问题现象
客户将一个100G的表的数据插入到另一个表中,使用insert into select插入数据。从第一天下午2点开始执行,到第二天上午10点,一直未执行完毕。
由于需要实施下一步操作,客户kill重启了数据库,之后数据库一直回滚中,导致后续执行其他操作都报错YAS-02016 no free undo blocks
问题单:大sql的undo回滚导致任何操作都无法执行,需要优化
问题的风险及影响
客户环境为准生产环境,影响业务执行。
问题影响的版本
YashanDB版本:22.2.11.100
问题发生原因
1、UNDO没有做调整,最大为64GB,insert单个表超过100GB,UNDO空间不足导致卡死。
2、由于kill导致重启对insert into select 做回退,rollback过程不能做truncate操作,UNDO空间需要rollback完成之后才能释放,由于索引导致rollback比较慢,UNDO一直不能释放,进而导致执行不了其他SQL。
解决方法及规避方式
1、删除索引,加快rollback
2、线上操作需要避免出现大事务,使用imp、yasldr等工具分批提交,或者在insert into select中添加where条件,分批提交。
3、执行数据迁移过程,规划好UNDO空间。
4、导入数据过程先去掉索引,待数据导入完之后重建索引。
问题分析和处理过程
核查相应参数:
-
机器配置为16核64g
-
UNDO_RETENTION为300
-
STARTUP_ROLLBACK_PARALLELISM 为2
-
V$ROLLBACK为空
-
UNDO文件为64G
-
user_segments中目标表的segment大小约100G
-
表一共493752518行,数据量大
-
CHECKPOINT_INTERVAL=100000、CHECKPOINT_TIMEOUT=300为默认值
尝试添加UNDO数据文件:不成功
返回报错,报错信息YAS-02042 cannot execute tablespace DDL when the database is rolling back。由于数据库被kill重启, 该报错是正常的。
分析是否需要调整回退线程数量:不需要
STARTUP_ROLLBACK_PARALLELISM可以在数据库启动的时候决定回退线程数量,并启动相应的回退线程。从CPU的情况看,消耗很低, 瓶颈不在rollback线程, 调整需要重启,决定不调整该参数。
尝试调整UNDO保留时间:效果不明显
已提交事务的UNDO会变为可回收,为了减少已提交事务占用较多空间,强制所有提交的事务立即写入数据文件,执行了如下操作:
alter system set UNDO_RETENTION = 3;
ALTER SYSTEM CHECKPOINT;
操作后,UNDO表空间使用没有明显减少
联系客户删除索引,待数据导入完成之后再重建索引,效果明显
查看IOSTAT,结果: 读20+M/s, 写400K/s。写入数据相对较慢, 检查表目标表DDL, 存在较多索引。
删除后IO读20+M/s, 写4M/s,写速度明显提升, 20分钟后客户反馈rollback完成。
分析执行其他操作报错原因
检查UNDO表空间大小,确认最大值是64G,这也解释了为什么一个事务rollback影响后续其他业务执行都报错YAS-02016 no free undo blocks, 是因为UNDO表空间满了,在rollback完成之前不会释放。
UNDO空间大小有默认安装参数,在没有修改的情况下最大值是64G, 虽然会自动扩展, 但是在到达最大值之后,不会再扩展。
和客户确认是没有做过修改, 核查V$datafile视图, 最大值确认是64G
https://doc.yashandb.com/yashandb/22.2/zh/%E5%B7%A5%E5%85%B7%E6%89%8B%E5%86%8C/yasboot/%E5%BB%BA%E5%BA%93%E5%8F%82%E6%95%B0.html
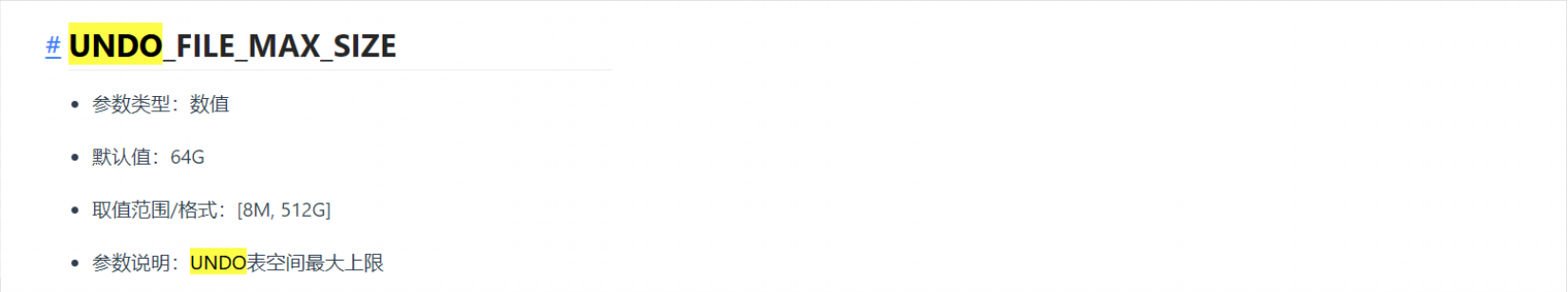
重新执行数据插入
客户在rollback之后添加多2个UNDO表空间文件, 扩大UNDO的空间扩展上限,同时修改插入语句,分批插入数据,避免大事务。
经验总结
1、数据写入、rollback过程,需要对索引做相应的修改,为了加快速度,可以先删除或把索引设置为UNUSABLE,待完成之后再建索引,或rebuild索引。
2、线上操作要避免出现大事务,使用imp、yasldr等工具分批提交,或者在insert into select 中添加where条件,分批提交。
3、执行数据迁移过程,规划好UNDO空间。UNDO空间大小默认最大值是64G,虽然会自动扩展,但是在到达最大值之后,不会再扩展,可以修改最大值限制,或添加数据文件。