概述
本文分析了人工智能(AI)技术的发展在缩小人类知识库方面的潜力。
作者认为,如果大语言模型(LLMs)等人工智能技术迅速发展,人工智能生成的内容成为人类接触的大部分信息,那么长尾知识,即少数人的观点和专业知识,可能会被忽视和丢失。这被定义为 “知识的崩溃”。
过去,新信息技术对知识的产生和传播产生了重大影响,书面文字的兴起破坏了文字记忆和复习的实践,互联网搜索算法的兴起导致用户态度和政治极端两极分化。本文探讨了人工智能技术的兴起可能会引发类似问题的可能性。
作为一个具体的模型,我们设置了这样一个情境:一个人正在考虑是选择传统的学习方法还是人工智能辅助的学习方法。个人的选择基于从真实知识分布中获取样本所获得的收益。而公共知识分布则是个人获得的样本的集合。
模拟分析表明,当人类过度依赖人工智能生成的内容时,公共知识就会严重偏离事实真相,趋向于有偏见的狭隘观点。但是,如果人类能够战略性地选择信息来源,并认识到尾部知识的价值,就可以防止知识崩溃。
因此,本文认为应采取措施减轻人工智能技术的影响,如遏制越来越多地使用 LLM,并确保获取各种信息来源。本文还详细分析了通过人工智能与人的互动来构建知识的过程,以及在教育环境中使用人工智能时需要考虑的重要因素。
换句话说,本文从理论和实证角度分析了随着人工智能的发展人类知识库缩小的风险,并提出了避免这种风险的措施,是一项意义重大的研究。
论文地址:https://arxiv.org/pdf/2404.03502
源码地址:https://github.com/aristotle-tek/knowledge-collapse
相关研究
在研究人工智能技术的影响时,本文强调了迄今为止相关研究的以下主题
首先是社交媒体中的 "过滤泡沫 "或 "回音室 "问题。这表明舆论极度两极化,因为用户只能接触到符合自己信仰和偏好的信息,而无法接触到各种各样的信息。
其次,它还指一种被称为信息级联模式的现象,在这种模式下,个人的私人信息得不到有效汇总,从而产生从众行为。
此外,网络分析的结果还探讨了社交媒体信息传播失真的机制。
另一方面,还解决了大型语言模型(LLM)特有的一个问题,即 “模型崩溃”,也就是人工智能在自生成数据上进行训练导致的输出下降。
基于之前的这些研究,我们可以理解,本文试图分析人类对人工智能生成的信息的依赖可能会扭曲整个知识体系。
建议方法
该模型允许个人在从真实知识分布中获得的信息和从人工智能生成的信息中获得的信息之间做出选择,并设定贴现率。
 [图 1 个人的信息选择过程
[图 1 个人的信息选择过程
个体通过从真实知识分布中采样而获益,但人工智能生成的信息成本更低,因此个体必须在权衡中做出选择。
所获得的信息被汇总到公共知识分布中,但由于单个战略行动并不一定会带来公共知识的改善,因此可能会出现知识衰减。
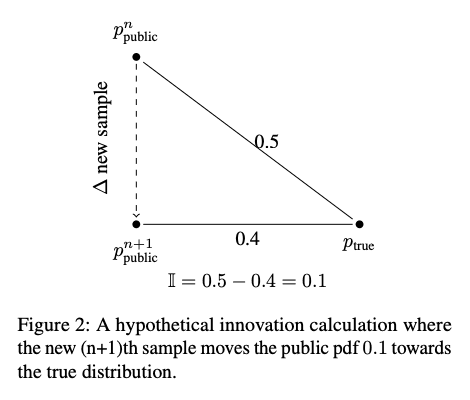
[图 2] 公共知识分布的形成
由个人选择汇总的信息形成了公共知识分布,但偏离真实分布的可能性是个问题。我们还考虑了知识加速衰减的可能性,因为新一代人学会将上一代人的知识分布视为具有代表性。
试验
本文利用提出的模拟模型,分析了人工智能生成的信息的利用程度如何影响知识衰减。
首先,图 3 显示了使用人工智能生成的信息的折扣率与公共知识分布与真实分布之间的偏差程度(海林格距离)之间的关系。
 [图 3] 贴现率与知识衰减程度
[图 3] 贴现率与知识衰减程度
当人工智能生成的信息成本较低时(贴现率较高),公众知识分布就会明显偏离真实分布。另一方面,当人工智能生成的信息使用成本较高时(低贴现率),知识衰减受到抑制。
图 4 显示了个人的学习速度及其对知识衰减的影响。
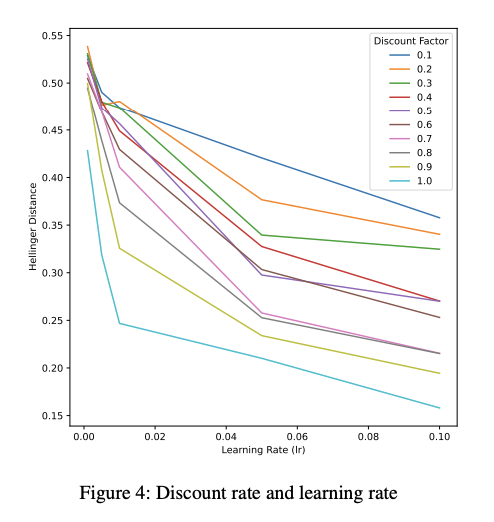
[图 4] 学习率和知识衰减
研究表明,如果个人从以前的结果中学习的速度较慢,知识衰减就更有可能加剧。不过,也有人认为,即使贴现率较高,较快的学习速度也可能减少知识衰减。
根据这些结果,本文认为,如果个人能够战略性地选择信息来源,并认识到尾部知识的价值,就能防止因过度依赖人工智能生成的信息而导致知识衰减。
结论
最后,论文指出了 "知识崩溃 "的可能性,即如果人类接触的大部分数据因人工智能技术的发展而被人工智能生成的内容所取代,那么人类的知识体系就会变得偏向于中庸信息。
模拟结果表明,过度依赖人工智能生成的信息会导致公共知识严重偏离真相,并忽视长尾知识。另一方面,如果人类能够战略性地选择信息来源,并认识到尾部知识的价值,那么这一问题就可以得到缓解。
因此,本文认为,需要采取措施来减轻人工智能技术的影响,如遏制越来越多地使用 LLM,并确保人们能够获得多样化的信息来源。
报告还讨论了未来前景,包括需要更详细地分析通过人工智能与人的互动来构建知识结构的过程,以及在教育中使用人工智能时考虑因素的重要性。
换句话说,本文从理论和实证角度分析了随着人工智能的发展人类知识库缩小的风险,并提出了避免这种风险的措施,是一项意义重大的研究。