本文的主要工作就是复现下述论文中的算法。
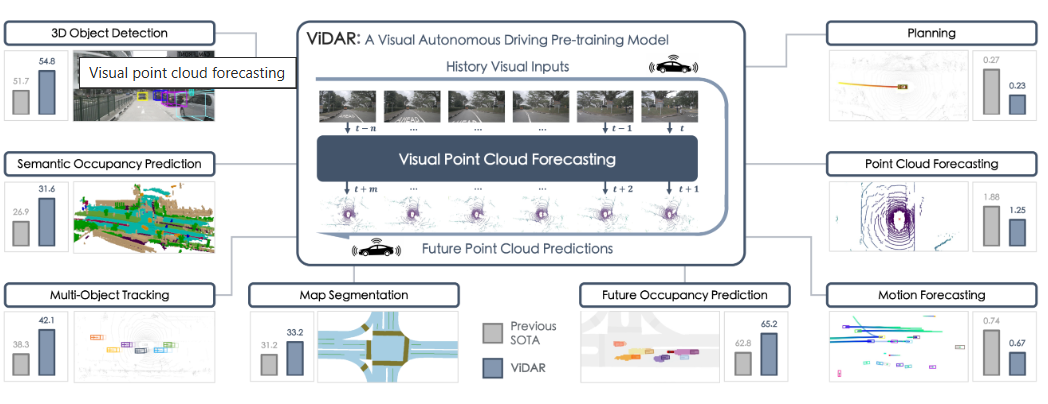
该论文全称:Visual Point Cloud Forecasting
论文内容在此不做过多介绍,直接上项目。
一、准备工作
首先通读readme.md文件的内容,了解所需要的相关依赖和数据等内容。
一定要多读几遍,不要扫一眼就过了。
接下来就是部署环境,根据readme.md文件的内容直接部署环境即可。他们这里给的部署环境的步骤还是较为详细的。
由于我电脑内存不够的原因,我在这里使用的是AutoDL上面的算力,它默认的就是Linux环境。至于AutoDL怎么用,可以去官网看帮助文档。
如果你嫌配置环境过于麻烦,可以后台私信我,我这边直接把AutoDL上的环境的镜像免费共享给你。
我的环境:
Linux:ubuntu18.04
GPU:RTX 4090(24GB) * 4
接下来就是打开pycharm,看看有没有什么导包的错误(导包时的路径问题)将其修改正确。
二、准备数据
在AutoDL中的autodl-pub文件夹中有nuScenes数据集,所以我这边直接就使用了这里面的数据。
接下来在ViDAR这个项目里面创建一个data文件夹,把下图中两个文件夹里面的数据解压至data里面。
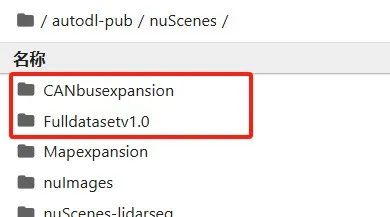
需要注意的是,不用解压Fulldatasetv1.0文件夹中的Mini数据
数据解压准备好后,data文件夹应该长这样
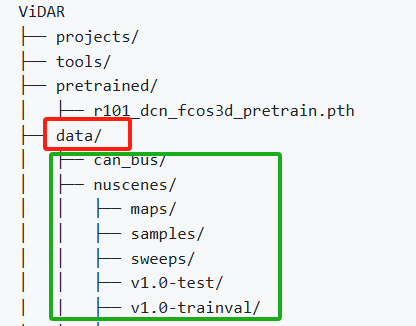
如果不是这样也不用急,运行后面的代码时改一下路径即可
接下来就是运行下面的代码生成一些pkl文件
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0 --canbus ./data如果你的路径和上图中的不一样,你需要手动改一下这个命令。
在运行这个命令之前,你会发现create_data.py文件中许多库是报红没有的,但是针对nuScenes数据集,这些报错不用理会。当正式运行这些命令时,会出现几个报错,提示你需要安装这几个包,例如 lyft-dataset-sdk,nuscenes-devkit等,此时你需要根据提示进行相应库的安装
运行完上述命令后,再根据readme.md文件中的内容,运行下述命令
python tools/merge_nusc_fullset_pkl.py需要注意的是,运行时需要把里面的路径换成绝对路径,否则有可能会报错,如下图所示:
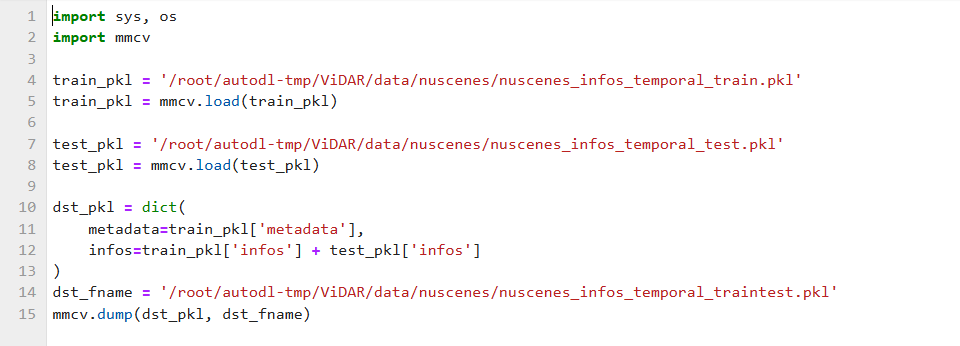
三、训练模型
CONFIG=path/to/config.pyGPU_NUM=8./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
根据readme文件中的内容,运行上述命令。
其中CONFIG是你要使用的配置文件,我这边使用了项目中提供的一个阉割版配置文件mem_efficient_vidar_1_8_nusc_3future.py,GPU_NUM是你要使用多少个GPU训练模型,我这边使用的是4个。
确定好使用的配置文件和GPU数量后,把CONFIG和GPU_NUM添加到环境变量中去,具体方法如下:
vi /etc/profile
# 把下面这两句话加进去
export CONFIG=/root/autodl-tmp/ViDAR/projects/configs/vidar_pretrain/nusc_1_8_subset/mem_efficient_vidar_1_8_nusc_3future.py
export GPU_NUM=1
#保存退出后刷新环境变量
source /etc/profile接下来就是更改配置文件mem_efficient_vidar_1_8_nusc_3future.py(如果你GPU数量够的话就不用改了)

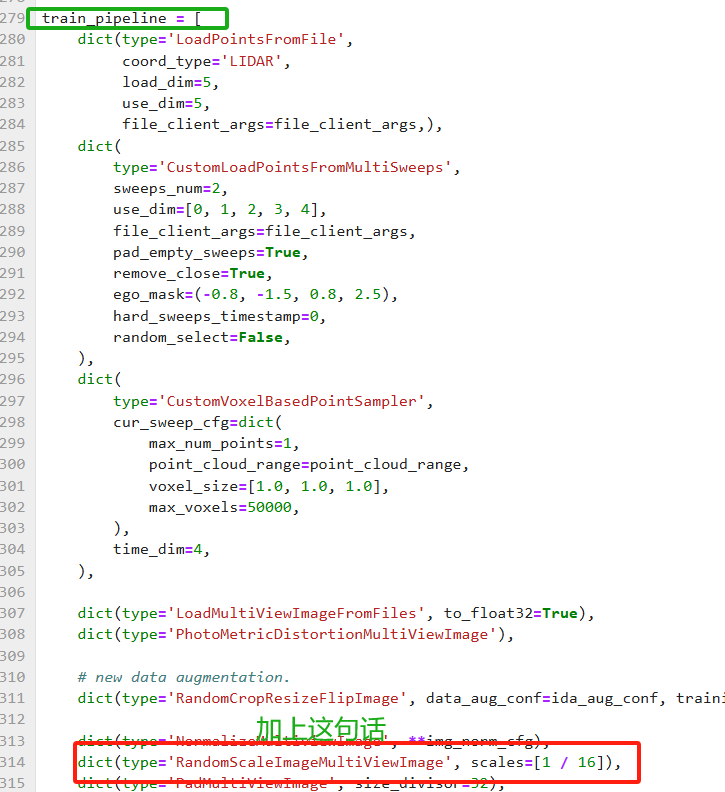
其中那个scales这个参数你可以根据你的GPU数量进行放大或者缩小
配置文件修改好后,安装DCNv3这个库(No module named 'DCNv3')
cd ViDARcd projects/mmdet3d_plugin/bevformer/backbones/ops_dcnv3sh make.sh
安装好这个库后,就可以运行./tools/dist_train.sh ${CONFIG} ${GPU_NUM}命令了,在运行这个命令时也会出现各种各样的错误。
接下来就是一些运行代码时的错误和相应解决办法。
1、报错:bash: ./tools/dist_train.sh: Permission denied
解决办法chmod u+x tools/dist_train.sh
2、报错:/usr/bin/env: ‘bash\r’: No such file or directory
解决办法sudo apt-get install dos2unix,再执行dos2unix tools/dist_train.sh
3、报错:AttributeError: module 'PIL.Image' has no attribute 'LINEAR',
解决办法根据报错信息,修改detectron2/data/transforms/transform.py文件内容python3.8/site-packages/detectron2/data/transforms/transform.py中第46行代码,把LINEAR替换为BILINEAR即可
4、报错:File "/root/miniconda3/envs/vidar/lib/python3.8/site-packages/mmcv/utils/config.py", line 496, in pretty_text
text, _ = FormatCode(text, style_config=yapf_style, verify=True)
TypeError: FormatCode() got an unexpected keyword argument 'verify'
解决办法修改/root/miniconda3/envs/vidar/lib/python3.8/site-packages/mmcv/utils/config.py文件的第496行,text, _ = FormatCode(text, style_config=yapf_style)(把verify=True删除)
5、报错:AssertionError: ViDAR: ViDARHeadV1:During handling of the above exception, another exception occurred
解决办法
修改ViDAR/projects/mmdet3d_plugin/bevformer/dense_heads/vidar_head_v1.py第四十一行代码

6、报错File"/root/miniconda3/envs/vidar/lib/python3.8/sitepackages/torch/utils/tensorboard/__init__.py", line 4, in <module>
LooseVersion = distutils.version.LooseVersion
AttributeError: module 'distutils' has no attribute 'version'
解决办法:修改torch/utils/tensorboard/__init__.py文件中的内容将from setuptools import distutils替换成from distutils.version import LooseVersion并注释LooseVersion = distutils.version.LooseVersion和del distutils
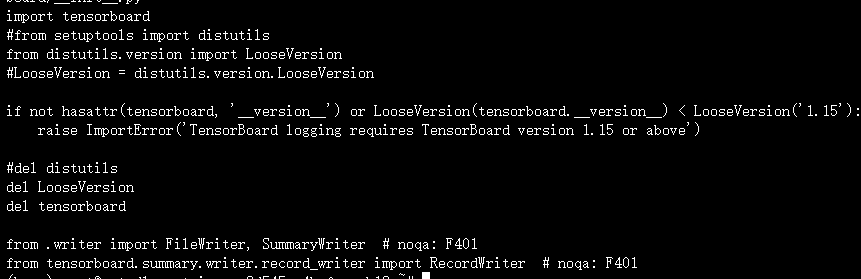
7、报错:NotImplementedError: Got <class 'dict'>, but numpy array, torch tensor, or caffe2 blob name are expected
解决办法:
打开 mmcv/runner/hooks/logger/tensorboard.py 文件。
找到 log 方法并将其修改为下面的代码。
def log(self, runner):
tags = self.get_loggable_tags(runner, allow_text=True)
for tag, val in tags.items():
if isinstance(val, str):
self.writer.add_text(tag, val, self.get_iter(runner))
elif isinstance(val, dict):
# 如果 val 是一个字典,展开并记录每个键值对
for sub_tag, sub_val in val.items():
self.writer.add_scalar(f"{tag}/{sub_tag}", sub_val, self.get_iter(runner))
else:
self.writer.add_scalar(tag, val, self.get_iter(runner))四、验证模型
CONFIG=path/to/vidar_config.pyCKPT=path/to/checkpoint.pthGPU_NUM=8./tools/dist_test.sh ${CONFIG} ${CKPT} ${GPU_NUM}
这里面的CKPT就是权重,我的如下:
export CKPT=/root/autodl-tmp/ViDAR/work_dirs/mem_efficient_vidar_1_8_nusc_3future/epoch_24.pth接下里就开始运行
./tools/dist_test.sh ${CONFIG} ${CKPT} ${GPU_NUM}运行时会遇到和训练模型时一样的问题,可以参考上面的解决方法。
RuntimeError: NCCL error in: /opt/conda/conda-bld/........../ProcessGroupNCCL.cpp:911, unhandled system error, NCCL version 2.7.8
ncclSystemError: System call (socket, malloc, munmap, etc) failed.
解决办法:
运行export NCCL_IB_DISABLE=1; export NCCL_P2P_DISABLE=1; NCCL_DEBUG=INFO NCCL_SOCKET_IFNAME=eth0 ./tools/dist_test.sh ${CONFIG} ${CKPT} ${GPU_NUM}
(这里的eth0怎么看(ifconfig -a))
也可以把 export NCCL_IB_DISABLE=1;
export NCCL_P2P_DISABLE=1;
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=eth0添加到环境变量中去,从而直接运行./tools/dist_test.sh ${CONFIG} ${CKPT} ${GPU_NUM}即可RuntimeError: NCCL error in: /opt/conda/conda-bld/....../torch/lib/c10d/ProcessGroupNCCL.cpp:845, internal error, NCCL version 2.7.8
ncclInternalError: Internal check failed. This is either a bug in NCCL or due to memory corruption
解决办法:
在test.py文件中放入以下几行代码
import os
os.environ["NCCL_IB_TC"] = "128"
os.environ["NCCL_IB_GID_INDEX"] = "3"
os.environ["NCCL_IB_TIMEOUT"] = "22"五、可视化
CONFIG=path/to/vidar_config.pyCKPT=path/to/checkpoint.pthGPU_NUM=1./tools/dist_test.sh ${CONFIG} ${CKPT} ${GPU_NUM} \--cfg-options 'model._viz_pcd_flag=True' 'model._viz_pcd_path=/path/to/output
把里面的/path/to/output改成你自己的随意创建的文件夹即可
至此,项目运行结束。
六、结语



















