一.随机森林
1.1随机森林的构建
bootstrap参数代表的是bootstrap sample,也就是“有放回抽样”的意思,指每次从样本空间中可以重复抽取同一个样本(因为样本在第一次被抽取之后又被放回去了)
假设,原始样本是”苹果,”西瓜,”香蕉,桃子],那么经过bootstrap sample 重构的样本就可能是[西瓜,”西瓜,香蕉”,桃子],还有可能是['苹果,西瓜,桃子’,桃子],bootstrap sample生成的数据集和原始数据集在数据量上是完全一样的,但由于进行了重复采样,因此其中有一些数据点会丢失。
1.2 红酒数据集之随机森林
1.使用红酒数据集:
from sklearn.datasets import load_wine
wine = load_wine()
X=wine.data
y=wine.target
2.随机森林
from sklearn.model_selection import train_test_split
3.切分数据集:测试集30%
X_train, X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
4.随机森林
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=25, random_state=3)
5.模型训练及评估
model.fit(X_train,y_train)
print('Trainscore:%f'%(model.score(X_train, y_train) ) )
print('Test score:%f '%(model.score(X_test,y_test) ) )
运行结果如下:

6.增加归一化:
按列归一化,使用 zero-score 零均值归一化算法
wine_X = X.copy()
for i in range(X.shape[1]):
column_X = X[:, i]
wine_X[:, i] = (column_X - column_X.mean())/column_X.std()
运行结果:
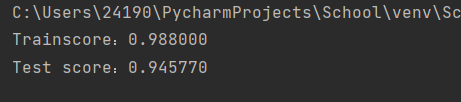
发现结果一样,说明随机森林,数据的归一化对其影响不大。
1.3加利福尼亚的房价数据之随机森林
1.加利福尼亚的房价数据:
from sklearn.datasets import fetch_california_housing
import pandas as pd
housing = fetch_california_housing()
X = housing.data
y = housing.target
df=pd.DataFrame()
for i in range(8):
df[housing["feature_names"][i]]=X[:,i]
df["target"]=y
df.to_csv("fetch_california_housing.csv",index=None)
pd.set_option('display.max_column', None)
df.describe()
2.进行数据归一化
wine_X = X.copy()
for i in range(X.shape[1]):
column_X = X[:, i]
wine_X[:, i] = (column_X - column_X.mean())/column_X.std()
3.随机森林
from sklearn.model_selection import train_test_split
4.切分数据集:测试集30%
X_train, X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
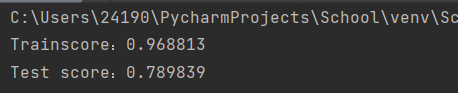
5.模型训练及评估
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=25, random_state=3)
model.fit(X_train,y_train)
print('Trainscore:%f'%(model.score(X_train, y_train) ) )
print('Test score:%f '%(model.score(X_test,y_test) ) )
运行结果如下:
1.4为什么要生成bootstrap sample数据集?
这是因为通过重新生成数据集,可以让随机森林中的每一棵决策树在构建的时候,会彼此之间有些差异。再加上每棵树的节点都会去选择不同的样本特征,经过这两步动作之后,可以完全肯定随机森林中的每棵树都不一样。
1.5 bootstrap sample数据集
模型会基于新数据集建立一棵决策树,在随机森林当中,算法不会让每棵决策树都生成最佳的节点,而是会在每个节点上随机地选择一些样本特征,然后让其中之一有最好的拟合表现。可以用max_features这个参数来控制所选择的特征数量最大值的,在不进行指定的情况下,随机森林默认自动选择最大特征数量。
假如把max_features设置为样本全部的特征数n_features就意味着模型会在全部特征中进行筛选,这样在特征选择这一步,就没有随机性可言了。而如果把max_features的值设为1,就意味着模型在数据特征上完全没有选择的余地,只能去寻找这1个被随机选出来的特征向量的阈值了。
max_eatures的取值越高,随机森林里的每一棵决策树就会“长得更像”,它们因为有更多的不同特征可以选择,也就会更容易拟合数据;反之,如果max_features取值越低,就会迫使每棵决策树的样子更加不同,而且因为特征太少,决策树们不得不制造更多节点来拟合数据。
n_estimators这个参数控制的是随机森林中决策树的数量。在随机森林构建完成之后,每棵决策树都会单独进行预测。如果是用来进行回归分析的话,随机森林会把所有决策树预测的值取平均数;如果是用来进行分类的话,在森林内部会进行-“投票“-,每棵树预测出数据类别的概率,比如其中一棵树说,“这瓶酒80%属于class_l",另外一棵树说“这瓶酒60%属于class_2",随机森林会把这些概率取平均值,然后把样本放入概率最高的分类当中。
对于超大数据集来说,随机森林会比较耗时,不过我们可以用多进程并行处理的方式来解决这个问题。实现方式是调节随机森林的njobs 参数,记得把njobs参数数值设为和CPU内核数一致,比如你的CPU内核数是2,那么njobs参数设为3或者更大是没有意义的。当然如果你搞不清楚自己的CPU到底就多少内核,可以设置njobs=-1,这样随机森林会使用CPU的全部内核,速度就会极大提升了。
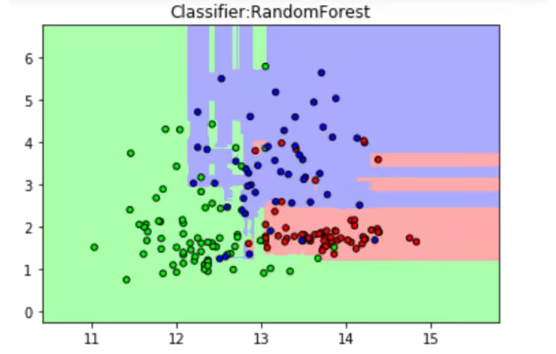
可以发现随机森林所进行的分类要更加细腻一些,对训练数据集的拟合更好。可以自己试试调节n_estimator参数和random_state参数,看看分类器的表现会有怎样的变化。
1.6 随机森林的优势和不足
在机器学习领域,无论是分类还是回归,随机森林都是应用最广泛的算法之一
- 优势
1.不需要过于在意参数的调节
2.不要求对数据进行预处理
3.集成了决策树的所有优点,而且能够弥补决策树的不足
4.支持并行处理
- 不足
1.对于超高维数据集、稀疏数据集等,随机森林模型拟合优度不佳,线性模型要比随机森林的表现更好一些
2.随机森林相对更消耗内存,速度也比线性模型要慢
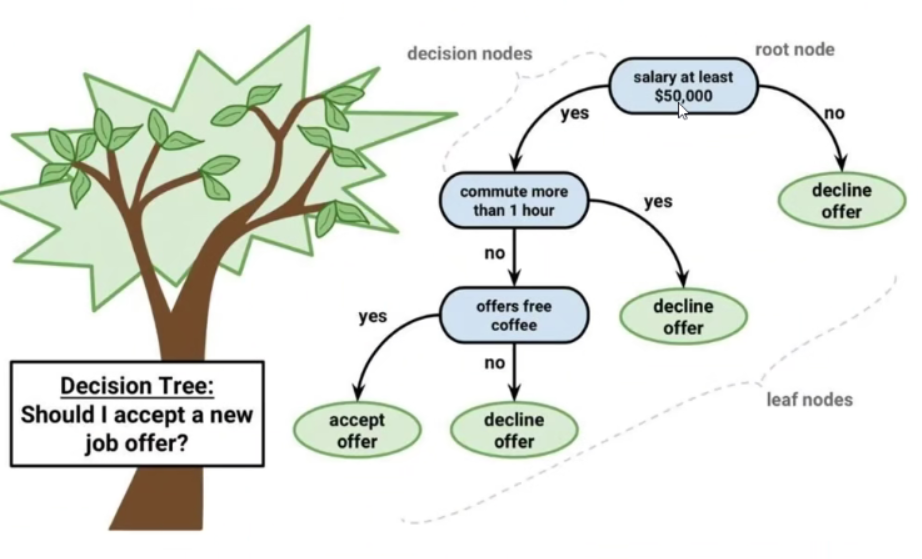
1.7 决策树







![[附源码]java毕业设计社区私家车位共享收费系统](https://img-blog.csdnimg.cn/3749061253ee49b3bbe1aaa680686c40.png)