从更新语句中看日志系统
探究技术的本质,享受技术的乐趣!由于时间原因以及自己的原因导致拖更了,不过没关系,我保证后面每天一更,周末休息!好了,闲话少说,今天我们通过一个更新操作去认识一下Mysql的日志系统
首先我们先来看看我们的表结构以及更新语句的执行计划
# 准备工作
CREATE TABLE user_info (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(32) NOT NULL,
age TINYINT NOT NULL
);
insert into user_info (name,age) values ('pandaer',20)
# 更新语句
update user_info set age = age + 1 where id = 1准备工作完成之后,我们先来回顾一下Mysql的架构设计,在Server端,一条SQL的语句的执行流程是这样的,SQL语句从连接器到达解析器,解析器进行一定的语法分析与语义分析知道了这条SQL是干什么的,然后优化器进行优化处理,并知道了为了执行这条SQL,应该怎么一步一步来做,将这些步骤组合成一个执行计划,并把这个执行计划交给执行器来做,执行器将具体的需要和磁盘打交道的操作委派给了存储引擎。这就是一条SQL的大致执行流程。更新语句的执行流程类似,只不过在执行过程中还会涉及到两个日志,一个是redo log 一个是bin log, 具体的过程是这样的:当SQL语句流转到执行器的时候,也就是SQL语句变成了一步一步的执行计划,SQL通过id的主键索引,利用范围查找,找到id=1的记录,并更新这条记录的age字段的值。执行计划如下
mysql> explain UPDATE user_info SET age = age + 1 WHERE id = 1;
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | UPDATE | user_info | NULL | range | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)就这么简单的过程就涉及到了 redo log,以及bin log,首先我们需要明确redo log和bin log的作用,redo log又叫重做日志,在存储引擎层,也就是并不是全部的存储引擎都有重做日志,目前只有InnoDB有重做日志,它的作用是缓解IO压力,提升系统性能。拿上面那个例子举例,当执行器将内存中的id=1的记录的age值从20改为21之后,就会调用InnoDB的相关的接口,将数据写入磁盘。但是这个写入过程并没有我们想象的那么简单,第一步我们需要找到这条记录在磁盘的位置,然后再写入。而如果记录很多,那么这个查找过程就有点慢了,如果同时又有很多请求来到数据库,那么数据库的压力就会很大,为了解决这个问题,InnoDB给出了重做日志的解决方案,这里需要补充一个知识,追加写的方式IO性能最好。所以当执行器调用存储引擎的写接口的时候,InnoDB只不过是记录了一条日志,即磁盘中的那一块数据发生了改变。当这个日志写入到重做日志之后,就会给执行器返回OK。即写操作完成。然后等到数据库压力不大的时候,在利用这个重做日志去更新真实的数据记录。接着我们再来说说bin log, bin log也叫归档日志,是Server层来支持的,这就意味着与存储引擎无关。归档日志的作用就是用来做备份以及主从同步的。为了实现这个目的,归档日志不得不在每条SQL语句执行完成之后,记录一下。那么就产生了一个问题,归档日志和重做日志的一致性问题。就比如当写完重做日志之后,Mysql崩溃了,那么归档日志和重做日志中的内容就不一致,这样就会导致,主从同步的时候,从节点的数据与主节点的数据不一致问题。为了解决这个问题,Mysql提出来两阶段提交的方式来解决。大致的逻辑是这样的:当执行器委派InnoDB执行写操作的时候,InnoDB记录一条日志到重做日志中后,将状态设置为prepare,然后执行器写完归档日志之后,InnoDB就会将状态设置为commit,利用这种两阶段提交的方式解决了一致性的问题。那么你肯定会问为什么呢?我们不妨分析一下这样做了之后,由几个时间点可能发生崩溃,可以看下方的图
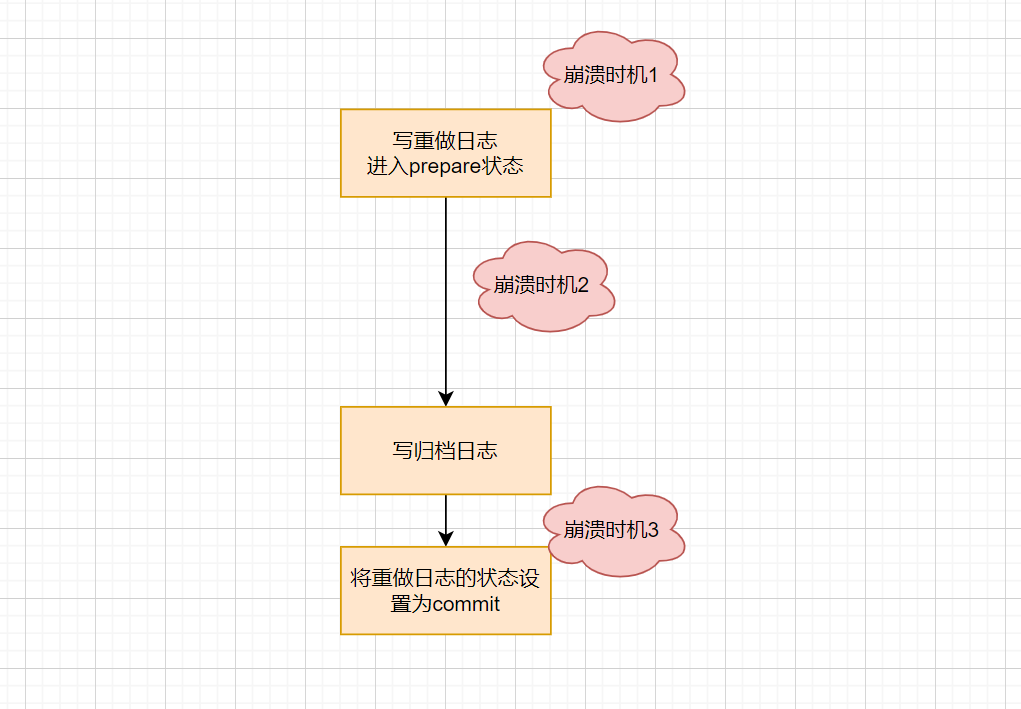
- 崩溃时机1,很简单,都没有写入不存在一致性问题
- 崩溃时机2,重做日志中有记录,但是归档日志中没有记录,由于标记重做日志为prepare状态,所以在故障恢复的时候就知道存在问题,然后就可以根据归档日志中是否存在这条记录来判断是回滚还是直接设置为commit状态
- 崩溃时机3,和时机2一致。