该论文提出了一种可控的视频生成框架MimicMotion,能够生成高质量且任意长度的视频,模仿特定的运动指导。该研究引入信心感知姿势指导,确保视频帧的高质量和时间平滑性。同时,还引入了基于姿势信心的区域性损失放大策略,显著减少了图像失真。此外,为了生成长而平滑的视频,该研究还提出了一种渐进式潜在融合策略。总的来说,该研究在视频生成方面取得了显著的改进和突破。
地址:https://arxiv.org/pdf/2406.19680
代码:https://tencent.github.io/MimicMotion

MimicMotion框架介绍
MimicMotion是一个创新的视频生成框架,专注于通过模仿特定的动作引导来生成任意长度的高质量视频。与以往的方法相比,MimicMotion具有几个显著的特点。首先,它引入了置信感知的姿态引导,确保了高帧质量和时间平滑性。其次,基于姿态置信度的区域损失放大显著减少了图像失真。最后,为了生成长时间和平滑的视频,我们提出了一种渐进式潜在融合策略。通过这种方法,我们可以在可接受的资源消耗下生成任意长度的视频。
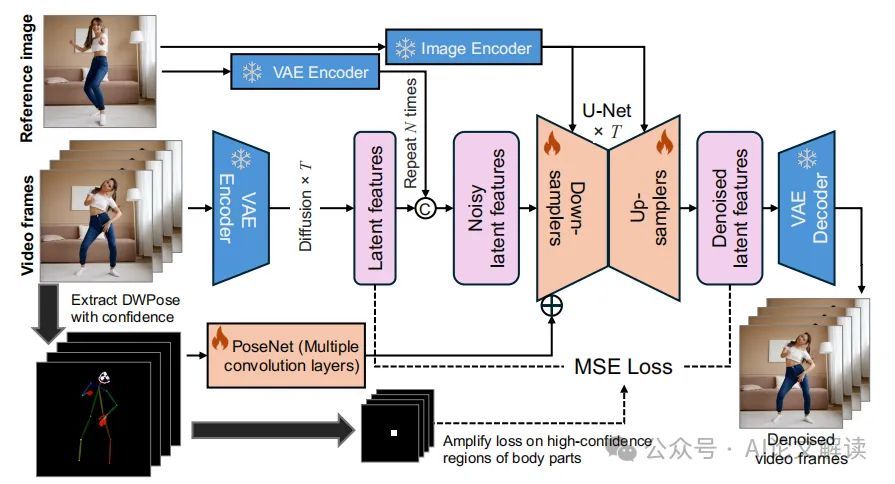
MimicMotion利用置信感知的姿态引导和图像参考来生成视频。这种方法不仅包含丰富的图像细节,而且还遵循参考图像和姿态引导。通过引入置信度的概念到姿态序列表示中,可以实现更好的时间平滑性,并且也可以缓解图像失真。此外,我们提出了一种用于实现长时间但仍然平滑视频生成的渐进式潜在融合方法。通过生成具有重叠帧的视频片段,我们的模型可以处理任意长度的姿态序列引导。通过合并生成的视频片段,最终的长视频同时可以具有良好的跨帧平滑性和图像丰富性。
置信感知姿态引导的重要性
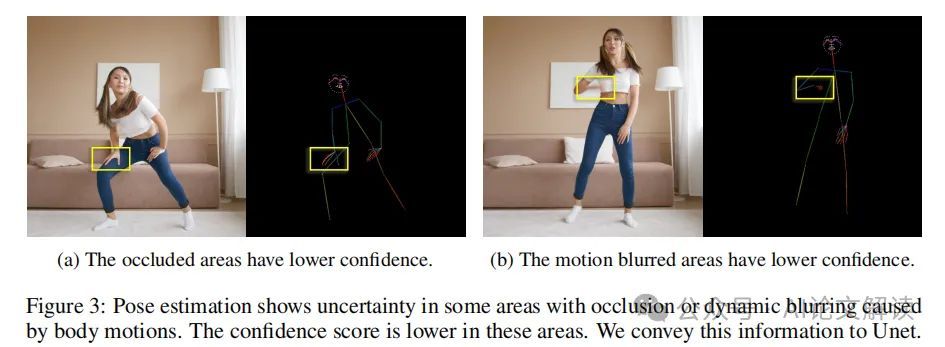
在动态视频中,从图像中准确估计姿态是一项挑战。动态外观和运动的固有不确定性使得姿态估计充满挑战。不准确的姿态引导信号可能会误导模型,导致生成不准确或扭曲的输出。此外,嘈杂的姿态引导信号可能导致在包含不正确姿态的样本上过拟合,可能导致训练不稳定。这反过来可能会阻碍模型从扩展的训练时间表中受益。
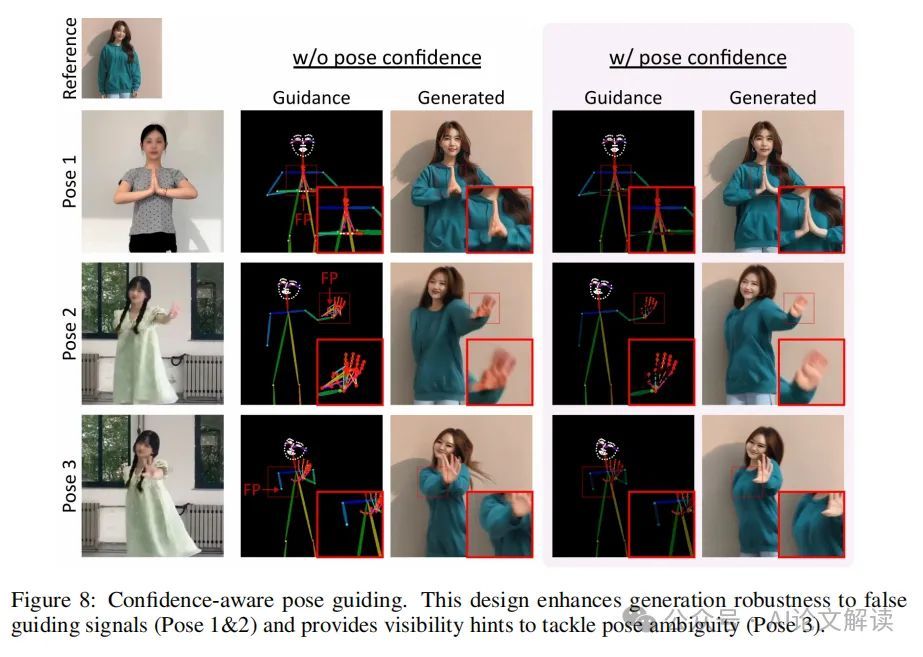
为了解决这个问题,我们提出了置信感知姿态引导,利用姿态估计模型与每个关键点相关联的置信分数。这些分数反映了准确检测的可能性,数值较高表示可见性高、遮挡少和运动模糊少。我们使用亮度在姿态引导帧上表示姿态估计的置信水平。具体来说,我们将分配给每个关键点和肢体的颜色乘以其置信分数。因此,置信分数较高的关键点和相应的肢体在姿态引导图上会显得更加突出。这种方法使模型在其引导中优先考虑更可靠的姿态信息,从而提高了姿态引导生成的整体准确性。
此外,我们还利用姿态估计和相关的置信分数来缓解特定区域的伪影,例如手部扭曲,这在基于扩散的图像和视频生成模型中很常见。通过设置阈值,我们可以区分出置信度高的关键点和由于遮挡或运动模糊可能不准确的关键点。超过阈值的关键点被认为是可靠的。我们实施了一种掩码策略,根据置信阈值生成掩码。我们取消掩码那些置信分数超过预定义阈值的区域,从而识别出可靠的区域。在计算视频扩散模型的损失时,未掩蔽区域的损失值会被放大一定的比例,从而在模型训练中比其他掩蔽区域产生更大的影响。
长视频生成技术
在视频生成领域,尽管已有多种技术尝试解决长视频生成的问题,但大多数现有方法仍然面临着视频质量下降和时间连贯性缺失的挑战。为了克服这些限制,我们提出了一种新的长视频生成框架,名为MimicMotion,它采用了置信度感知的姿态引导和渐进式潜在融合策略,以生成高质量的长视频。
1. 置信度感知的姿态引导
在传统的视频生成方法中,姿态估计的不准确性常常导致生成的视频质量不佳。为了解决这一问题,我们引入了置信度感知的姿态引导。通过将姿态估计模型(如DWPose)生成的关键点置信度分数整合到姿态表示中,我们的模型能够根据置信度分数动态调整姿态引导的影响力。这种方法不仅减少了由于姿态估计不准确而引起的视频质量问题,还通过强化高置信度区域(如手部区域)的训练损失,显著提高了手部等细节的生成质量。
2. 渐进式潜在融合
为了生成长视频,我们采用了一种名为渐进式潜在融合的策略。这种方法首先将视频分割成多个时间段,每个时间段包含一定数量的帧,并在相邻时间段之间设置重叠的帧。在生成过程中,我们分别对每个时间段的潜在特征进行去噪,然后通过渐进式融合这些特征,以确保时间段之间的平滑过渡。这种策略有效地减少了视频段之间的突变和闪烁,从而提高了视频的整体时间连贯性。

通过这两种技术的结合,MimicMotion能够生成既长又平滑的高质量视频,显著优于现有的视频生成方法。
实验设计与数据准备
为了训练和验证我们的MimicMotion模型,我们进行了详尽的实验设计和数据准备工作。
1. 数据收集与预处理
我们首先收集了多种包含人类动作的视频数据集,这些视频涵盖了从简单的日常动作到复杂的舞蹈动作。每个视频都被分割成帧,并进行了大小调整和裁剪以符合模型输入的要求。对于每个视频帧,我们使用DWPose模型提取姿态信息,并将这些信息与相应的视频帧一起作为模型的输入。
2. 模型训练
在模型训练阶段,我们利用预训练的图像到视频的扩散模型作为基础,通过在此基础上增加置信度感知的姿态引导和渐进式潜在融合技术,来训练我们的MimicMotion模型。训练过程中,我们特别关注于优化模型对于长视频生成的能力,以及在生成过程中保持高质量和时间连贯性。
通过这样的实验设计和数据准备,我们的MimicMotion模型不仅能够生成视觉上吸引人的长视频,还能确保视频内容的动态连贯性和细节的丰富性,满足实际应用中对长视频生成的需求。
性能评估与比较
1. 性能评估
MimicMotion的性能评估主要通过与现有的最先进方法进行比较来完成。这些方法包括MagicPose、Moore-AnymateAnyone和MuseV。通过在TikTok数据集的特定序列上进行测试,我们能够进行定性和定量的比较。定性评估显示,我们的方法在单帧质量和时间平滑性方面均优于其他方法。特别是在手部生成质量和对参考姿势的精确遵循方面,MimicMotion展示了显著的改进。
定量评估使用FID-VID和FVD指标进行,结果显示MimicMotion在这两个指标上均优于其他所有方法。这些结果不仅证明了我们方法的有效性,也显示了在处理动态视频生成时,对姿势估计的准确性和时间连贯性的改进。


2. 用户研究与市场反馈
为了进一步验证MimicMotion的实用性和用户接受度,我们进行了用户研究。这项研究涉及向参与者展示由我们的方法生成的视频与其他基线方法生成的视频。参与者需要选择他们认为质量更高的视频,考虑因素包括图像质量、闪烁和角色及服装的时间平滑性。
研究结果表明,绝大多数参与者更喜欢我们的方法生成的视频。尽管MuseV在图像质量方面表现较好,但在视频生成的总体偏好中,我们的方法仍然达到了75.5%的偏好率。这些反馈强化了我们的定性和定量评估结果,证明了MimicMotion在高质量人类视频生成方面的有效性。
通过这些综合评估,MimicMotion证明了其在动态视频生成领域的领先地位,特别是在处理长视频和复杂动作时的能力。

挑战与未来方向
1. 挑战
尽管人工智能在图像生成领域取得了显著进展,视频生成仍面临诸多挑战。首先,视频生成需要高质量的图像和无缝的时间平滑性,这对技术提出了更高的要求。其次,控制生成内容并扩展到较长的长度而不影响质量,对于实际应用至关重要。此外,由于计算限制和模型能力,生成包含大量帧的高质量长视频仍然是一个重大挑战。
2. 未来方向
为了解决这些问题,我们提出了一系列方法,包括信心感知的姿势引导和渐进式潜在融合策略。这些方法不仅可以提高帧的质量和时间平滑性,还可以在接受的资源消耗下生成任意长度的视频。此外,我们的方法基于一般预训练的视频生成模型,这减少了模型训练的成本,并且不需要大量的训练数据或特殊的手动注释。
总结
本研究引入了MimicMotion,一个以姿势引导的人体视频生成模型,该模型利用信心感知的姿势引导和渐进式潜在融合策略,生成高质量的长视频。通过广泛的实验和消融研究,我们展示了我们的模型在适应噪声姿势估计、提高手部质量和确保时间平滑性方面的优越性。信心分数的整合到姿势引导中、手部区域损失的增强以及渐进式潜在融合的实施,是实现这些改进的关键,结果是更具视觉吸引力和现实感的人体视频生成。