【八】一小时速通Python
本章内容服务于香橙派下的开发,用C语言的视角来学习即可,会改就行。
详细说明,请看链接:python全篇教学
Python是一种动态解释型的编程语言,Python可以在Windows、UNIX、MAC等多种操作系统上 使用,也可以在Java、.NET开发平台上使用。
文章目录
- 【八】一小时速通Python
- 1.Python的特点
- 2.编写第一个程序
- 3.输入输出变量
- 4.流程控制
- 5.列表
- 6.元组
- 7.字典
- 8.函数
- 9.模块
- 10.文件
- 11.字典的多层嵌套
- 12.总结
1.Python的特点
- Python使用C语言开发,但是Python不再有C语言中的指针等复杂的数据类型。
- Python具有很强的面向对象特性,而且简化了面向对象的实现。它消除了保护类型、抽象类、接口等面向对象的元素。
- Python代码块使用空格或制表符缩进的方式分隔代码。
- Python仅有31个保留字,而且没有分号、begin、end等标记。
- Python是强类型语言,变量创建后会对应一种数据类型,出现在统一表达式中的不同类型的变量需要做类型转换。
2.编写第一个程序
第一种运行方法:Python hello.py
创建一个python_project文件夹,在文件夹内创建一个hello.py:(其实linux系统不是很关心文件的后缀名,py也行,其他也行,但是为了格式还是写成py最好)
hello.py:
print("hello,world!")
保存退出后,输入python hello.py 即可运行程序:

第二种运行方法:./hello.py
在hello.py的开头就指定Python存放路径的解释器:
#! /usr/bin/python
print("hello,world!")
并使用chmod +x hello.py来赋予执行权限;

中文支持
如果开头加上“# -* - coding: UTF-8 -* -” 则可以支持中文显示,所以py文件的开头就默认写这两句话:
#! /usr/bin/python
# -* - coding: UTF-8 -* -
3.输入输出变量
- 输出就是刚刚演示的print函数,注意print函数会自动在打印后加上换行符;
- 获取用户输入则使用input函数
input.py:
#! /usr/bin/python
# -* - coding: UTF-8 -* -
s = input("输入内容,按下ENTER结束\n")
print(s)

==注意:==input返回的永远都是字符串,所以如果想要给 整数或者浮点数 等不是字符串的变量 赋值时,需要进行强转:a = int(a)
4.流程控制
- python不支持自增运算符和自减运算符。例如i++/i-是错误的,但i+=1是可以的。
- 1/2在python2.5之前会等于0.5,在python2.5之后会等于0。
- 不等于为!=或<>
- 等于用==表示
- 逻辑表达式中and表示逻辑与,or表示逻辑或,not表示逻辑非
if/else:
if (表达式) :
语句1
elif (表达式) :
语句2
…
elif (表达式) :
语句n
else :
语句m
for:
for 变量 in 集合 :
…
else : #一般不用
…
while:
while(表达式) :
…
else : #一般不用
…
5.列表
列表List:
-
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
-
Python有6个序列的内置类型,但最常见的是列表和元组。
-
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
-
此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
-
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
-
列表的数据项不需要具有相同的类型
list.py:
#! /usr/bin/python
# -* - coding: UTF-8 -* -
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print("list1[0]: ", list1[0])
print("list2[1:5]: ", list2[1:5])
list1.append('Google') ## 使用 append() 添加元素
list2.append(8)
print(list1)
print(list2)
del list1[2] ##使用del命令删除list
print(list1)

6.元组
- Python 的元组与列表类似,不同之处在于元组的元素不能修改
- 元组使用小括号,列表使用方括号
- 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
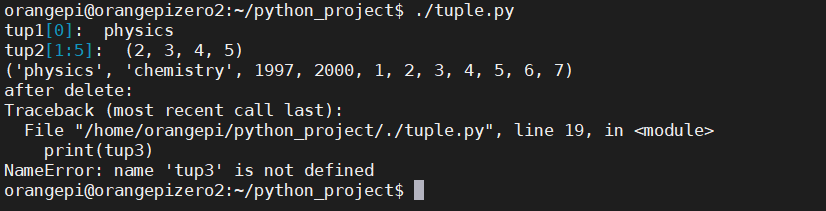
tuple.py:
#! /usr/bin/python
# -* - coding: UTF-8 -* -
tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print("tup1[0]: ", tup1[0])
print("tup2[1:5]: ", tup2[1:5])
# 以下修改元组元素操作是非法的。
# tup2[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print(tup3)
del tup3 #删除元组
print("after delete:")
print(tup3)
7.字典
-
字典是另一种可变容器模型,且可存储任意类型对象
-
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式:d = {key1 : value1, key2 : value2 }
-
dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict
-
键(key)一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一
-
值(value)可以取任何数据类型,但键(key)必须是不可变的,如字符串,数字或元组
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象
字典值(value)可以没有限制地取任何 python 对象,既可以是标准的对象,也可以是用户定义的,但键(key)不行
dict.py:
#! /usr/bin/python
# -* - coding: UTF-8 -*
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print("tinydict['Name']: ", tinydict['Name'])
print("tinydict['Age']: ", tinydict['Age'])
## print("tinydict['Alice']: ", tinydict['Alice']) #由于没有名为Alice的key,所以这句会报错
tinydict['Age'] = 8 # 更新
tinydict['School'] = "RUNOOB" # 添加
print("tinydict['Age']: ", tinydict['Age'])
print("tinydict['School']: ", tinydict['School'])
del tinydict['Name'] # 删除键是'Name'的条目
tinydict.clear() # 清空字典所有条目
del tinydict # 删除字典

8.函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- 函数内容以冒号起始,并且缩进
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
func.py:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def printme( str ):
#"打印任何传入的字符串"
print(str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")

9.模块
support.py:(作为一个模块)
def print_func( par ):
print("Hello : ", par)
return
demo2.py:(调用support模块)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入模块
import support
#也可以 import print_func from support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
#这里可以直接写成print_func("Runoob") 如果刚刚写成import print_func from support

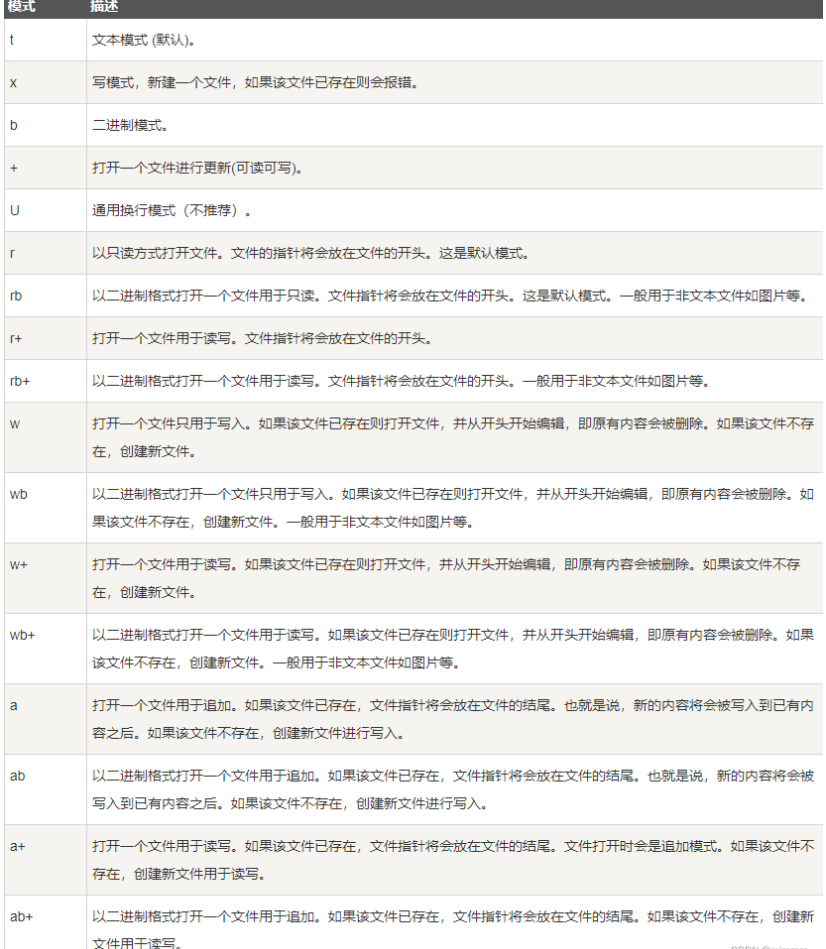
10.文件
file.py:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件,只写,且文件不存在就创建
fo = open("foo.txt", "w")
#写内容
fo.write( "mjm! Very good!\n")
# 关闭打开的文件
fo.close
# 打开一个文件,读写
fo = open("foo.txt", "r+")
#读内容
str = fo.read(20)
print("读取的字符串是 : ", str)
# 查找当前位置
position = fo.tell()
print("当前文件位置 : ", position)
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(20)
print("重新读取字符串 : ", str)
# 关闭打开的文件
fo.close()

为什么不直接用r+读写打开之后直接写?
因为foo.txt不存在,而r+不支持创建文件,所以可以先使用w只写打开,w支持“如果文件不存在就创建”
11.字典的多层嵌套
这里为什么要加一节这个呢?
在后面我们要用到阿里云的服务平台,他的Python接口返回的就是一个字典的嵌套,我们需要对他进行一个处理,在这里直接讲述
KEY值可以用数字,字符串或元祖充当,但用列表就不行。
下面这里有一个字典嵌套数据,我们想要获取里面的干垃圾,应该如何写代码?一层一层剥离出来
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tinydict ={'name':'runoob','likes':123,'url':'www.runoob.com'}
garbage_dict = {'Data':{'Elements':[{'Category':'干垃圾','CategoryScore':0.8855999999999999,'Rubbish':'','RubbishScore':0.0}],'Sensitive':False},'RequestId':'1AB9E813-1AB9E813-3781-5CA2-98A0-1EA334E80663'}
dict2.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tinydict ={'name':'runoob','likes':123,'url':'www.runoob.com'}
garbage_dict = {'Data':{'Elements':[{'Category':'干垃圾','CategoryScore':0.8855999999999999,'Rubbish':'','RubbishScore':0.0}],'Sensitive':False},'RequestId':'1AB9E813-1AB9E813-3781-5CA2-98A0-1EA334E80663'}
data = garbage_dict['Data']
print("data=",data)
elements=data['Elements']
print("elements=",elements)
element=elements[0] #去列表第0个元素
print("element=",element)
category=element['Category']
print("category=",category)
category2=garbage_dict['Data']['Elements'][0]['Category']
print("字典支持一步到位:",category2)

12.总结
在前面简单介绍了dict(字典)的使用,字典(Dictionary)是Python里非常常见的一种数据结构,如果是在其他语言里,一般称做
map。是由键(key)和值(value)成对组成,键和值中间以冒号":“隔开,键值对之间用”,“隔开,整个字典由大括号”{}"括起来。
格式如下:
dict = {key1 : value1, key2 : value2 }
如例子:
tinydict = {'name': 'runoob', 'likes': 123, 'url': 'www.runoob.com'}
这里面,键一般是唯一的,如果重复了, 最后的一个键值对(Key:value)会替换前面的。 而且键可以用数字,字符串或元组充当,用列表不行。而且值就不需要唯一,而且形式多样,比如可以以列表或者dict的形式出现。
dict的使用非常灵活, 甚至可以和列表组合使用, 列表里能嵌套列表,也能嵌套字典。同样的,字典里能嵌套字典,字典里也能嵌套列表。
如下面这个例子:
garbage_dict = {'Data': {'Elements': [{'Category': '干垃圾', 'CategoryScore': 0.8855999999999999, 'Rubbish':'', 'RubbishScore': 0.0}], 'Sensitive': False}, 'RequestId': '1AB9E813-3781-5CA2-95A0-1EA334E80663'}
这个例子里的dict内容是就是一个嵌套的结构,也就是说,它包含了其他的dict或列表作为值。我们可以用以下的方式来理解它:
- 最外层的dict有两个键:‘Data’和’RequestId’。
- 'Data’对应的值是一个内层的dict,它有两个键:‘Elements’和’Sensitive’。
- 'Elements’对应的值是一个列表,它包含了一个元素,也就是另一个内层的dict。
- 这个内层的dict有四个键:‘Category’、‘CategoryScore’、‘Rubbish’和’RubbishScore’。
- ‘Category’对应的值是一个字符串,表示垃圾分类的类别,例如’干垃圾’。
- 'CategoryScore’对应的值是一个浮点数,表示垃圾分类的置信度,例如0.8856。
- ‘Rubbish’对应的值是一个字符串,表示垃圾的具体名称,例如’'(空字符串)。
- 'RubbishScore’对应的值是一个浮点数,表示垃圾名称的置信度,例如0.0。
- 'Sensitive’对应的值是一个布尔值,表示是否涉及敏感信息,例如False。
- ‘RequestId’对应的值是一个字符串,表示请求的唯一标识符,例如’1AB9E813-3781-5CA2-95A0-1EA334E80663’






![[flink]部署模式](https://i-blog.csdnimg.cn/direct/de368a824de2490cb5d56e8c9446eb77.png)












