着K方向完成整个迭代之后,K方向的2个Warp就分别也持有一部分的最终的累加和。然后在Epilogue阶段会在把它们写回Shared Memory之后把K方向的两个Warp的数据累加回来。
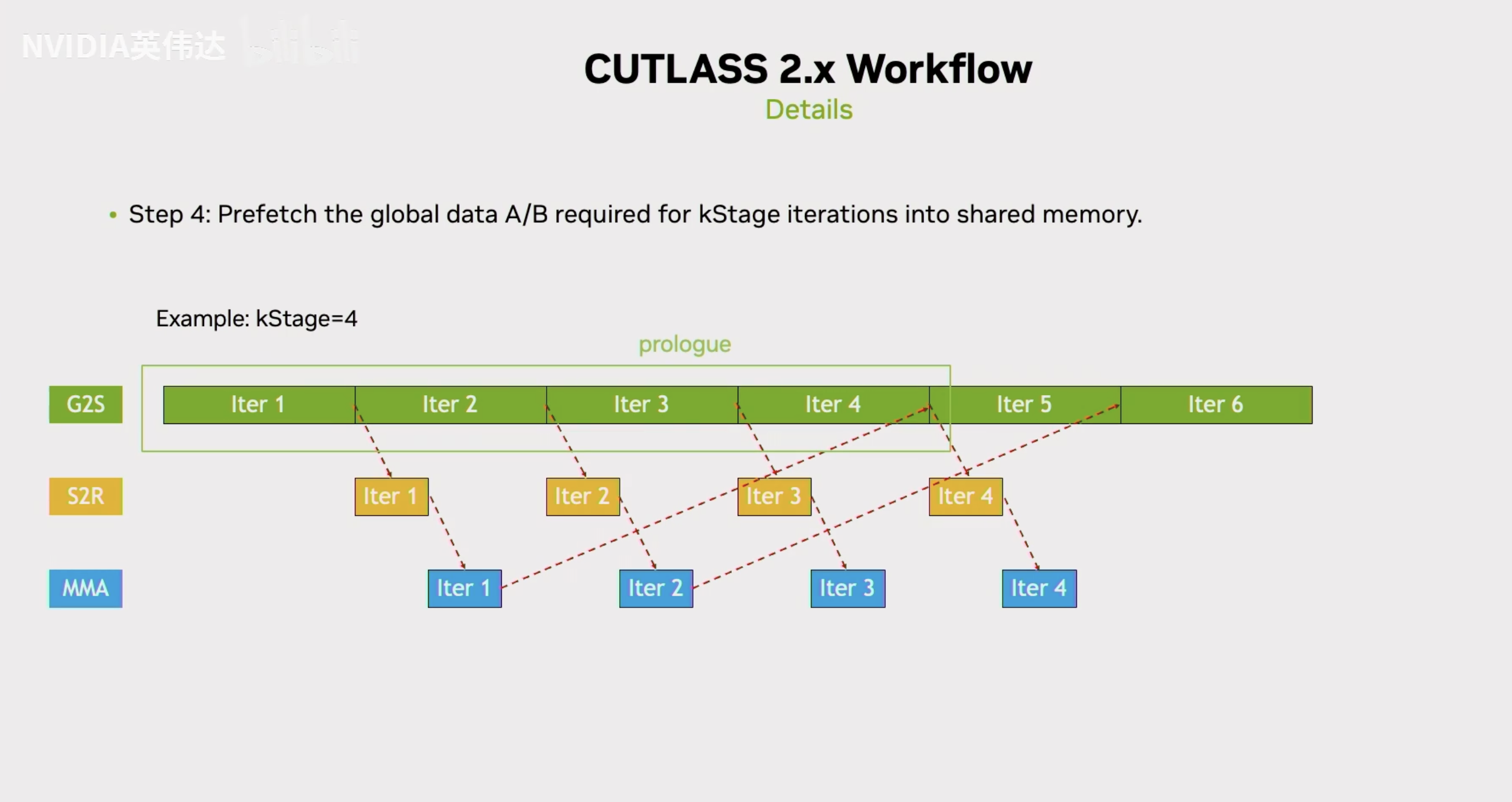
前面介绍到了从BlockShape到WarpShape的划分,这里再介绍一下CUTLASS里面的MultiStage是什么。MultiStage就是,首先一个Stage对应着K方向一次迭代的数据,例如Stage数为4的话,prologue就是会把4次迭代的数据给prefetch一下,这个prefetch一般是通过LDGSTS指令(CpAsync)来完成的。这是一个异步的指令,所以提交之后可以等待这个指令的完成。这个指令发射之后就可以开始MainLoop的计算,而MainLoop的计算会等到prologue阶段发射的4个stage里面的第一个stage的数据准备好。这段数据一旦准备好,就意味着这段数据已经从Global Memory拷贝到了Shared Memory,接着下来它就可以在Shared Memory里面把实际的数据load到寄存器里面,接着它就可以再用这段数据去计算Tensor Core指令。这段数据计算完成后就意味着第一个iteration的计算实际都完成了,那它就可以去发射第5个stage的对应的从global到shared memory拷贝的异步指令。这个指令发射完后,就开始真正的第二次迭代。第二次迭代时,它的第二轮的拷贝指令已经在prologue阶段发射了,它只需要等待这个指令完成,完成后就可以拿这段数据去load寄存器然后计算并发射下一条从global到shared memory拷贝的异步指令。
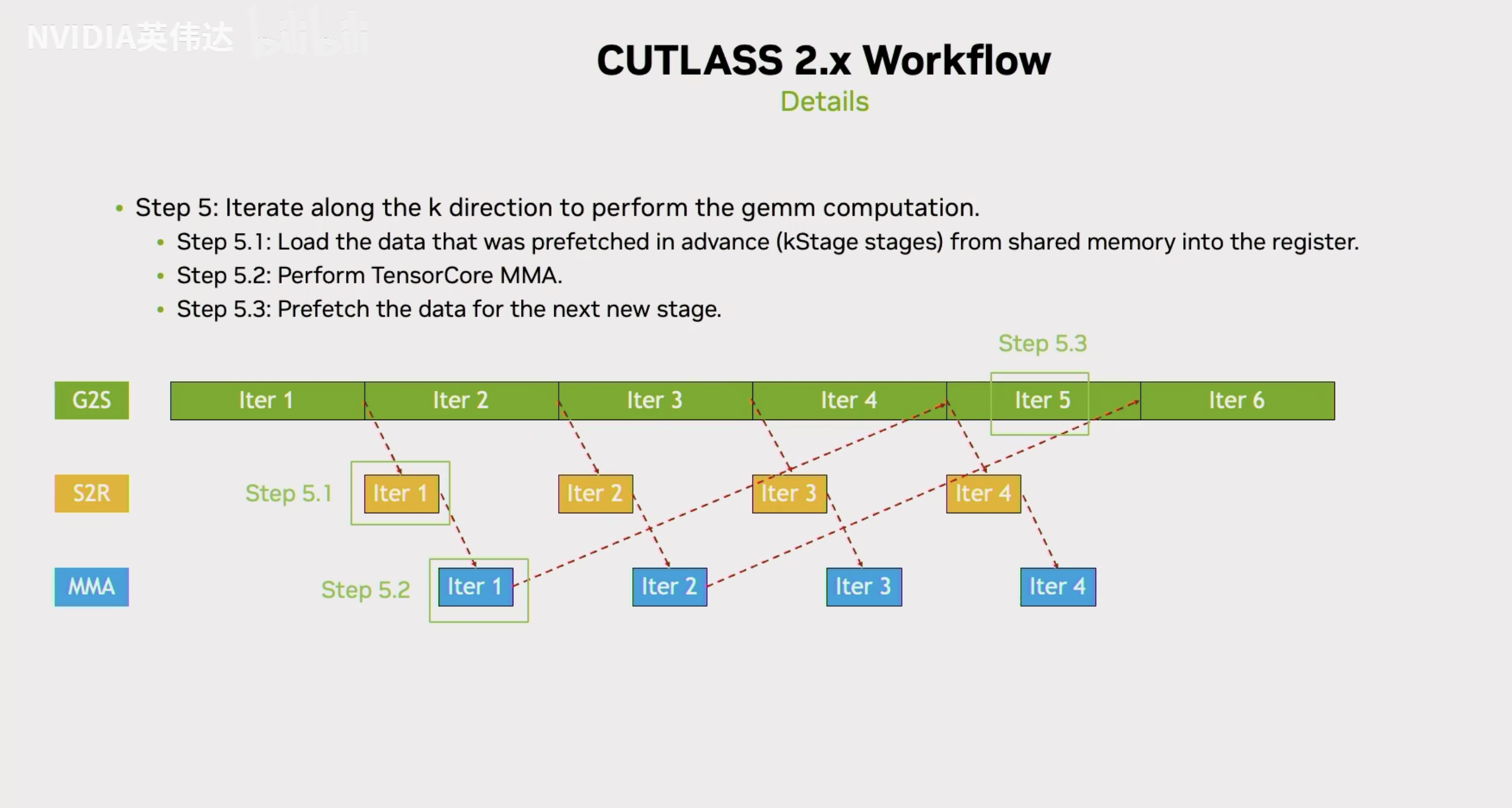
总结一下就是CUTLASS GEMM在MainLoop阶段沿着整个K方向迭代,首先会把prefetch的数据load到寄存器里面,然后进行Tensor Core的计算,做完计算之后再prefetch下一个stage的数据。这就是整个MainLoop的流程。
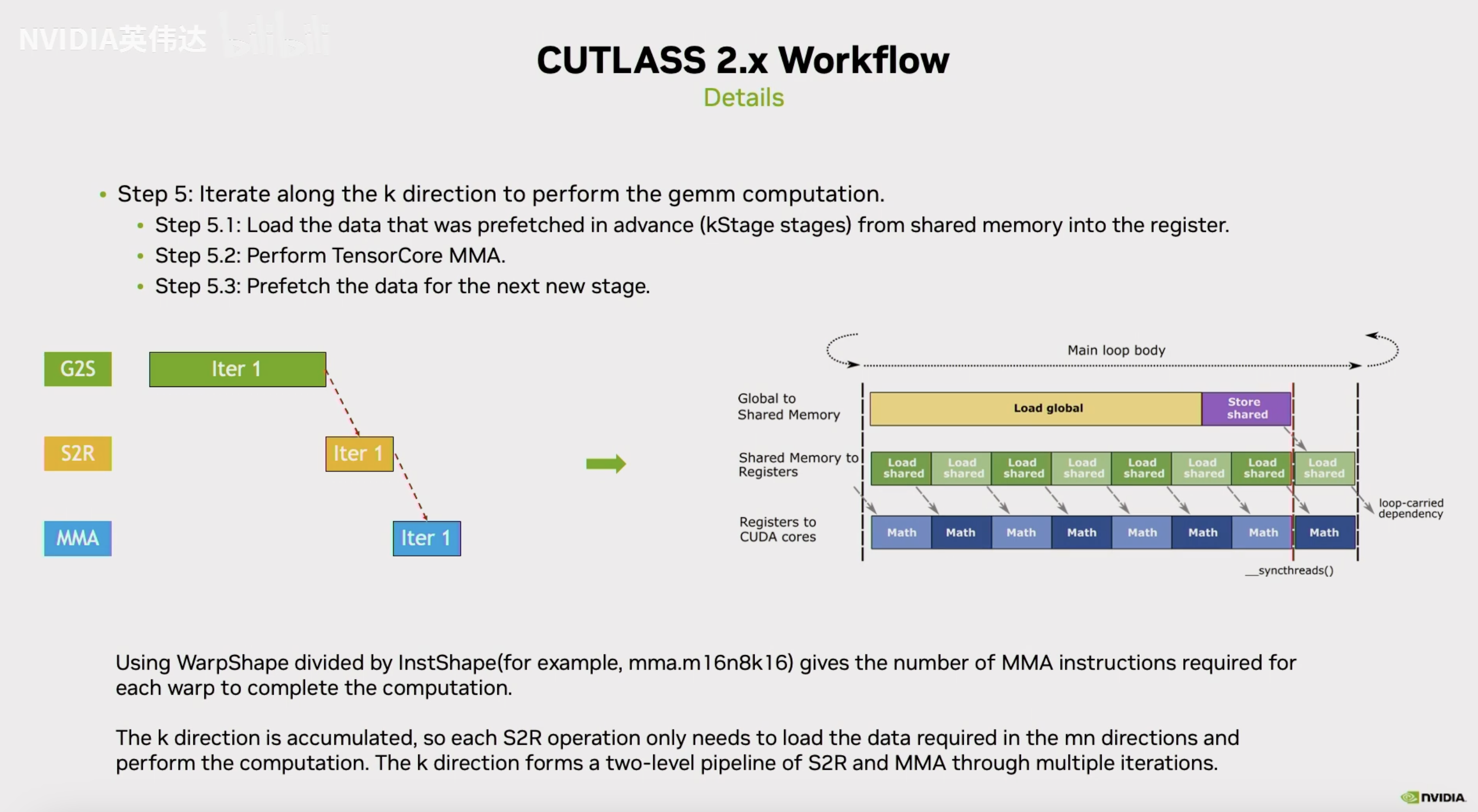
MainLoop的计算里面,首先将prefetch的数据load到寄存器里面,然后再从寄存器里面去发起Tensor Core指令的计算,这个过程中实际上也是有一些overlap的。不是把当前需要的数据直接全部从shared memory load出来,然后逐个的去遍历进行MMA(Tensor Core指令)计算。而是像Slides中左图这样,一般TensorCore指令一般是mma.m16n8k16或者mma.m16n8k8这种,那么WarpShape一般来说它的大小是大于等于这个实际的Tensor Core指令shape的,那么就意味着在MNK方向一个warp可能要执行多条TensorCore指令。我们知道在MN方向的Tensor Core指令它对应的确实是一个不同的输出,需要有各自的不同的寄存器去缓存这部分输出。但在K方向是一个累加的方向,所以K方向上无论有多少条Tensor Core指令并不需要去分配额外的寄存器来缓存输出。因此在实际的计算过程中,是拿WarpShapeK去除以InstructionShapeK从而得到在K方向上一个Warp需要发射多少条Tensor Core指令,然后把它变成一个循环,在循环体中每次只会load这一条Tensor Core指令所需的数据到寄存器然后做对应的Tensor Core计算。与此同时,可以并行的去把K方向下一条Tensor Core指令load的数据的指令发射出去。这样就形成了一个从Shared Memory load到寄存器以及Tensor Core指令相互计算之间的Overlap。
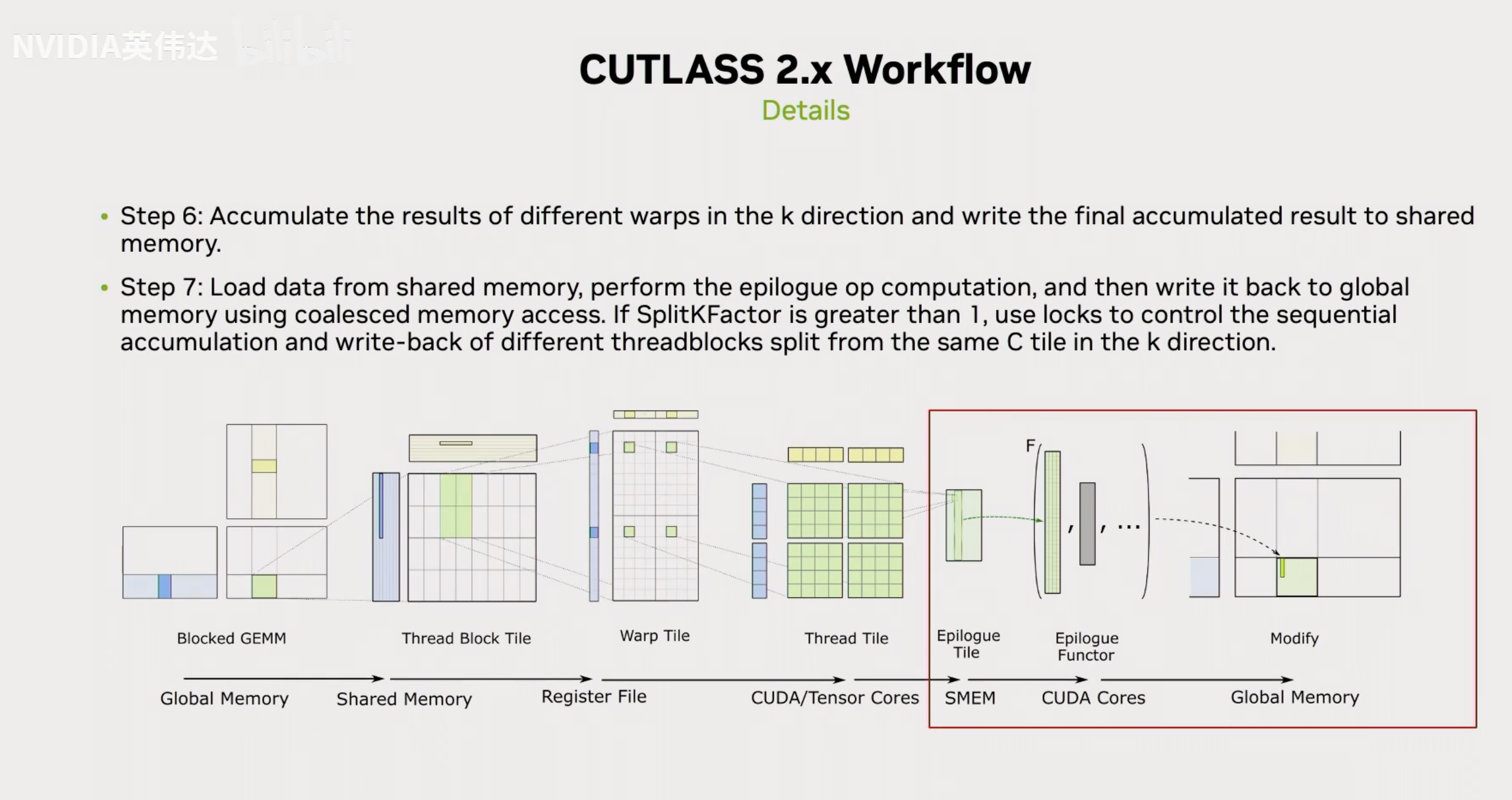
完成了刚才的几个步骤之后,基本就是CUTLASS的Prologue和MainLoop的主要部分了。最后还有一个Epilogue计算,Epilogue计算可能有2步,第一步就是把K方向不同warp的数据给累加起来,第二步就是把已经计算完的数据重新从Shared Memory load到寄存器然后执行一些可能存在的Epilogue OP,例如Activation计算,算完后就把数据写回到Global Memory里面。如果SplitKFactor是>1的话,就会用一个锁来控制线后去写入或者是用一个并行的方式写到不同的Buffer,最后Reduction。以上就是整个CUTLASS 2.x kernel计算的整体流程。

这是刚才CUTLASS 2.x kernel计算的整体流程PPT的总结。
如何基于CUTLASS 2.x实现Mixed GEMM

要实现Mixed GEMM相比于刚才的普通的GEMM需要做的修改有哪些呢?首先,AWQ需要额外的对Activation乘以一个scale,这是只有AWQ才需要的。在Load A/B矩阵的数据时,需要注意到现在A,B矩阵的数据类型是不同的,所以现在不能都用ldg128去load,否则load的数据个数不对等,就无法进行下一步计算。还需要进行修改的是在实际的MMA计算之前需要把B的数据从一个低比特的精度反量化回和A相同的数据类型。这些完成之后就可以类似于普通的GEMM一样完全剩下的计算。

如果是SmoothQuant的话,可以注意到在前面MainLoop部分的Prologue部分完全不需要修改,只需要在Epilogue部分把这两个Scale load进来应用到实际的数据上就可以了。
性能优化的关键:权重Layout设计

这里来介绍一下在 TRT-LLM 中为了性能考虑做了哪些tricky的事情,主要就是对B矩阵的Layout的一些调整。

首先需要介绍一下为什么需要这些特殊的Layout的调整,比如我们刚才提到的如果A,B矩阵的位宽不一样,同样用128bit的load指令去load那必然load进来的A,B矩阵的元素个数不同,就无法完成计算。其次的话就是,在实现从global memory到shared memory搬数据的时候,需要用cp.async来bypass掉寄存器,这是一个普通GEMM也会做的优化。然后,普通GEMM还会通过ld.matrix去高效的把数据从shared memory load到寄存器中。然后还会分配足够的shared memory通过multi-stage把这几个部分相互overlap起来。这是一个普通的GEMM会做的事情。

在Mixed GEMM里面,因为A,B数据类型不一样,不能使用128bit的load指令无脑load数据。就需要想办法调整它们的Layout才能保证两边都可以用ld.128指令。然后,多出来的scale和zero同样需要放到shared memory中,以及同样需要MultiStage去把它Overlap起来。接着,在实现ld.matrix的时候也有一些不同,ld.matrix就是load一个8x8的矩阵进来,默认这个8x8矩阵元素是16bit,对于FP16/BF16的GEMM来说,它load进来之后元素的排布就天然的进行TensorCore的计算,但是如果我们的weight的位宽是4bit/8bit的话就不一样了。最后需要考虑的就是需要一个高效的从int4/int8到FP16或者BF16的转换。
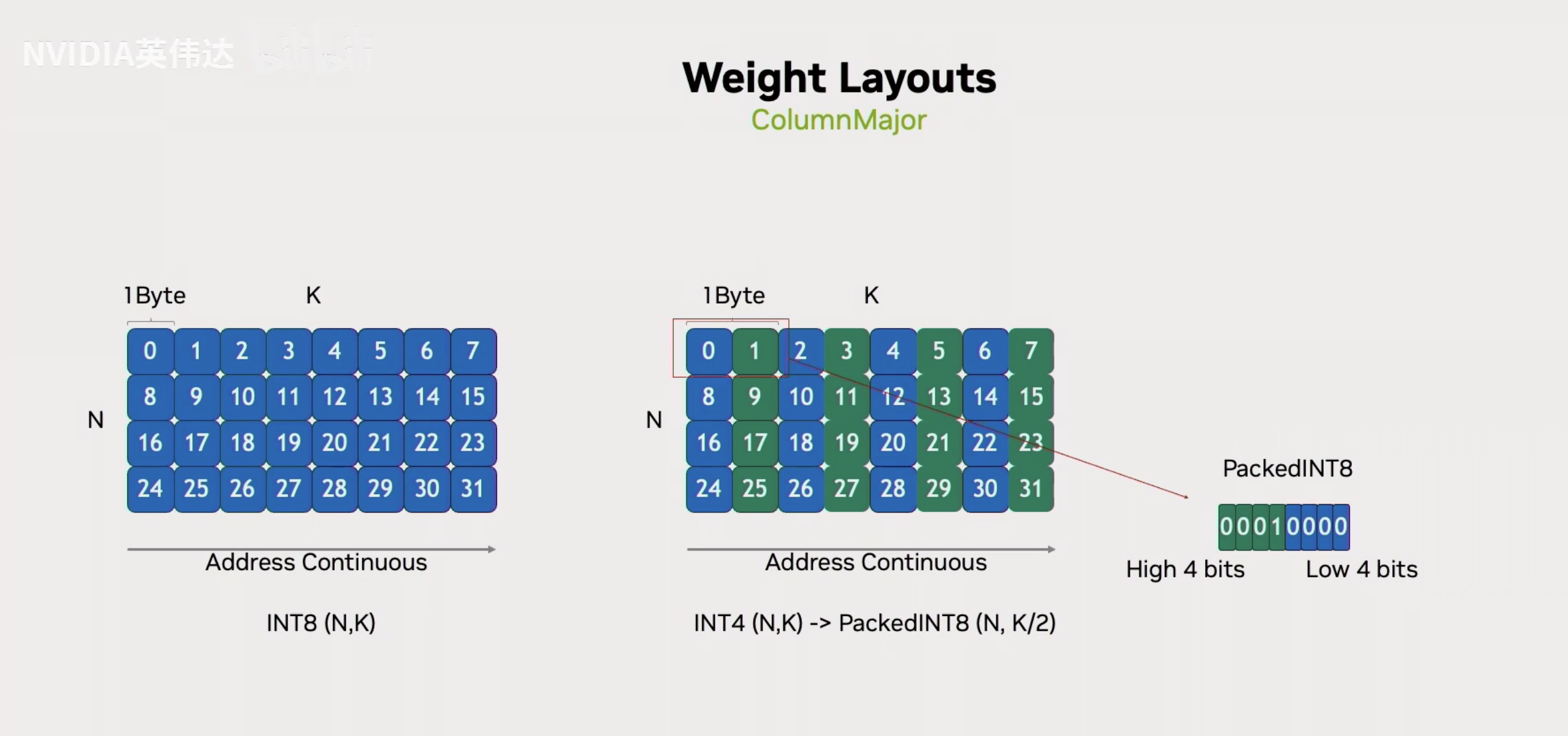
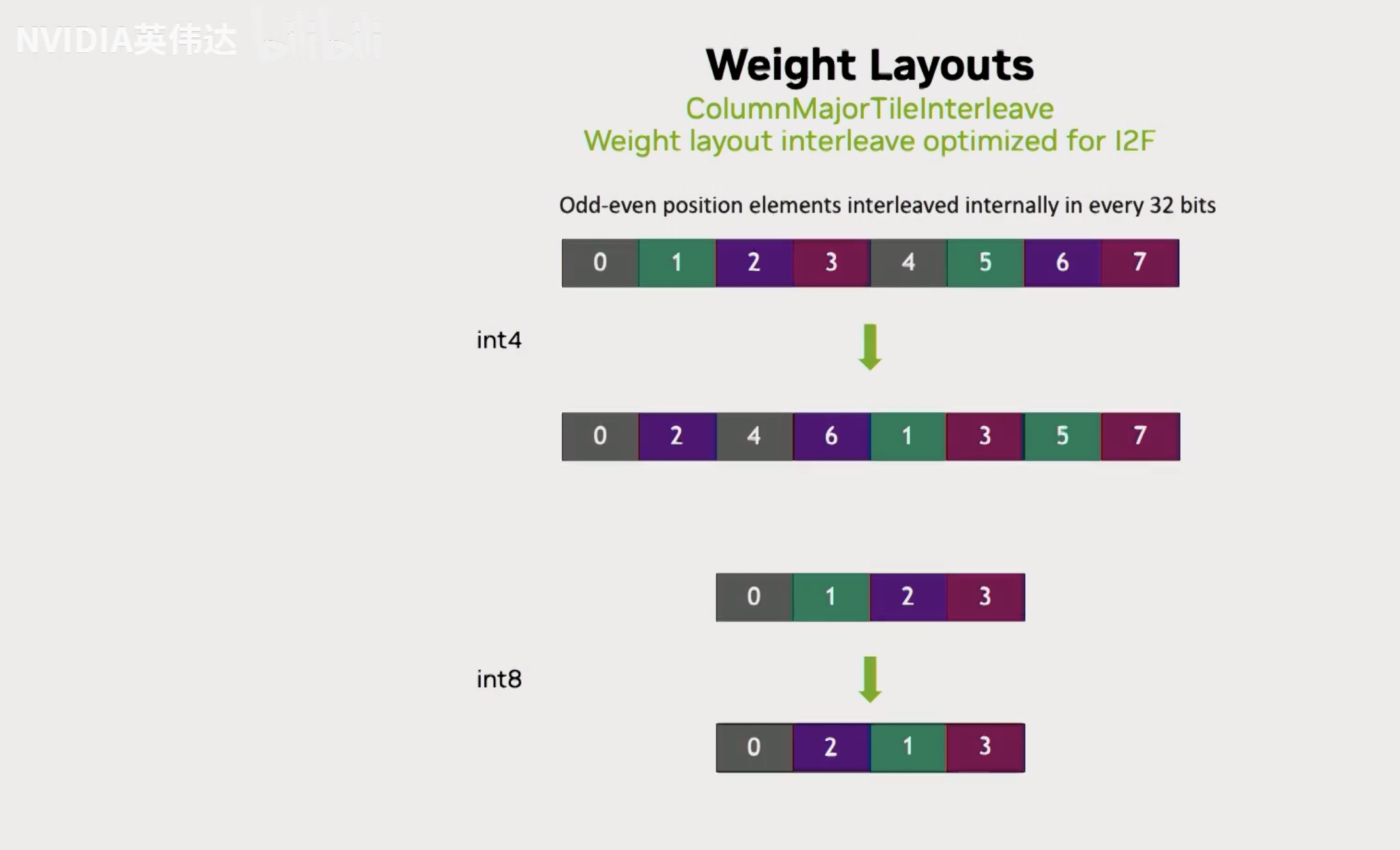
接着就是介绍Weight Layouts的细节了。首先这里展示了一个普通的ColumnMajor的weight Layout,一个N*K的B矩阵,沿着K方向是连续的。假设这个B矩阵的数据类型是Int4的话,那就是把连续的2个4bit元素给Pack成一个Byte。看0,1这两个元素,第0个元素存在低的4个bit,第1个元素存在高的4个bit。

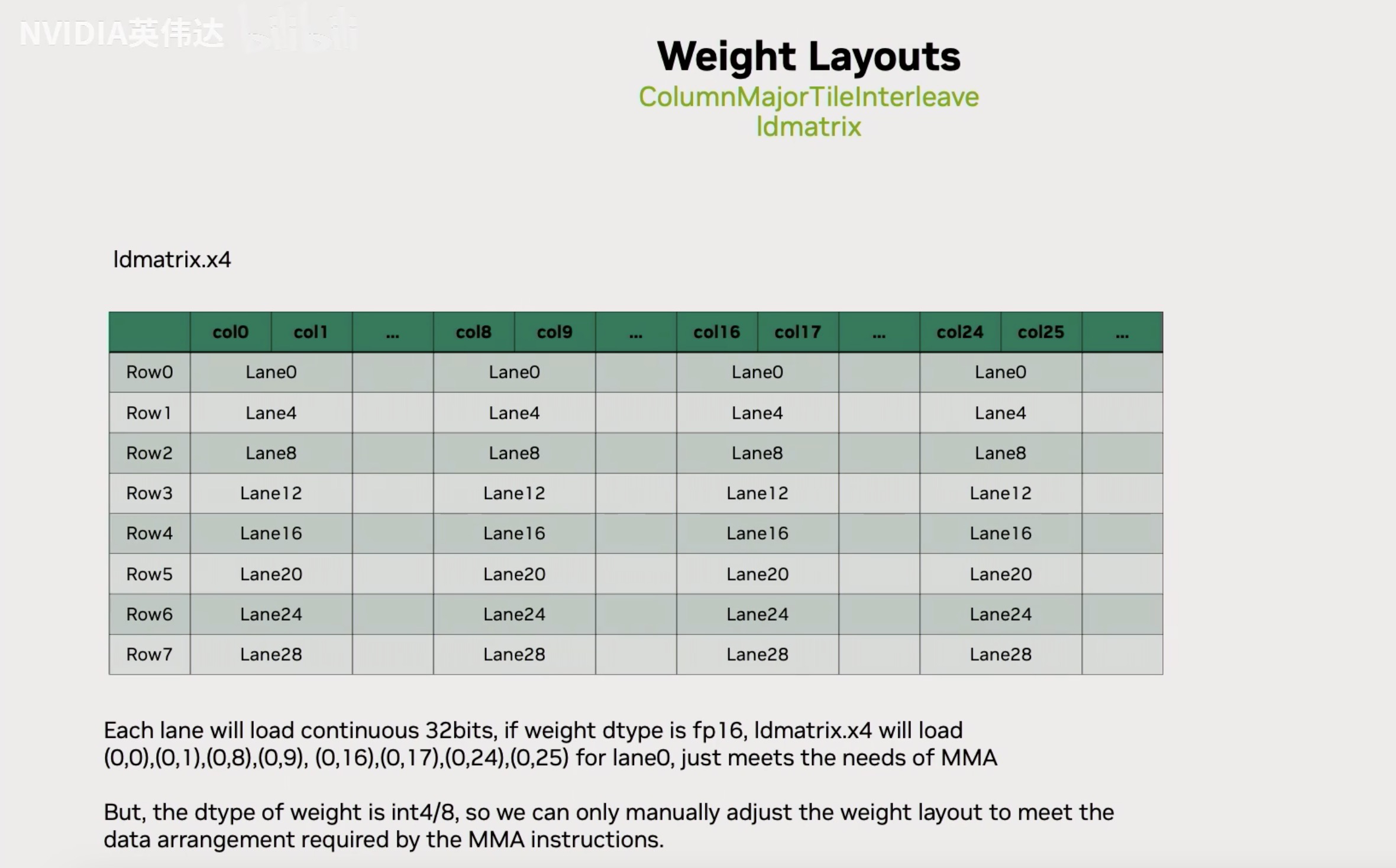
但是在TRT-LLM中,不是使用ColumnMajor而是使用一种叫做ColumnMajorTileInterleave的Layout。首先这里的代码大概描述了TileInterleave Layout的关键要素,注意到这里有一个ThreadblockK=64,这就是在TRT-LLM中实现所有的Mixed GEMM都是用64作为ThreadblockK的。这是因为这个ThreadblockK等价于拿Shared Memory或者L2 Cache Line 128 byte然后除以A的dtype位宽等于64。所以假设Activatio实际上不是FP16,而是FP8的话那这个数算出来ThreadblockK就等于128。之所以这么设置就是希望能够在K方向以一个iteration flow的数据对应到128 byte的cache line。假设A,B的数据类型不一样,那就意味着我们用一个线程一次用128bit去load A矩阵出来的元素数量必然比B矩阵的元素数量高2倍或者4倍。我们就会做一个特殊的处理,把N方向上连续的2行或者4行给Interleave到连续的一行上面去。这样的话,假设A矩阵一次load 32个元素,同样的load指令可以load B矩阵的128个元素,那这128个元素对应的就是4行32个元素interleave到一起的结果。在实际过程中,不是按照32个元素去interleave的,而是按照64个元素去interleave的。
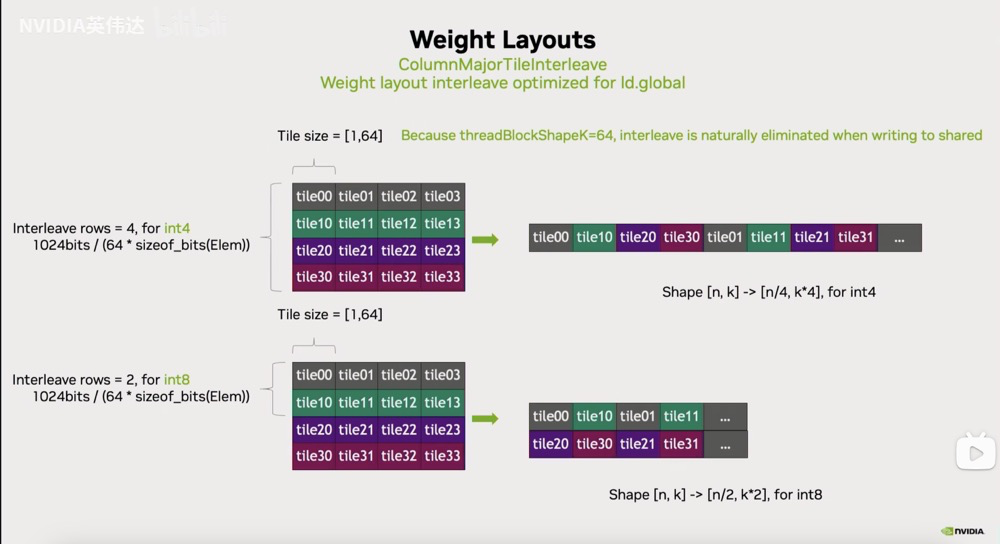
这里有2个可视化的图对上面的TileInterleave Layout进行讲解,如果以int4为例子,一个原始的ColumnMajor Layout对应左上角的图,这里一个tile是64个元素。经过Interleave之后,它会把前4行的64个元素interleave到一起。这样再load B矩阵的时候,一次load 256个元素进来,刚好就对应着所需要的4行的每行64个元素。把它写回到shared memory的时候,因为ThreadblockK=64,所以刚好把它连续interleave之后的这个数据重新放回到了shared memory里面不同的行上去,因为shared memory里一行可能只有64个元素。所以刚好通过这个形式把interleave的Layout给消掉了。
除了这种针对ldg做了interleave layout优化之外,还会有一些针对别的指令或者别的CUTLASS用的优化技术来进行的优化。
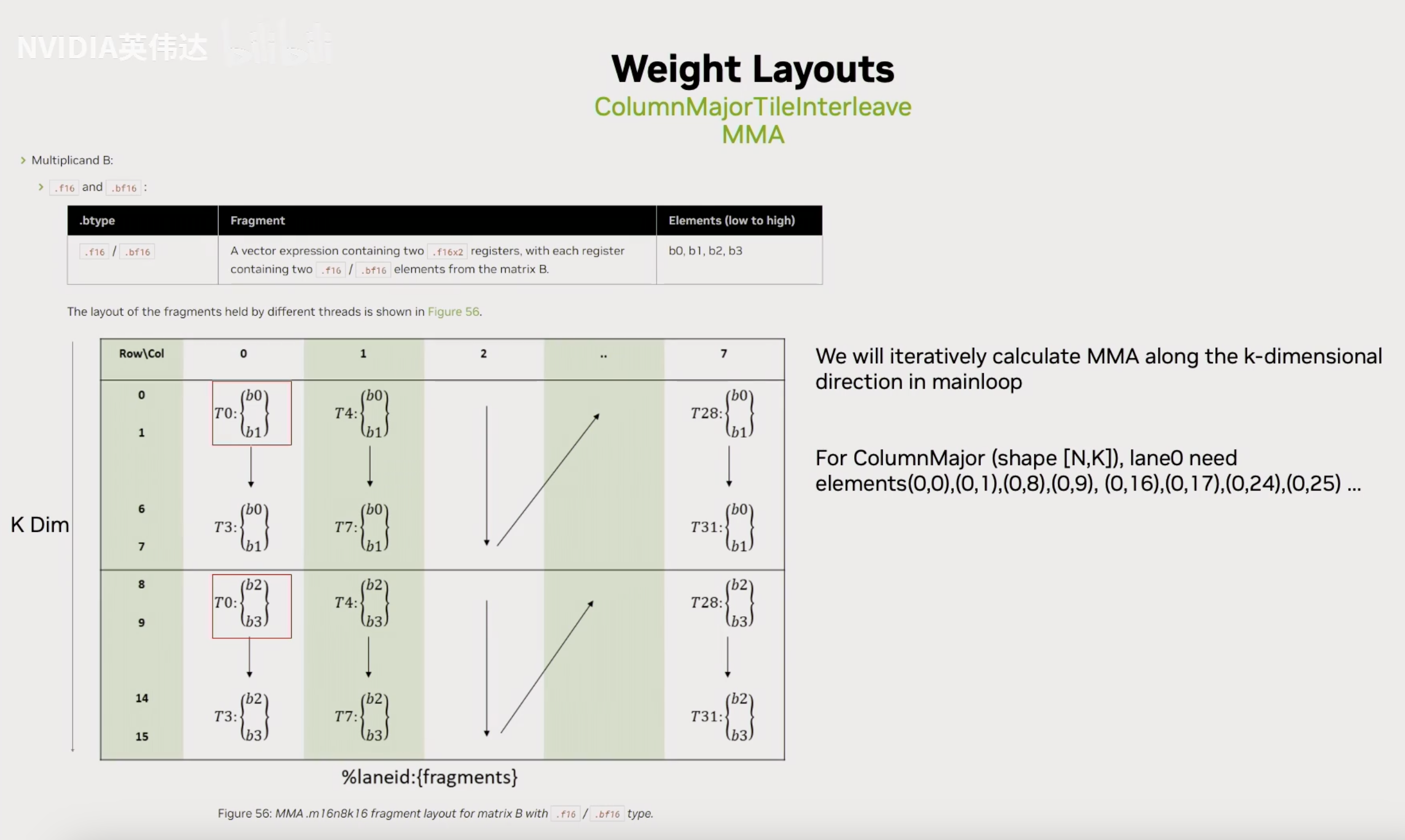
首先介绍一下CUTLASS的Tensor Core指令,注意到Tensor Core指令对数据排布是有要求的。假设拿16x8x8的TensorCore指令来举例,那B矩阵可能每个线程会对应到4个byte,然后相邻的4个线程去load相邻的8行,每一行是一个16bit的数据。然后从下一行开始,下4个相邻的线程去load。这就意味着同一个线程比如第0个线程就来自于整个B矩阵中N方向第0行,K方向的第0列,第1列,第8列,第9列,第16列,第17列,大家也可以看下面这个图,和上面的图原理一样但是好理解一些:
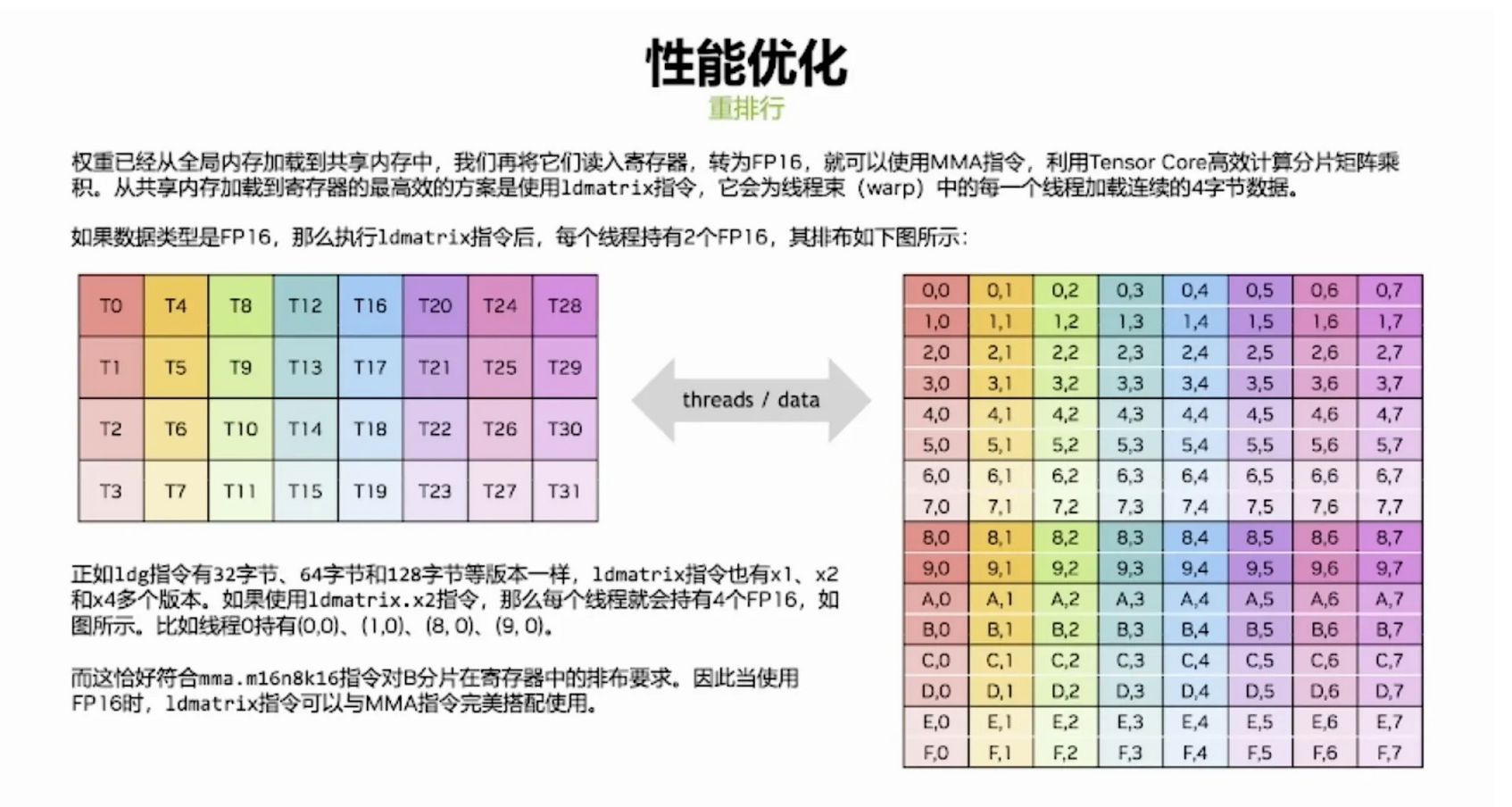
我们在实际的CUTLASS里面再去把数据从shared memory load寄存器去做Tensor Core指令计算的时候,也会用一种叫ld.matrix的指令进行数据load。ld.matrix的作用就是他会按照以16比特的元素位宽为基础的8x8矩阵去load,其中也是warp中的一个线程会去load连续方向上的两个16bit的元素到一个线程里面去。这就刚好和前面对Tensor Core对数据排布的要求是一致的。上面可以知道,Tensor Core里面连续的4个线程会需要连续的8个16bit的元素,接下来在下面8列会重复下面32个线程的排布。
ld.matrix指令本质上有3种不同的类型,是.x1,.x2,.x4。当.num设置为.x4的时候,它就可以在任意的方向上就32个线程每个线程传入一个地址,其中最开始的4个线程去load连续的16个byte,再4个线程从第二个地址load连续的16个byte,以此类推。这样的话就可以通过ld.matrix x4的形式去直接把前面Tensor Core指令计算所需要的那些元素给load到对应的线程的寄存器里面去。

这里还有一个问题就是ld.matrix假设了元素的数据位宽是16bit,它一个线程会去load的连续的4个字节,如果刚好数据类型是bf16或者fp16,这样刚好就满足TensorCore计算的Layout的要求了。但实际上我们的B矩阵可能是个8bit或者4bit,这就意味着如果它load连续的4个字节到一个线程里面去,它实际上是把真正数据的01234567全部load进来了,但实际上23应该在下一个线程,45应该在下下个线程。所以,如果直接用ld.matrix就会把不同线程的数据load到同一个线程里面去,这样就不能再满足Tensor Core计算的需求。为了利用ld.matrix,以int4为例子,我们对每32个元素内部进行了一次重新排布,排布完之后就是把ld.matrix一个线程所需要的那些4个字节的数据全部提前放到一起去。这样的话,再利用ld.matrix指令进行load的时候,它的一个线程就能直接load到最下方图中的018916172425这样的符合Tensor Core计算规律的数据排布。
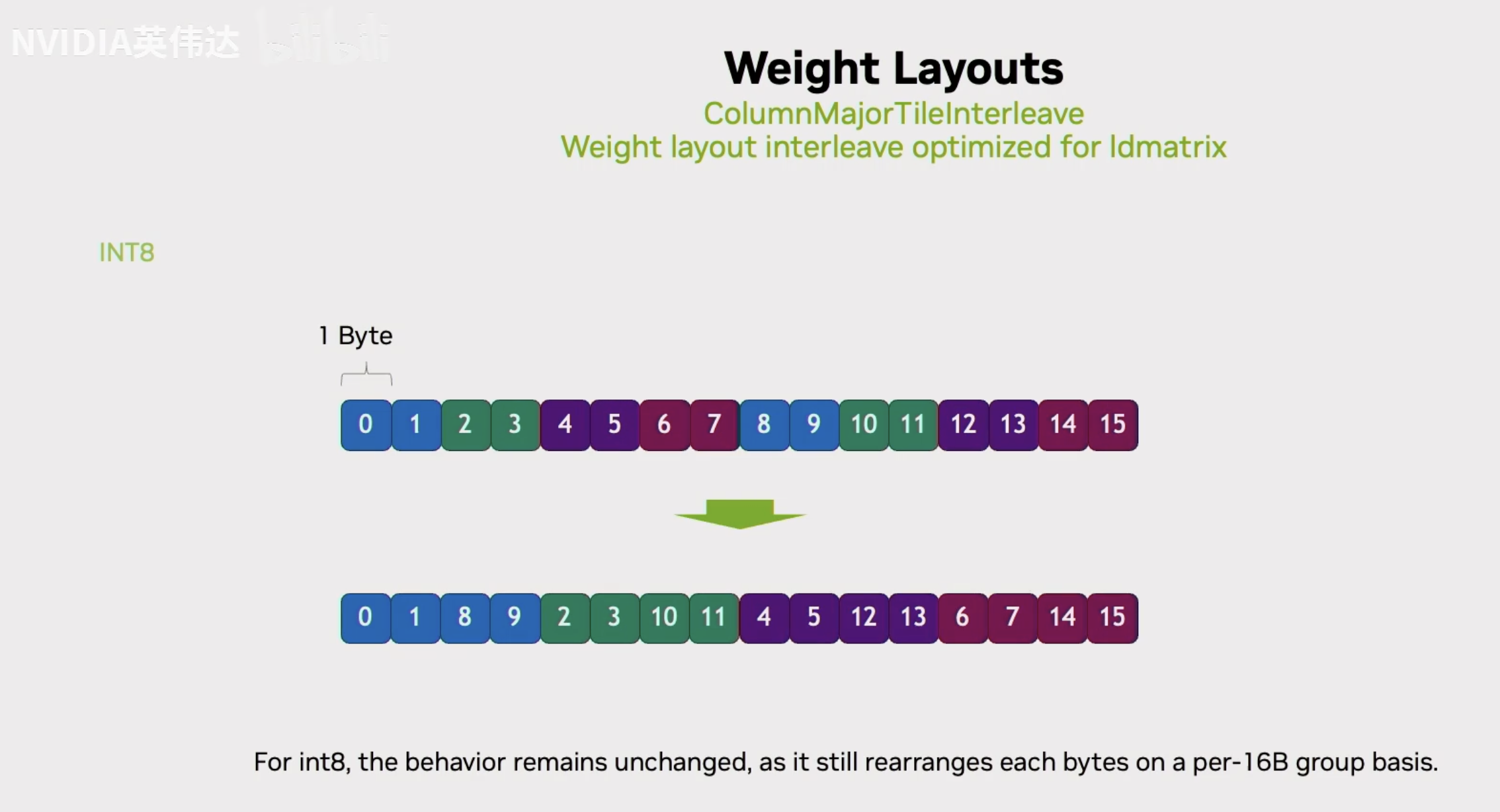
然后对于INT8的话也是同样的形式,只不过int8是把连续的2个元素放在一起,然后把0189放到连续的4个byte里面去。然后用ld.matrix去load。
Int8/Int4快速转换FP16
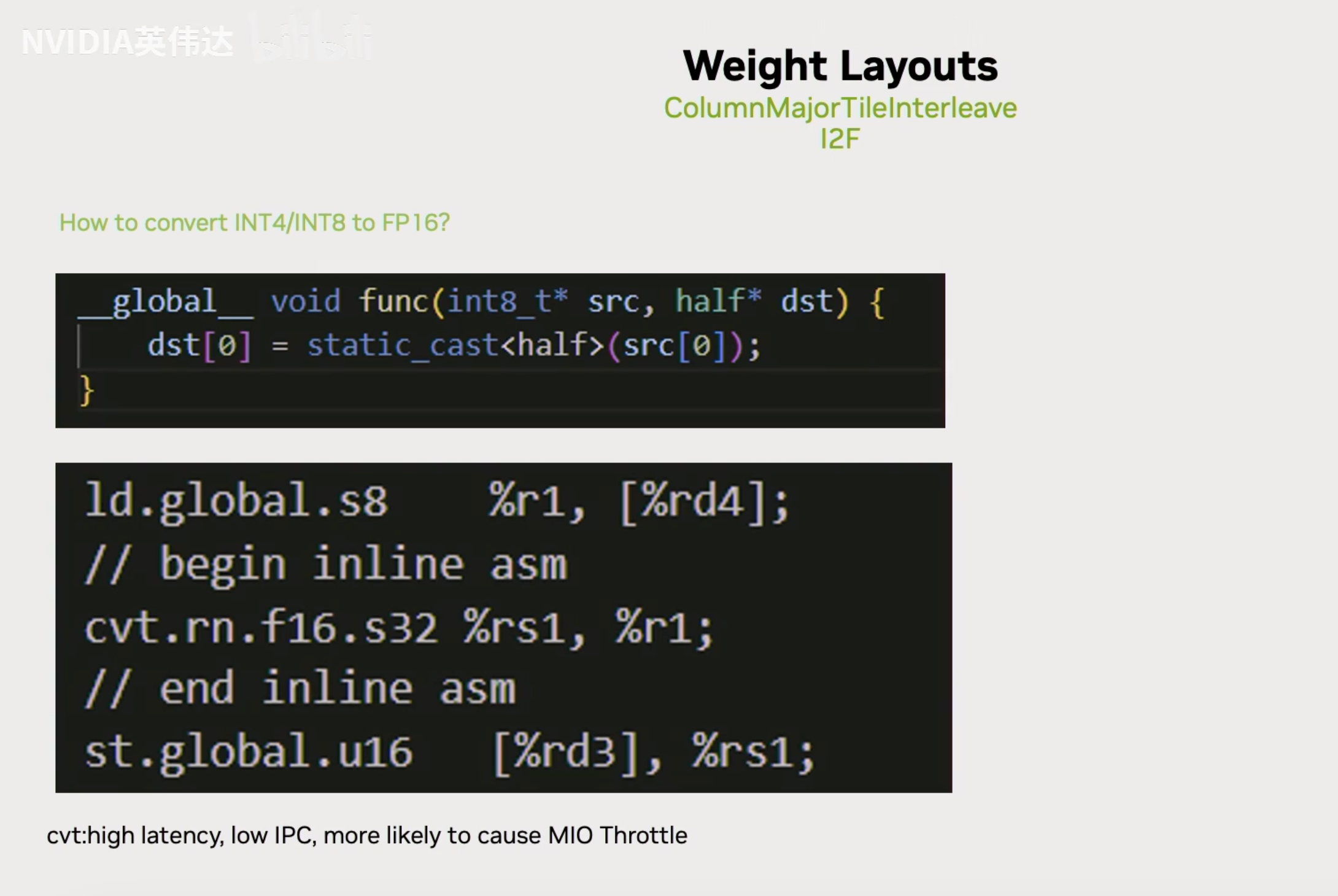
最后一步就是我们怎么去实现一个快速的从int4或者int8到FP16的类型转换,以及为了实现这个类型转换需要对Layout进行哪些调整。这里展示了一个最普通的从INT8到half类型的数据转换,就直接用static_cast,可以看到它对应的PTX指令调用了一个convert.round,但实际上用convert指令它的latency是比较高的,并且可能会引起MIO Throttle。
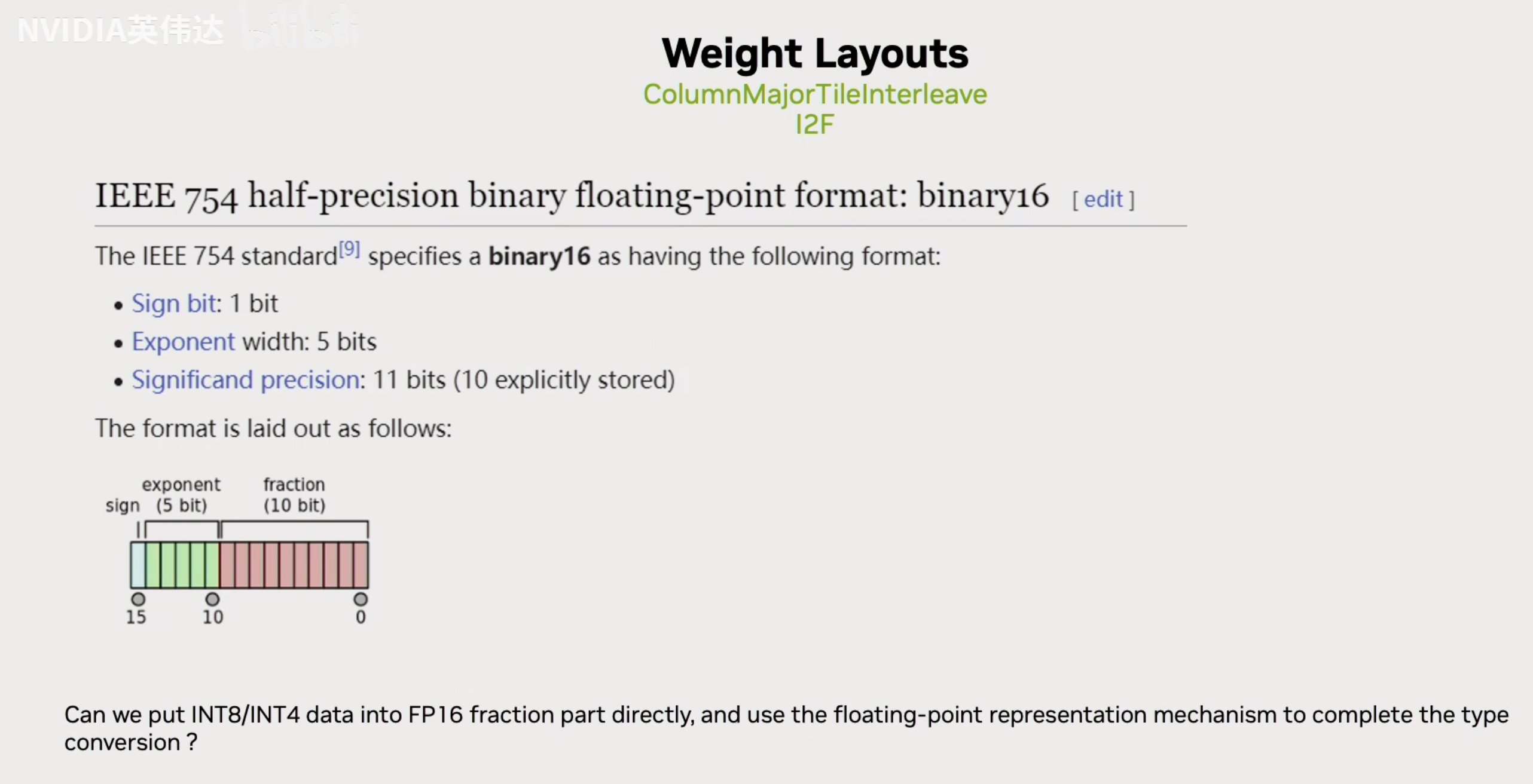
这张slides展示了FP16的IEEE 754标准,一个16bit的数里面包含1个符号位,5个基码位,10个尾数。

假设我们有一个uint8的数143,如果我们把它放到实际的FP16的尾数位里面去,那么我们是否有办法通过合理的设置基码位把143表达出来呢?那我们按照已知的FP16的数值计算方法,拿基码位的二进制前面加上一个1.x,然后去乘以2的(基码位的值-15)次方,我们已知143对应的实际上对应的是下面的值。假设我们想用这个FP16的值来表达Int8,我们可以发现如果x=25的话,我们把上面的FP16的值减去1024就是下面的143了。因此,我们只需要把int8的值放到尾数位,然后把它的基码位设置成25,然后再把FP16的数值结果减去1024就可以得到UINT8转换到FP16的值。
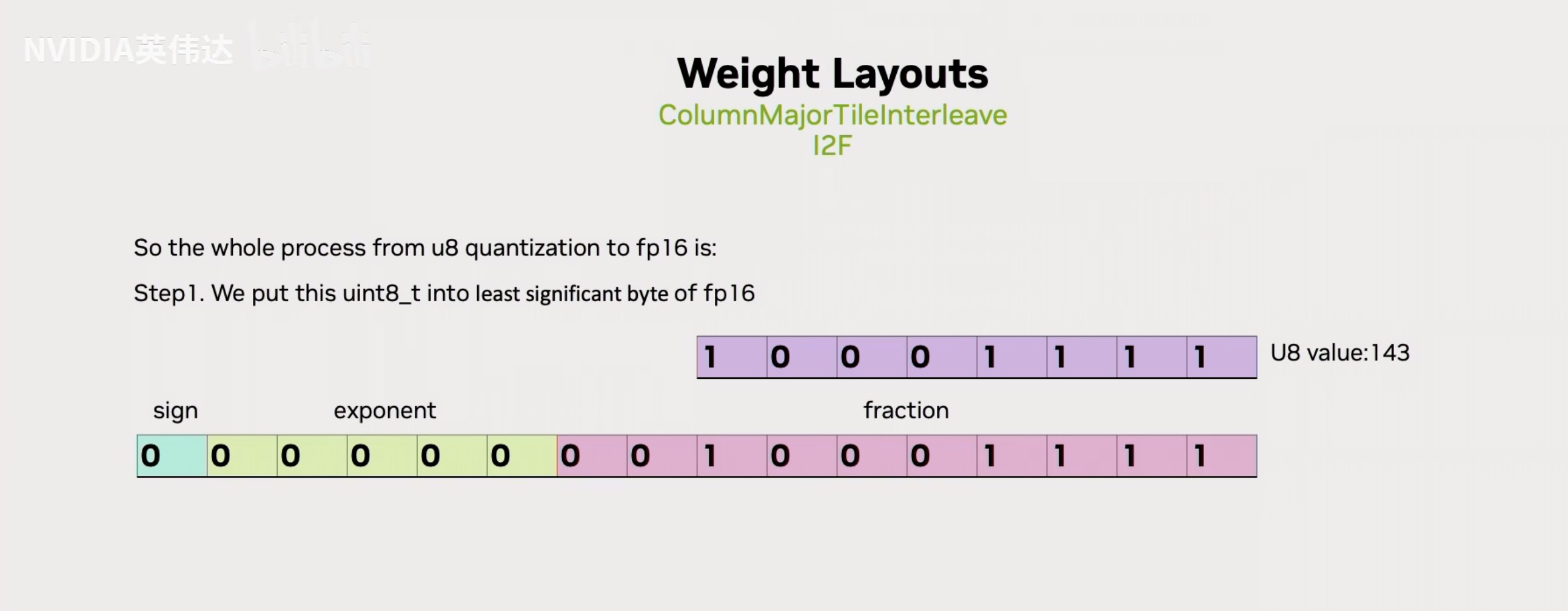
总结一下就是直接把UINT8的数值放在FP16的尾数位,
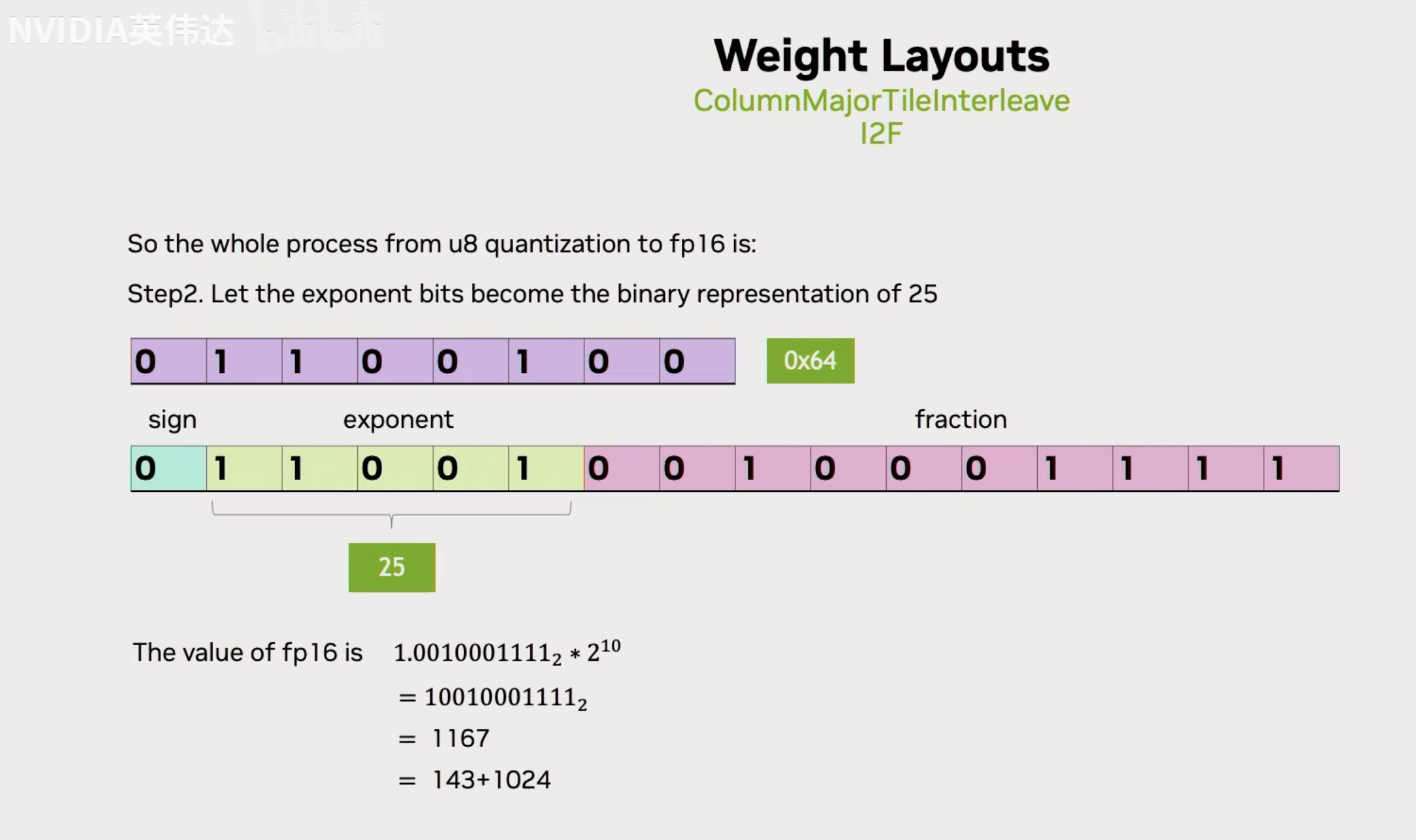
然后再把FP16的基码位设置成25,这个25对应的十六进制表示就是0x64,
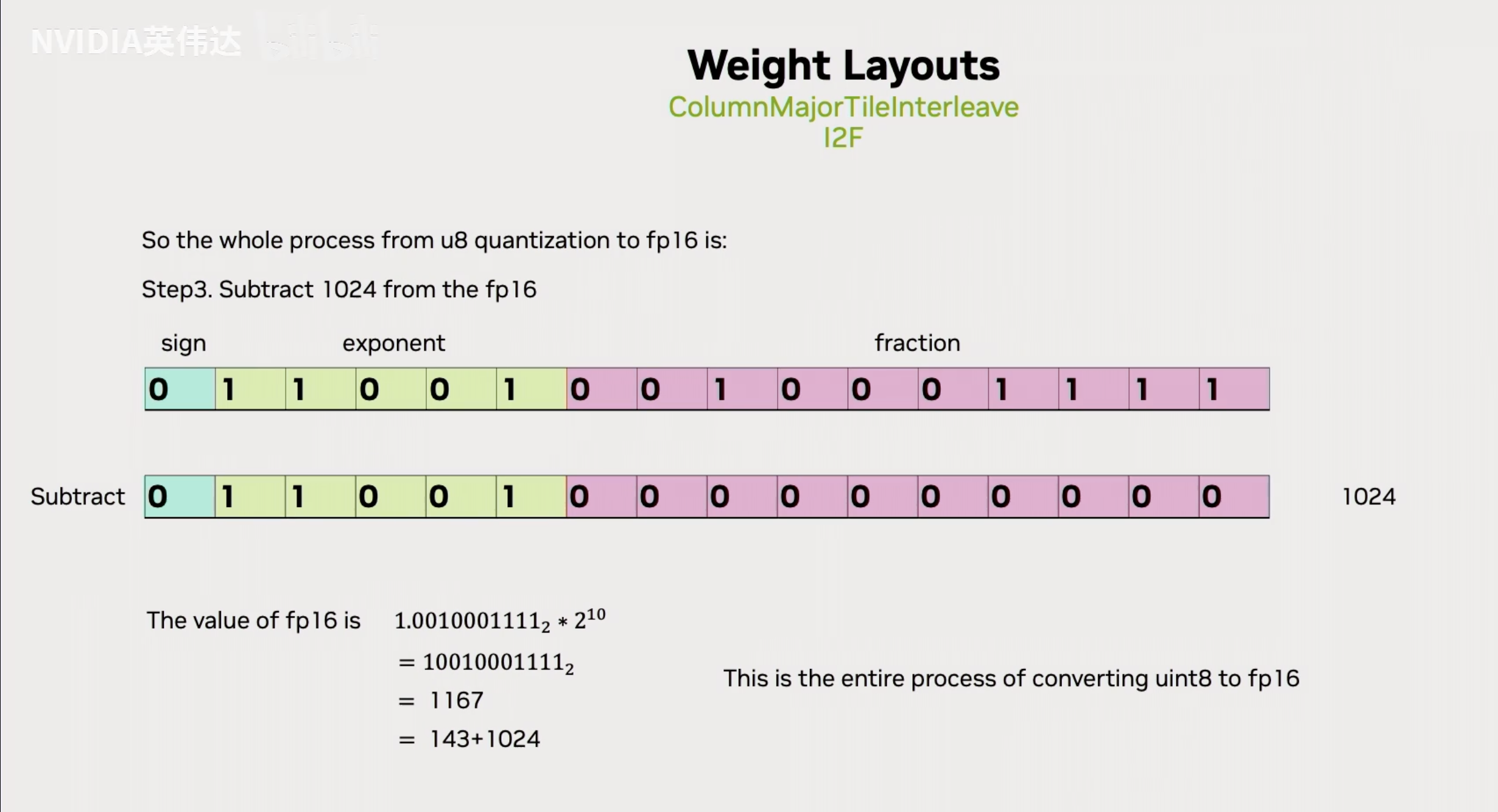
随后再把最终的这个值减去FP16形式的1024,就完成了从UINT8到FP16的转换。

如果是Int8的话,应该怎么做呢?可以注意到UINT8和INT8只是数值范围的区别,那么我们需要把INT8的数据加上128,就能把它转换成UINT8的形式。这样转换出来的FP16的结果,只需要在减去1024的时候多减去128,就恢复到了对应的原始INT8的数值。
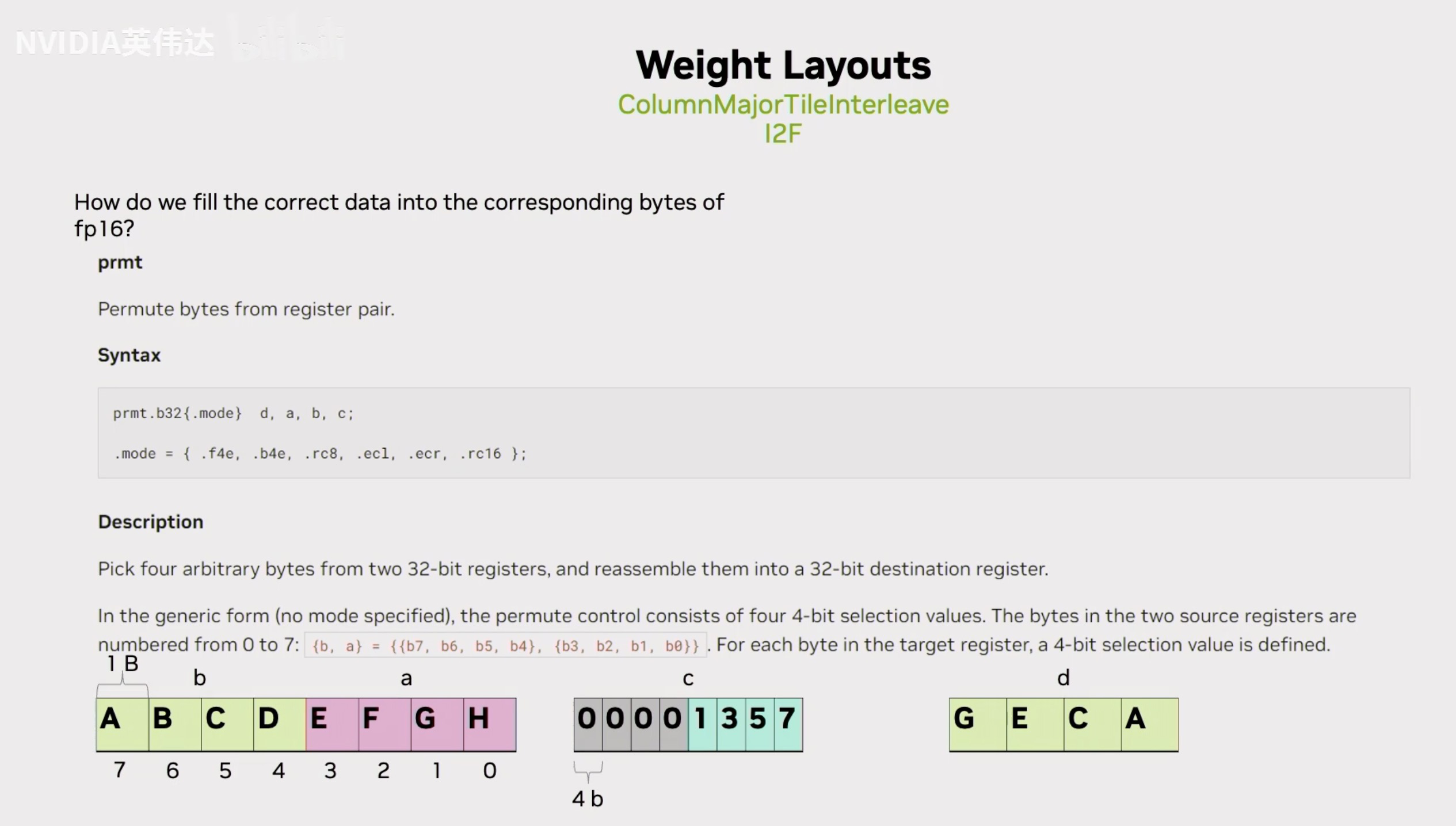
那么我们怎么实际的去用指令完成上面描述的这个操作呢?可以注意到有一种叫作prmt的PTX指令,这个指令做的事情就是从2个32bit的寄存器A,B中抽出4个8bit组成最终的d。而这4个8bit怎么抽取,就是每个8bit对应到c寄存器里面的低4bit,就是说c寄存器的低4bit每个bit都是一个索引,假设A,B两个32位寄存器里面存放的是下方左图这样的数据形式,即ABCDEFGH。那么在c寄存器中,索引的4个数字分别是1,3,5,7,那么最终这个D寄存器里面的4个8bit数据就是GECA。通过这种指令就可以实现从32bit寄存器里面抽取对应想要的一个字节出来的效果。
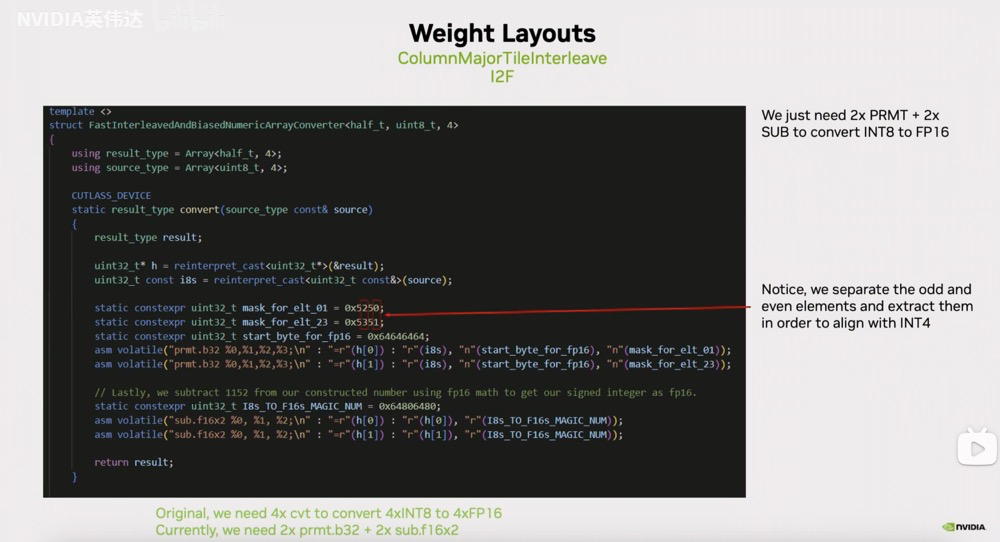
对应到TRT-LLM的转换代码就是这样的形式,我们可以注意到它用permute指令从输入的UINT8数据和magic number组成的这两个32位寄存器中去抽取4个8bit,抽取的索引放在这个mask_for_elt_01/23中。具体去看存放索引的4个bit分别是0525。这里的0和2就分别对应到了实际的INT8输入数据中的第0个8bit和第2个8bit。通过这样的permute指令之后,就可以把实际输入的4个UINT8中的4个UINT8中的第0个UINT8和第2个UINT8抽取出来放到两个连续的FP16寄存器中。下面这条PTX指令则是把第1个UINT8和第3个UINT8抽取出来放到另外两个连续的FP16寄存器中。
这个magic number的5属实没看懂是什么意思。
之后再像我们刚才描述的那样,在它的基础上减掉(1024+128)就得到了真实的这4个INT8对应的FP16的值。我们可能会注意到,这里为什么要分别抽取01和23,而不是抽取0123呢?这主要是为了和之后的INT4的实现保持一致,在INT4的实现里不得不按照02,13的方式去抽取。

前面介绍了INT8到FP16的转换,如果是INT4应该怎么转呢?permute指令只能以8Bit为单位进行数据的操作,但是在4Bit的转换中,我们知道4Bit就是一个8Bit里面高4Bit存一个数据,低4Bit存另外一个数据。那么,我们就需要一种形式能把实际的8Bit里面的高低4个Bit给抽取出来。
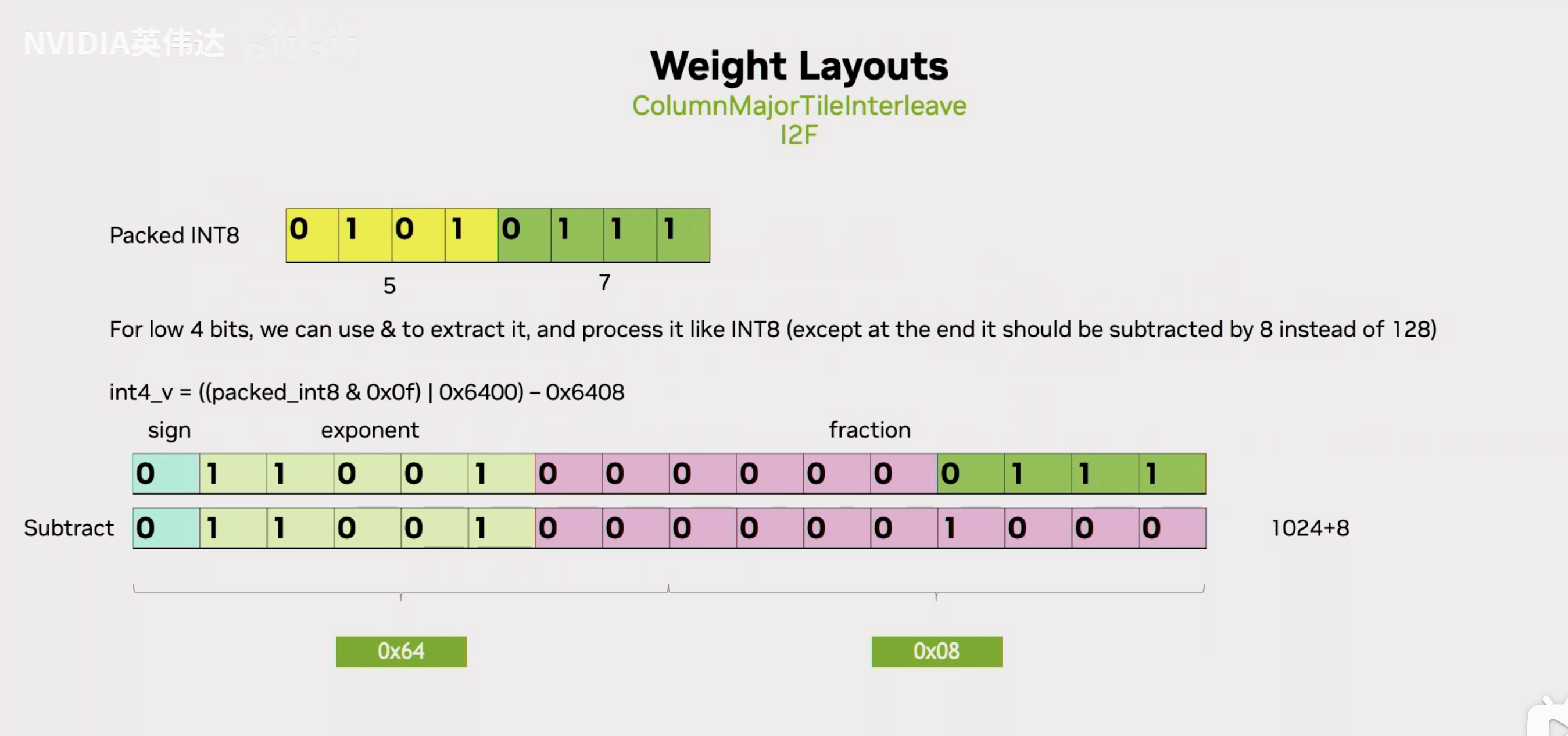
抽取出来之后我们应该怎么做呢?先看低4个bit,假设我们以位运算的方式把8Bit中的低4个Bit给抽取出来放到一个FP16的尾数里面去,然后前面也在基码位上赋值和Int8相同的25,也就是16进制的64。我们再把这个得到的值减去(1024+8),就得到了最终这个低4Bit对应的FP16的值。

那如果是高4个Bit应该怎么做呢?我们注意到低4个Bit是直接放到最低的4个Bit位,高4个Bit同样用位运算抽取出来之后这高4个Bit是存在于一个Int8的高4Bit里面,那放到尾数位的话那么它就需要去进行一个额外的除以16的操作,相当于右移了4位,最后就移到了黄色的位置。移动到这里之后,就可以进行和刚才一样的那些操作了,减去对应的值就得到了实际对应的FP16的值。这里减去的值是1024/16=64,还要加上8。
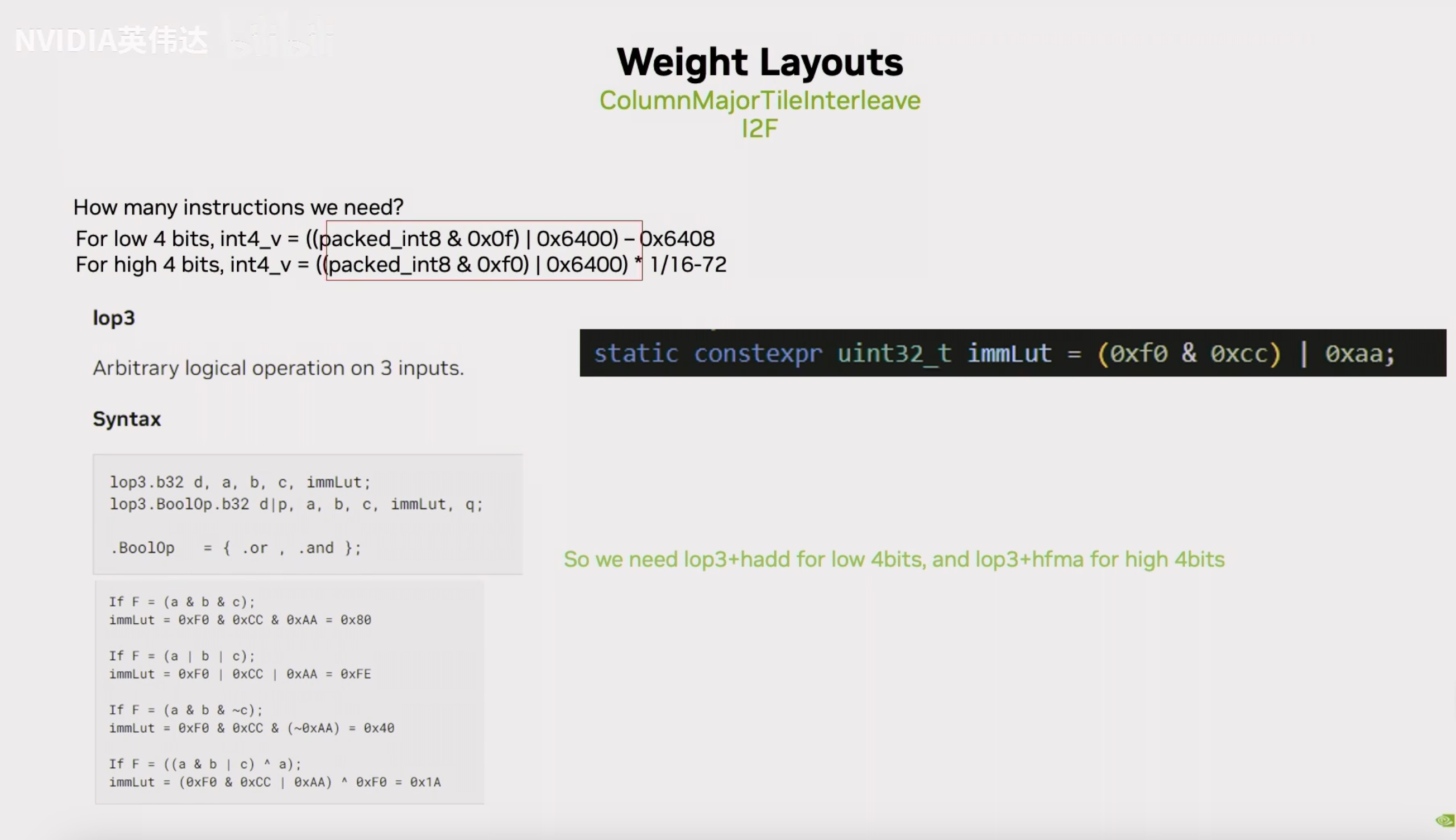
注意到在提取Int4数据的时候是用这张Slides的形式去提取的,而刚好有一种叫lop3的PTX指令可以完成这件事情。lop3这个PTX指令的大概描述就是他会在输入a, b, c三个寄存器作为输入,然后有一个Lut值,这个Lut值是怎么确定的呢?假设a,b,c分别对应了0xF0,0xCC,0xAA,我们把这三个值进行我们想要的操作得到的值作为Lut值,把这个Lut值放进去之后指令就会自动对a, b, c进行相应的操作,把结果写到d。所以,我们就可以利用这个指令把Lut值给它,它就可以帮我们高效完成Int4数据的提取了。最后,我们就把Int4转成FP16的过程转换成了一条lop3指令加上一条fma(或者sub)指令。
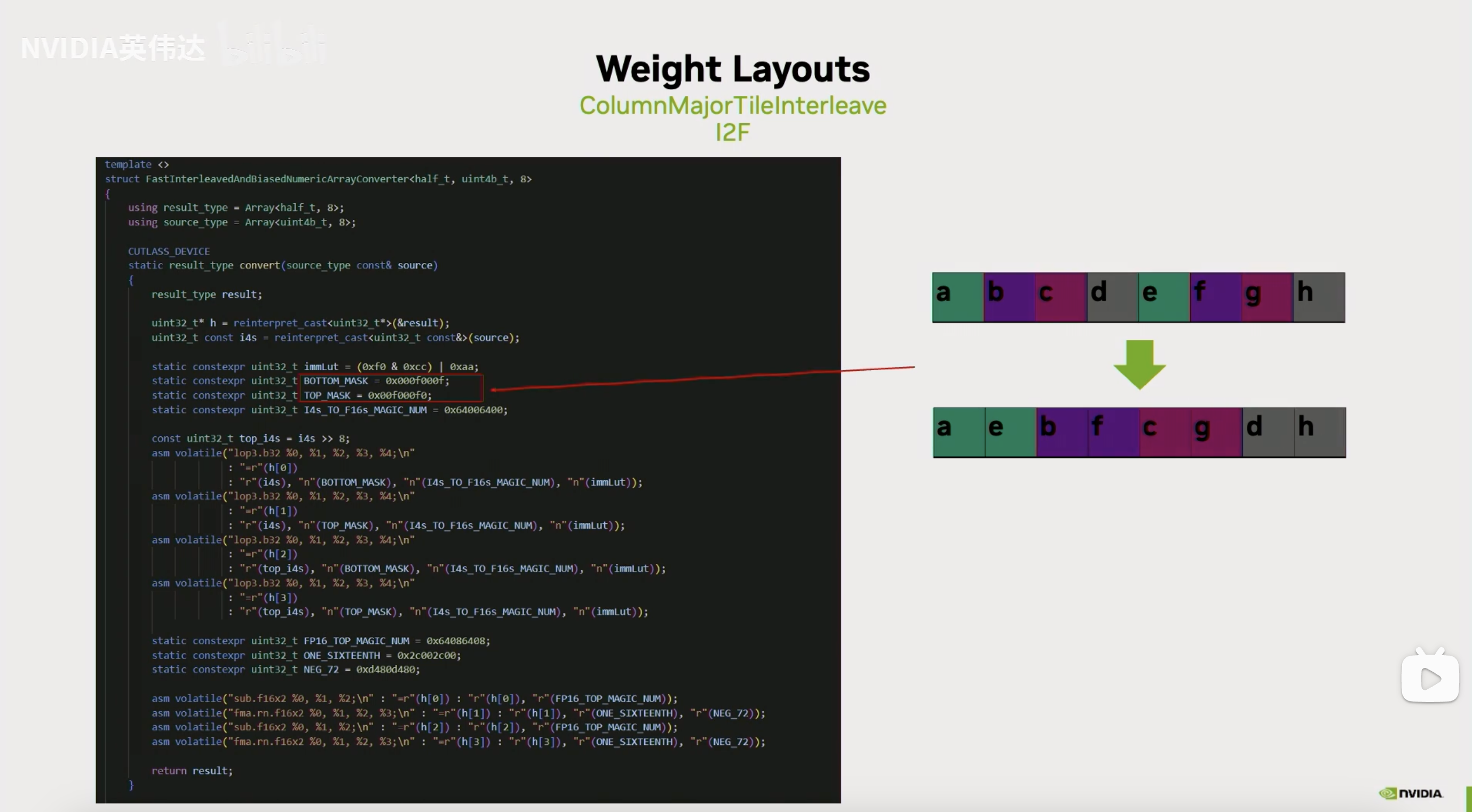
这张Slides展示了Int4到FP16的具体代码实现,我们注意到它提取的时候会用到0x0f或者0xf0来提取Int4,这样的话假如我们有连续的Int4的话,那被提取出来的分别是第0个Int4和第4个Int4以及第1个Int4和第3个Int4。所以它的奇偶被分别提取了出来。实际上我们是用8个连续的Int4来进行类型转换,因此它每次先把第0个Int4和第4个Int4提取出来,放到两个连续的FP16里面去,然后再去把第1和第5个Int4提取出来,放到两个连续的FP16里面去,以此类推。我们之前在做Int8的时候也分奇偶提取就和这里不得不做的这个数据提取动作保持一致。
为了实际计算的时候去逆转这个元素排布的变化,我们需要在计算之前把Layout进行相应的调整。就是说以Int4位例的话就分别把它的奇偶位元素分别提取出来,这样在我们真正做计算把它从INT4转成FP16的时候,就会通过上一页Slides介绍的操作完成对这个Layout的逆运算,还原回了真实的连续排布的layout。
这就是描述的最后一种快速的Int4/Int8转FP16的优化的layout变化。通过这种优化就把前面提到的一个convert指令转换成了一系列lop或者prmt指令。虽然指令数没有变化,但是指令的latency会更低。
总结

这三种Layout变换分别是确保A, B矩阵都可以用128比特去load,从而最大化内存带宽。另外一种Layout就是为了利用上ld.mxtrix高效的去把B矩阵从shared memory取出来,以及最后一种Layout变换就是通过这些算术运算和逻辑运算的去替换掉convert指令。