大数据产业创新服务媒体
——聚焦数据 · 改变商业
2022年末,ChatGPT-3.5的惊艳亮相,瞬间引爆了全球范围内的生成式AI(GenAI)热潮。
这场现代版的"淘金热"迅速在科技领域蔓延,尤其是在全球两大科技强国——中国和美国之间掀起了一场激烈的竞赛——短短数月内,上百个大语言模型(LLMs)如雨后春笋般涌现。
在拥有14亿人口的中国市场,本土科技巨头纷纷亮出了各自的利器:阿里巴巴的"通义千问"、百度的"文心一言"、华为的"盘古"等模型背靠中国庞大且语言文化高度统一的市场,拥有丰富多样的应用场景和海量的用户需求,为其持续优化和发展提供了得天独厚的优势。
在大洋彼岸,美国的科技巨头们同样不甘示弱。OpenAI的ChatGPT继续引领潮流,Meta(原Facebook)推出的开源模型Llama展现出强劲实力,谷歌的Gemini正在快速追赶,而由Anthropic开发、得到亚马逊支持的Claude也异军突起。这些模型依托其母公司或者合作伙伴的全球业务网络,在国际市场拓展方面占据天然优势。
在错失移动互联网浪潮后,拥有7亿多人口的欧洲和1亿左右人口的日本辗转反侧,难以入眠,纷纷喊出要全力支持AI的口号,期待能够通过抓住AI革命来提升国际竞争力。同时,考虑到技术主权、数据安全以及语言和文化的独特性,开发自己的LLMs成为不可避免的选择。那么,它们的进展如何呢?
欧洲想要打造自己的OpenAI,但头部AI初创企业仍依赖美国资本和技术
根据总部位于伦敦的投资集团Roosh在今年6月发布的一份报告,欧洲AI相关的风险投资金额在十年内增长了10倍,超过以往任何一年的融资总额,占欧洲所有风险投资的10%以上。

其中,英国初创公司在2024年筹集了最多的资金,为21亿美元,其次是法国,为12亿美元。
在欧洲LLMs市场中,几家公司脱颖而出,各自以不同的策略和技术特色占据一席之地。
1. 呼声最大,估值最高的LLMs当属Mistral AI。
由前DeepMind 研究员Arthur Mensch,前Facebook AI研究员Timothée Lacroix和Guillaume Lample于2023年在法国巴黎创立,Mistral AI专注于打造更小、更高效的模型从而降低模型使用成本,同时构建一个平台,让企业能够更加方便、安全、低成本地调用模型。

(Mistral AI三位联合创始人。从左到右分别为 Guillaume Lample, Arthur Mensch, Timothée Lacroix)
Mistral AI创始团队可谓是“星光熠熠”。在创业之前,Mensch曾在DeepMind主导了Retro、Flamingo和Chinchilla三个项目,这些是Google在LLM、RAG和多模态领域的里程碑作品;而Lacroix和Lample则在Meta工作期间共同负责了LLaMa大型语言模型的开发。
Mistral AI在7月24日发布了拥有1230亿参数的最新旗舰模型Mistral Large 2(又被称为mistral-large-2407),并声称只用不到Llama-3.1-405b三分之一的参数,实现了更优的代码生成、数学和推理能力。
Mistral Large 2可以理解数10种语言,这比GPT-4o对50多种语言的支持要少。根据LiveBench的评分,Mistral Large 2的总体平均得分为 47.86,低于GPT-4o的 54.63,而Antropic的最新模型 claude-3-5-sonnet-20240620以59.87的得分位居榜首。
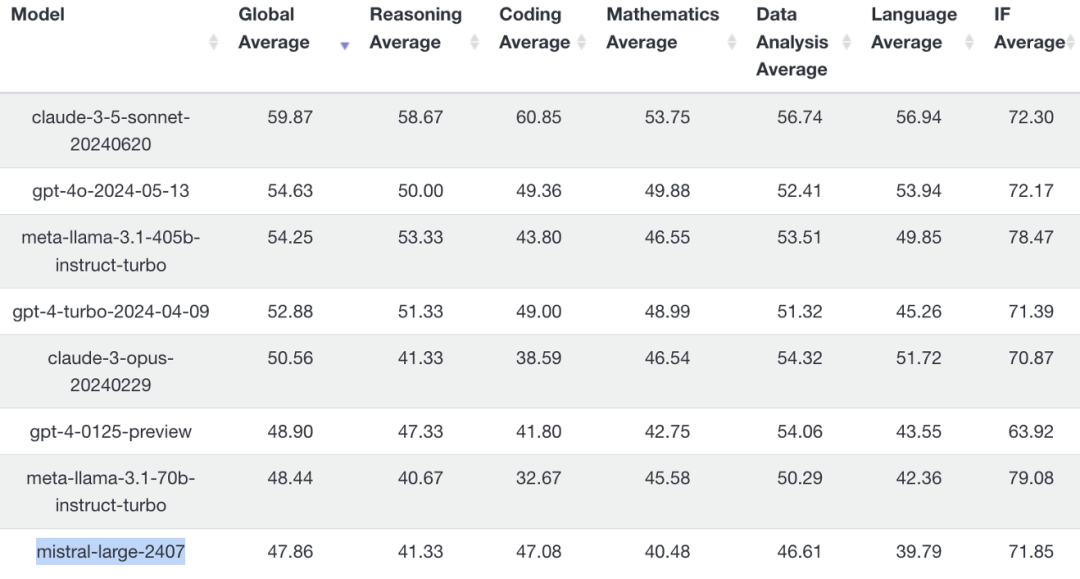
(截图来自LiveBench)
LiveBench是一个每月发布LLM测评结果的平台,基于最新的数据集、arXiv 论文、新闻文章和IMDb 电影简介等资料进行评估。该基准测试涵盖了6个类别中的18项不同任务,为模型的综合表现提供了详尽的分析。
和OpenAI不同,Mistral AI选择了开源路线,考虑到企业私有化使用模型的需求,并且开源模型能力也会逐步升级从而满足更多需求,Arthur在访谈中还提到,开源也能够让模型受到公众监督、更加安全。
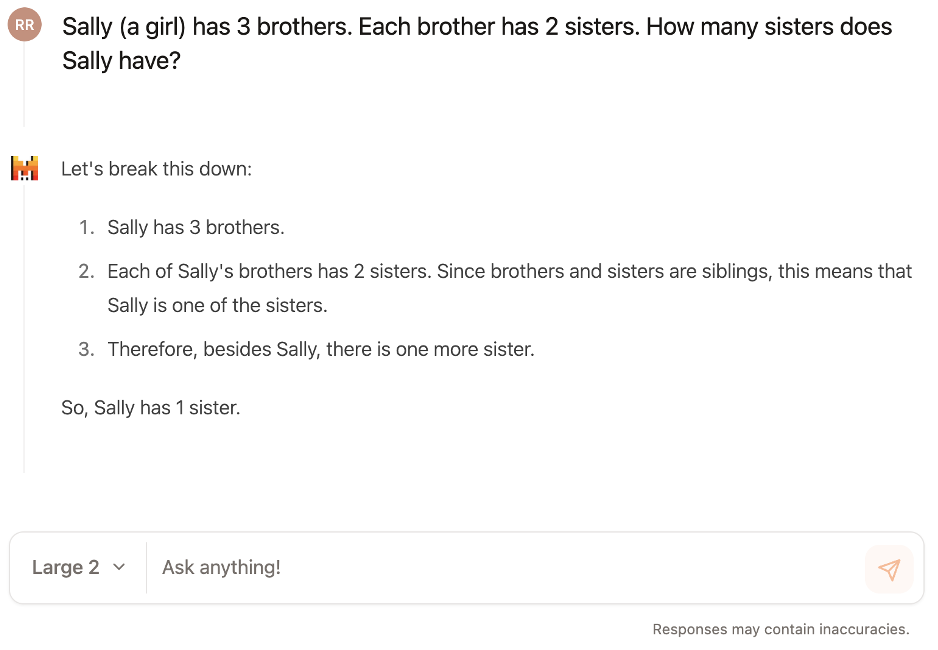
为了更直观的感受Mistral Large2的能力,我们用一道非常经典的,用来考验LLM基本逻辑推理能力的题目,对Mistral Chat进行了一个小测试——“女生Sally有3个兄弟,每个哥哥又有2个姐妹,请问Sally有几个姐妹?”最终,Mistral Chat给出了正确的答案:1个姐妹。
这家总部位于巴黎的AI初创公司,最近在由General Catalyst领投的B轮融资中筹集了6.4亿美元,估值达到60亿美元。
2. 总部位于英国的Stability AI 以Stable Diffusion图像生成模型闻名,同时也在开发StableLM语言模型,采用开源策略和社区驱动的开发模式。
StableLM模型系列包括多个参数规模的模型,最初发布的版本包括30亿和70亿参数模型,未来还计划推出150亿到650亿参数的模型。
今年4月最新发布的Stable LM 2 12B,是一个拥有120亿参数的基础模型,支持英语、西班牙语、德语、意大利语、法语、葡萄牙语和荷兰语七种语言。

Stability AI创始人Emad Mostaque的背景在AI创业公司当中颇为特别。他拥有牛津大学数学和计算机科学学士学位,但没有在任何科技公司工作的经历。在创立Stability AI之前,他主要在英国对冲基金行业工作。2020年,37岁的Mostaque用自己做对冲基金经理的积蓄作为启动资金,在伦敦创立了Stability AI。
随着公司面临逐渐高企的财务挑战和核心技术人员流失的问题,Mostaqu在今年3月选择离开Stability AI,去追逐去中心化AI。在他离职后一个月,资金短缺的Stability AI宣布裁员10%,并对业务规模进行了一定调整。
根据路透社消息,在今年6月,Stability AI筹集了约 8000 万美元的资金,投资者包括 Coatue Management、Lightspeed Venture Partners 和前谷歌首席执行官 Eric Schmidt。此前,Stability AI 在2022年10月完成了1.01亿美元的种子轮融资,估值达到了10亿美元,成为独角兽公司。
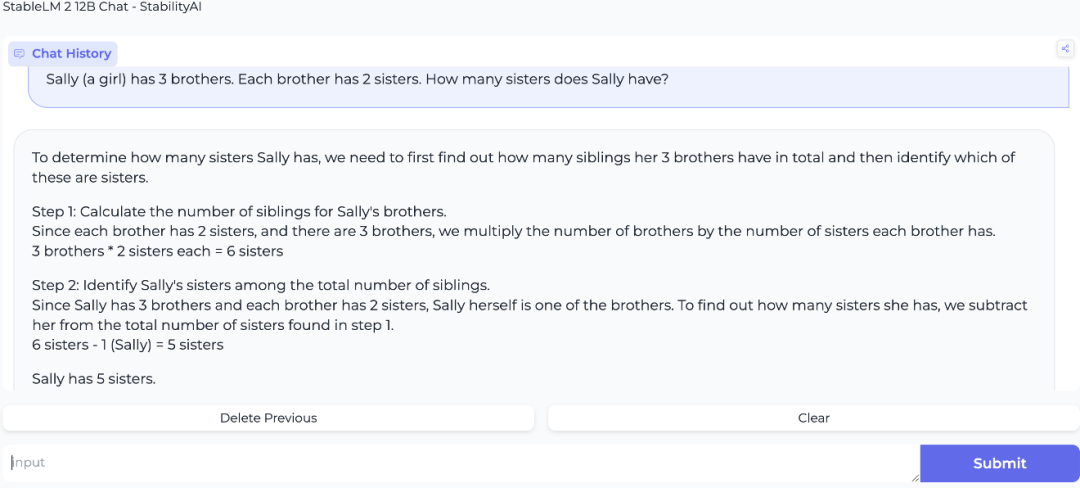
不过在询问Stable LM 2 12B同样的问题之后,我们发现它的推理能力不如Mistral Large 2——它给出了一个错误答案,称Sally有5个姐妹。
3. 谷歌翻译的主要竞争对手—总部位于德国科隆的DeepL—在7月18日推出了自己的第一个LLM。
DeepL是一家始创于2009年的德国科技公司,总部位于科隆。公司最初以在线词典Linguee起家,后在2017年由计算机科学博士Jaroslaw Kutylowski带领团队推出了DeepL Translator。这款翻译工具凭借先进的神经网络技术,提供比多数同类产品更为自然、精确的翻译结果,因此赢得了广大翻译工作者的青睐。
随着来自大型科技公司的竞争压力越来越大——OpenAI、谷歌、Meta等的公司的LLM可以轻松且免费地向用户提供涵盖100多种语言的翻译服务——Kutylowski意识到了投入LLM的重要性。

(财富杂志关于DeepL推出LLMs的报道)
于是DeepL Translator在今年6月推出了第一个基于大型语言模型技术的模型:它完全由 DeepL内部在其自己的基础设施上构建,并且专门为翻译而量身定制。
“DeepL Translator于2017年构思以来,我们一直在研究类似的神经网络,但这种架构的工作方式显然发生了变化,我们首次将其转向LLM技术,”这位首席执行官对媒体说到。
DeepL相信其模型提供了最优质的翻译。该公司表示,在盲测中,语言专家对其下一代模型的偏爱程度是谷歌翻译的1.3倍,ChatGPT-4的1.7倍,微软的2.3倍。
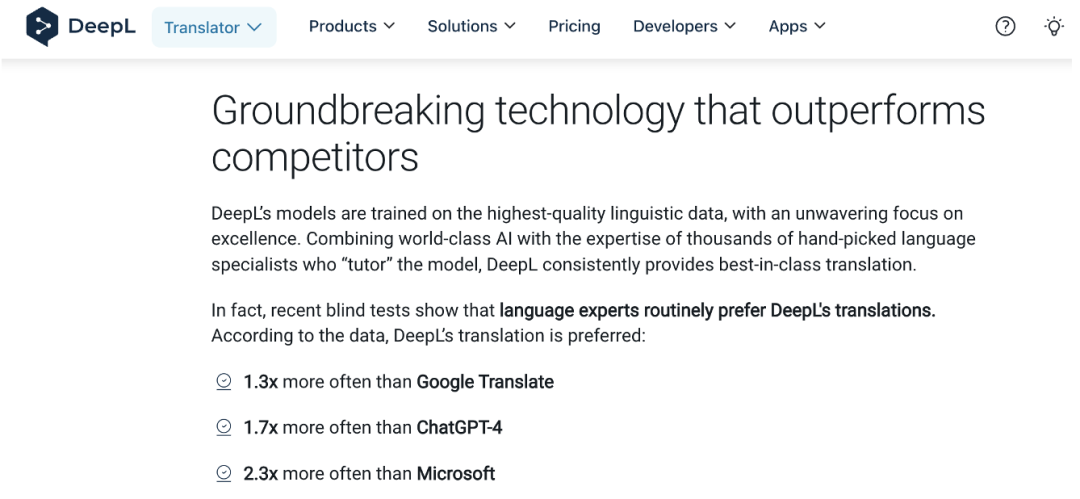
在其自有LLM的帮助下,DeepL还将业务扩展到文档翻译和写作辅助工具,展现了在语言服务领域的广阔应用前景。
2024年5月,DeepL宣布以20亿美元的估值获得3亿美元的投资。本轮融资由Index Ventures领投, IVP、Atomico 等参投。
值得一提的是,利用AI帮助用户提升写作质量和准确性的软件Grammarly,也是一家起源于欧洲的公司,15年前在乌克兰创立,随着公司规模的壮大,总部逐渐搬至旧金山,以更好地获取人才,拓展全球市场以及接触更多的资本。
DeepL和Grammarly的成功,印证了欧洲在语言技术方面的优势。欧洲有24种官方语言和众多的地方语言,这种多语言环境一定程度上推动了对高质量翻译和语言处理工具的需求。
4. Aleph Alpha,号称欧洲人自己的OpenAI。
Aleph Alpha总部也位于德国,由前苹果AI研究员Jonas Andrulis创立。以其Luminous系列模型为核心,这个系列包含多个不同规模和用途的模型:
1)Luminous-base拥有130亿参数,是目前Aleph Alpha最小的模型。因为它的速度最快、成本最低,因此非常适合日常使用。
2)Luminous-extended具有约300亿参数,在信息提取和语言简化等任务上表现优异,同时保持较高的性价比。
3)Luminous-supreme是Luminous系列中规模最大的模型,具有约700亿参数,提供最高精度和性能,适合复杂的语言处理任务。
Aleph Alpha主打“数据主权”的概念,简要来说,就是支持将欧洲的AI模型的数据存储和处理,都位于德国或欧洲地区,而不是美国等其他国家,确保数据的安全性。这一概念当前在欧洲政府以及立法部门受到推崇。
因此,Luminous主要针对那些需要可靠、准确信息的机构,如法律事务所、医疗服务提供商、银行,以及政府和高校等。
目前,Luminous支持德语、法语、西班牙语、意大利语以及英语,其训练数据中包含有大量由欧洲议会发布的多语种公共文件。
去年11月,Aleph Alpha 从博世、SAP 和惠普支持的 B 轮融资中筹集了 5 亿美元。
从LLMs的创新来看,德国确实走在欧洲的前沿。除了DeepL和Aleph Alpha之外,德国AI研究中心(DFKI)和黑森AI中心(hessian.AI)的研究人员还发起了一个名为Occiglot的开源计划。
该计划旨在开发针对欧洲语言的生成语言模型,涵盖欧盟所有24种官方语言以及多种非官方和地区语言。目前,Occiglot在Hugging Face平台上以Apache 2.0许可协议提供使用。
目前DeepL的LLM、Aleph Alpha的Luminous以及Occiglot未向普通用户开放使用,因此我们暂时无法对它们的表现进行一个最简单、基本的测评。
5.在全球AI竞赛中,欧洲正谋求一次战略性的“弯道超车”。
通过启动GenAI4EU计划,欧盟希望促进AI初创企业与行业部署者之间的合作,充分利用欧洲的超级计算基础设施,开发出值得信赖的AI模型。
这些努力不仅是欧洲在数字经济新格局中重新定位自己的战略性尝试,也反映了其对错失移动互联网发展良机的深刻反思。
回溯历史,欧洲曾凭借诺基亚、爱立信等科技巨头,在移动通信领域独领风骚。然而,随着智能手机时代的到来,欧洲逐渐失去了话语权,让美国公司凭借强大的软件生态系统占据了制高点。这一教训深深刺痛了欧洲决策层,也成为其在AI时代奋起直追的重要动因。
然而,欧洲的AI战略面临着一个微妙的平衡难题:如何在严格监管与鼓励创新之间找到最佳平衡点?
一向走在技术监管前沿的欧洲,在2024年3月通过了世界上第一个全面的AI监管框架——《人工智能法案》(Artificial Intelligence Act),适用于在欧盟开展业务或产生影响的任何组织。这意味着科技巨头在欧盟市场的业务以及对欧盟公民数据的使用受到更严格的审查。
出于监管方面的考虑,Meta已经限制了Llama模型在欧洲的可用性。此前,这家美国社交网络巨头还被勒令停止在欧盟使用Facebook和Instagram的帖子训练其模型,原因是担心这可能违反了GDPR(《通用数据保护条例》)。
监管的介入诚然可以更好地保障普通用户的利益,但也在一定程度上给创新带来了掣肘,尤其是对于一个还处在发展初期的技术。在这场没有先例可循的尝试中,欧洲需要展现出前所未有的战略智慧和政策灵活性。如果成功,欧洲将为全球AI治理提供一个兼顾创新与伦理的范本;如果失败,则可能重蹈移动互联网时代的覆辙,进一步拉大与全球科技强国的差距。
值得一提的是,尽管Mistral AI被视为欧洲AI领域的“领跑者”,但其背后的资本结构和人才构成却与美国密切相关。
Mistral AI的主要投资者来自多家美国知名投资公司,包括Andreessen Horowitz (a16z)、General Catalyst、Lightspeed Venture Partners、NVIDIA和Salesforce Ventures等。虽然也有如法国电信巨头Xavier Niel等欧洲投资者的参与,但美国资本在其投资中占据了明显的主导地位。
另一方面,创始团队虽然扎根法国,但他们大多有在美国科技巨头工作的经历:除了几位联合创始人分别在Google旗下的DeepMind和Meta从事AI研究工作,还有不少团队成员曾在美国顶级科技公司工作过。这也使得Mistral尽管根植于欧洲,但企业文化明显受到硅谷创业精神的影响。
最后,我们再用一张图表来加深对欧洲LLMs的主要参与者的印象。
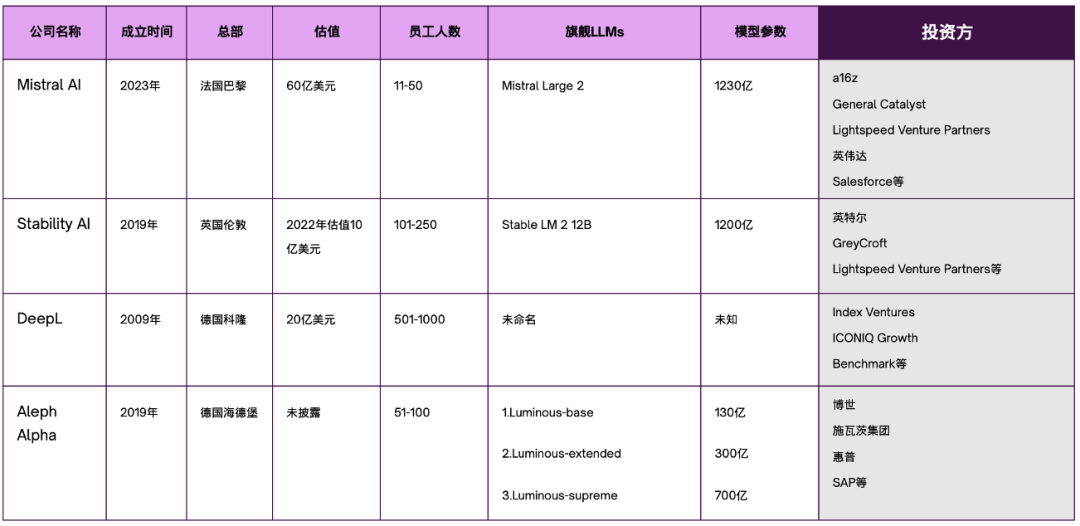
(制图:数据猿)
日本LLM发展主要建立在现有模型之上,而非从零开始搭建
1. 在日本AI领域,拥有“钞能力”的软银(SoftBank)无疑是最重要的参与者之一。
考虑到当前日语AI数据集的开发相对滞后,这家市值接近千亿美元的科技巨头决定投资9.6亿美元开发自主AI模型,目标是在2024年完成一个具有3500亿参数的本土化大型语言模型(LLM)。
为达成目标,软银于2023年8月1日成立了SB Intuitions,这是一个专注于研发能够适应日本商业习惯和文化需求的GenAI服务的部门。
截至目前,软银推出了两款基于不同架构的LLM:基于GPT-NeoX的Sarashina1和基于Llama的Sarashina2,它们的最大上下文长度分别为2048和4096个token。作为参考,ChatGPT-3和ChatGPT-4的上下文长度分别为4096和8192个token,这意味着Sarashina2支持的上下文长度与ChatGPT-3相当。

(软银的LLM Sarashina)
软银还计划与各方合作,建立一个生态系统来加速日本在GenAI领域的发展。作为这个策略的一部分,公司已经建设了一个顶级的计算平台,包括一台NVIDIA DGX SuperPOD™ AI超级计算机和2,000多个NVIDIA Tensor Core GPU。该平台于2023年10月正式启用,并将向大学、研究机构和企业提供必要的计算资源。
作为旗下涵盖了电信服务、金融科技和机器人等多个产业的巨头,软银已经开始利用LLM提升服务效率、优化客户体验和推动业务创新。例如,公司已经部署了由LLM驱动的AI聊天机器人和虚拟助手,以实现24小时客户支持;同时,通过LLM设计个性化营销活动,以及预测市场趋势、客户需求和潜在风险。
为了充分利用AI技术的潜力,软银除了自研LLM外,还与微软建立了战略联盟,为使用微软AI服务的日本企业提供安全的数据环境。公司还计划建立一个由多个GenAI系统组成的平台,从OpenAI、微软、谷歌等公司开发的多个模型中挑选最适合客户需求的模型。

(孙正义)
软银,尤其是创始人孙正义,对AI的投资展现出极大的乐观态度。据《华尔街日报》2023年7月的报道,愿景基金——由软银发起的全球顶尖私募股权基金——在过去几年中已投资了1400亿美元于400个AI相关项目。
2. 被誉为“日本亚马逊”的Rakuten 推出了一套高性能开源日语LLM— RakutenAI-7B。
(Rakuten的电商返现业务页面)
这个拥有70亿参数的基础模型是在乐天的GPU集群上,通过持续训练Mistral AI的开源模型Mistral-7B-v0.1而开发而成。RakutenAI-7B巧妙地重用了预训练模型的权重,在日语理解方面的相关基准测试中更是拔得头筹。
为了提升日语分词的准确性,开发团队将Mistral的词汇量从32k扩展到了48k,这一改进使得模型能用更少的token传递更多信息。乐天的目标是提供一个经济高效的日语模型,以适应各种应用场景。值得一提的是,该模型采用Apache 2.0许可证发布,任何人都可以免费访问和使用。
此外,乐天还基于指令微调技术开发了RakutenAI-7B-instruct和RakutenAI-7B-chat两个变体,进一步提升了模型遵循指令和生成自然对话的能力。
作为一家业务横跨电子商务、金融科技、数字内容和电信等多个领域的跨国公司,乐天能够将AI融入其运营中,以推动增长并创造价值。
3. 对于大部分人来说,CyberAgent这个名字有些陌生,但它却是日本本土LLM的主要建设者,没有之一。
创立于1998 年,CyberAgent 的业务主要集中在流媒体服务、数字营销和在线广告等方面。
这家老牌科技公司先后推出了基于GPT-NeoX的OpenCALM,以及基于Llama的CyberAgentLM2 (CALM2)和CyberAgentLM3 (CALM3)。其中,CALM3表现最为出色,支持高达16384个token的上下文长度,大大拓展了模型的应用范围。

(CyberAgent的官网)
除了自主研发,CyberAgent还积极与东京工业大学、东北大学、名古屋大学等高校以及富士通等企业合作,利用日本超级计算机“富岳”(Fugaku)共同训练出Fugaku-LLM。
该模型在3800亿个token上进行训练,其中约60%的数据是日语,因此,无论是处理敬语(keigo)还是生成自然对话,Fugaku-LLM都展现出不错的性能。此外,Fugaku-LLM拥有130亿个参数,远超大多数通常只拥有不超过70亿个参数的日本本土LLMs。
日本东京国立信息研究所 (NII) 还发起了LLM-jp, 一个专注于大规模日语 LLM 的研究和开发的项目。来自学术界、工业界和研究机构等各个领域 1500 多名参与者的共同合作下,LLM-jp推出了基于GPT的开源旗舰模型LLM-jp-13B。
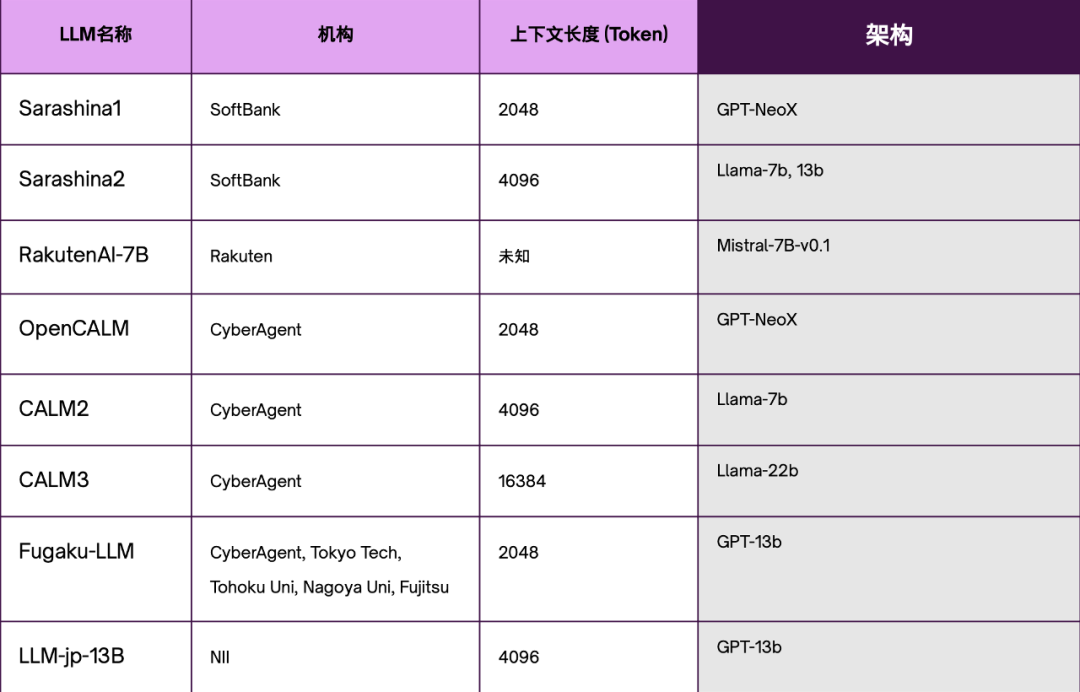
(日本主要LLM概览。制图:数据猿)
基于以上信息,不难发现日本LLM发展主要基于对现有模型的优化而非从零开始。
这种策略不仅能够大幅缩减训练时间和计算资源需求,更重要的是,它让日本得以将有限的人才库和精力聚焦于有独特价值的领域——日语优化和文化适应。
更值得关注的是,日本在LLM发展中展现出的开放态度:RakutenAI-7B, LLM-jp, Fuguku-LLM 等项目都选择了开源,以期促进日本AI生态系统的发展。这种开放共享的精神,与日本传统的相对保守的企业文化形成了有趣的反差。
产学研的紧密结合,更是日本AI发展的一大亮点。LLM-jp项目获得日本国立信息研究所的鼎力支持,Fugaku-LLM项目充分利用国家级超级计算机资源,这些或多或少彰显了日本的政策制定者们在AI领域决心。
纵观日本的LLM发展策略,更多的是对“务实”和“本土化”的考量。然而,这种策略也使得相较于全球AI巨头,日本本土模型在规模和通用性上还有不小差距,限制其在全球舞台上的竞争力。但毋庸置疑的是,本土模型能够更好的服务日本企业和社会,带来实实在在的价值。
从监管角度来看,日本对GenAI采取了相对宽松的立场,尤其是在版权方面。允许AI模型处理任何数据进行训练,不论其版权状态如何,也不分商业或非营利用途。这一政策立场旨在加速日本在GenAI领域的进步,但政府也承认,随着技术及其影响的演变,可能会对这一立场进行调整。
进入GenAI时代,大一统的市场具有明显的优势,未来竞争仍聚焦在中美身上
LLMs已经成为参与GenAI技术革命的门票。但我们不得不直面一个现实:这也是一场规模经济的游戏,其"赢家通吃"的特征可能比移动互联网时代更为显著。对于规模相对较小的日本市场和高度分散的欧洲市场,这种局面尤其具有挑战性。
在LLMs的全球竞争中,大一统的市场具有明显的优势,主要体现在数据获取、计算资源汇聚、人才集中和成熟的应用生态系统等方面。
具有语言统一性、庞大人口规模和一致政策的市场,不仅能提供更丰富多样的训练数据,还能开拓更广阔的应用场景和吸引更多用户,这对于模型的持续改进和商业化至关重要。
另一方面,近期华尔街对AI的态度也在悄然转变,从单纯关注企业在AI技术上的投入,转向评估这些投资的实际盈利能力。
(关于华尔街重新审视企业对AI投资的相关报道截图)
在这样的市场环境中,对于多数机构来说,自主开发LLMs可能相当于“重新造轮子”,不仅成本高昂,其商业成功的可能性也令人担忧。
尽管面临这些挑战,小国家和碎片化市场可以在本地化和文化适应性方面寻找突破。通过构建专注于当地语言和文化需求的模型,它们可以更有效地服务于特定的市场需求。此外,与国际大型企业的合作也是一个行之有效的策略。通过这种合作方式,较小市场可以利用大型企业的技术力量和资源,同时保持对本地数据和隐私的控制。
可以预见的是,在国际舞台上,未来在GenAI领域的竞争预计仍会聚焦在中美身上。
文:王茜茜 / 数据猿
责编:凝视深空 / 数据猿