向量搜索并非轻而易举!
向量搜索,也称为向量相似性搜索或最近邻搜索,是一种常见于 RAG 应用和信息检索系统中的数据检索技术,用于查找与给定查询向量相似或密切相关的数据。业内通常会宣传该技术在处理大型数据集时非常直观且简单易用。一般来说,您只需将数据输入到 Embedding 模型中生成 Embedding 向量,然后将这些向量存储到向量数据库中即可检索到所需的结果。
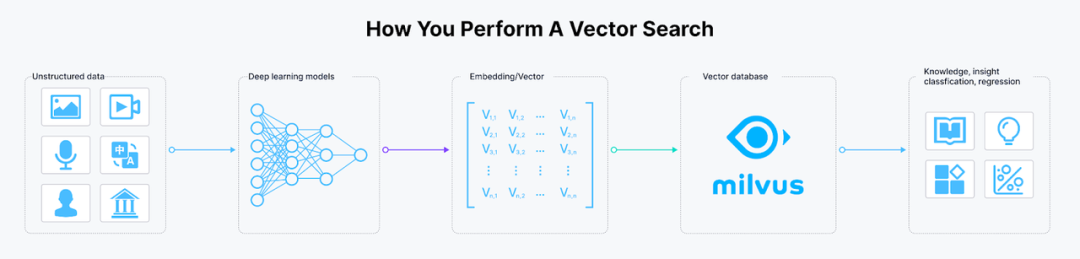
许多向量数据库厂商通常会使用“简单”、“用户友好”和“易用”等词汇来描述向量数据库的能力。这些厂商还会宣传“只需几行代码就能获取显著的成果,绕过机器学习、人工智能、ETL 过程或系统调优等复杂步骤”。
这些宣传本身并无任何问题——向量搜索就像使用基本的数值库(如 NumPy)一样轻松。以下示例的 Python 代码只有十行左右,使用 KNN 算法,实现了向量搜索。对于数据规模在一千到一万个向量的小型应用而言,这种简单的方法既有效又准确。
import numpy as np# Function to calculate Euclidean distancedef euclidean_distance(a, b):return np.linalg.norm(a - b)# Function to perform KNNdef knn(data, target, k):<