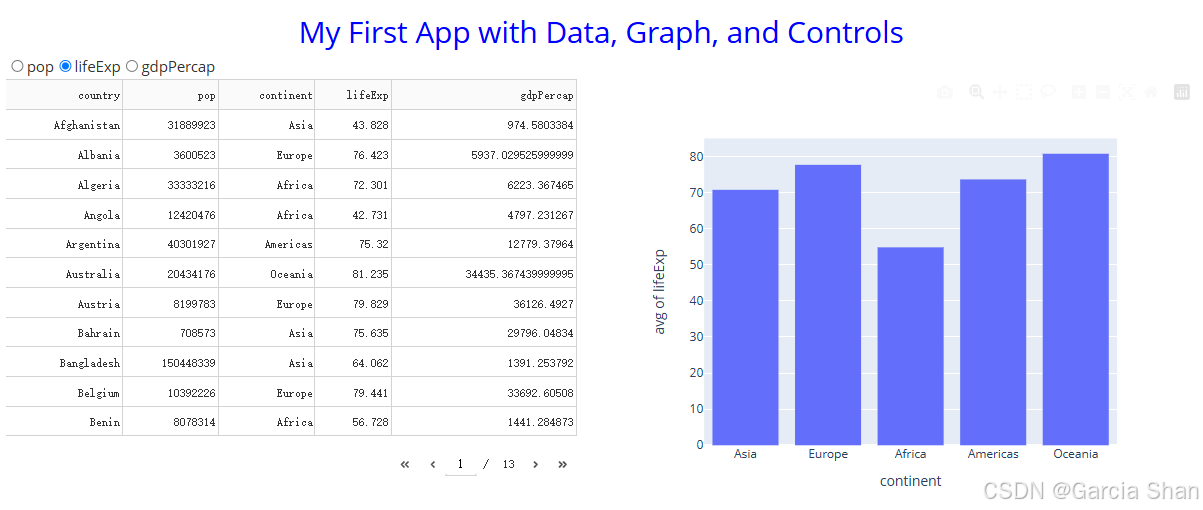
目录:
思维导图
一· 程序的翻译环境
二· 程序的执行环境
三· C 语言程序的编译和链接
四· 预定义符号
五· 预处理指令
六· 宏和函数对比
七· 预处理操作符# 和 ##
八· 命令定义
九· 预处理指令#include
十· 预处理指令#undef
十一· 条件编译
WeChat_20240731222905
1· 程序的翻译环境
对于人机交换的计算机而言,他并不是一上来就能看懂我们直接写的代码的。这就好比一个只会说英语的外国人与一个只会说汉语的中国人进行交流一样,必须借助一个进行翻译的人员,才可以进行正常的交流。
对于计算机而言,是一样的道理。在我们编写的代码被执行之前需要经过2个不同的翻译环境
一个是翻译环境,一个是执行环境
翻译环境:把源代码转换成可执行的机器指令。
执行环境:进行代码的执行。
2· C 语言程序的编译和链接
2.1编译的环境

对于一个工程而言,可能不止一个源文件。每一个源文件都是单独经过编译器进行编译,生成对应的目标文件(后缀.obj)(注意:仅在Windows 环境下) 。
此时链接库经过链接器的处理和所有生成目标文件经过链接器处理,最终生成可执行程序(后缀.exe)
总的来说,一个程序的翻译环境大致分为2个过程:编译和链接。
2.2 编译的多个阶段
其实对于源文件进行编译的这个过程还有许多的过程。

过程1:预编译(预处理)
此过程主要是对文本进行操作。对所有的预处理指令(#include 包含的文件进行展开,#define 定义的符号进行替换)进行预处理,会生成对应的一个文件。
接下来主要是对预编译完之后文件的内容进行查看(注意:Linux系统)

打开服务器,使用Vim 这个编辑器进行一个文件(Test.c)的写入,文件名字大家随意,但是必须以.c为后缀,把此段程序写入后退出,敲下命令 gcc -E test.c -o Test.i
此指令的含义:预处理完之后就停下来,把生成的结果放到Test.i这个文件里面
这是对应Test.i 这个文件里面的内容:通过观察,对# include<stdio.h> 这个头文件所包含的内容进行了展开

过程2:编译
此过程的主要功能是进行语法的分析,符号的汇总,词法的分析,语义的分析;把C语言代码翻译成汇编指令(注意此处的汇编指的是一种指令)。
查看编译完之后对应文件内容,敲下指令:gcc -S Test.c -o Test.s

此时文件的内容都是一些汇编指令。
过程3:汇编
此过程的功能是形成符号表同时生成目标文件后缀 .o (Linux系统下);把汇编指令翻译成二进制指令
对应的指令是: gcc -c Test.c -o Test.o
此语句含义:直接把Test.c 这个文件最终执行汇编完放到 Test.o 这个文件里面

最终的链接:
此时所有的链接库和所生成的目标文件经过链接这个过程生成对应的可执行程序。
链接过程 主要功能是:合成断表;符号表的合成以及符号表的重定位(比如通过符号表找到调用
函数的地址)
2.3 运行环境
3· #define
3.1 预定义符号

简单使用:

3.2 #define 定义宏
3.2.1 宏的定义
3.2.2 宏的具体使用
1) 定义一个宏:求2个数的最大数
#include<stdio.h>
#define MAX(x,y) ((x)> (y) ? (x):(y))
int main()
{
int a = 2, b = 5;
int max = MAX(a, b);
printf("%d\n", max);
return 0;
}2)定义一个宏:求一个数的平方

3)定义一个宏:求一个数的2倍

其实对于以上3个宏的实现 ,基本逻辑是一样的,只不过就是需要注意括号的使用
思考以下问题:

问题1:((x)+(x)) 为什么最外一层还要加一层括号? 直接(x)+(x) 这样写不行吗 ?

主要还是对于宏的使用,只会在预编译的阶段进行替换(可以说是一种“傻瓜式”的替换):

这就说明了一个问题一定不要吝啬括号的使用,对 (b)+(b) 最终加上括号 ((b)+(b)) 就能很好解决问题了。
问题2:直接(x+x)不就行了吗???

通过查看预编译完之后的文件,可以知道编译器在对宏的替换,只是“傻瓜式”替换

所以说:通过上面的错误用例,我们应该尽可能在不影响最终结果的前提下,使用()避免由于
操作符优先级引发的一系列副作用。
3.2.3 #define 替换规则
1. 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们先
被替换。
2. 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
3. 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复
上述处理过程。
4· 宏和函数对比
以一个栗子进行论证吧:
写一个求最大数的函数和求一个最大数的宏

![]()
1)有无函数栈帧开销
对于函数而言需要进行栈帧的开销:

对于宏而言没有栈帧的开销

发现汇编指令里面并没有涉及到 call 相关的指令。
2) 带有副作用的参数
对于函数而言,参数只会在传参的时候进行一次的求值
对于宏而言,可能涉及到多个位置的替换,导致最终结果可能是无法预料的

康康以上程序的运行结果是啥。

3)参数类型
对于函数而言,有参数类型的要求
对于宏而言,没有参数类型的检查
4)调试
函数支持调试;宏不能进行调试(预编译阶段已经被替换了)
5) 递归
函数支持递归;宏不支持递归
6)运行效率
宏更快,因为没有栈帧的开销;函数更慢
7)代码长度
宏的使用会导致程序代码冗余,只要是涉及到宏调用就会进行替换;对于函数而言,只出现一次,
每次调用函数的时候直接 call 调用函数地址就可以
8)操作符优先级
因为宏是“傻瓜式”替换,当涉及到操作符优先级问题的时候,可能出现误差;对于函数而言,在传
参的时候,会进行相关计算
9)命名约定
宏的名字一般全部大写;函数名字则不用(仅仅是使用习惯上的)
5· 预处理指令 #include
5.1 #include 包含文件
在预处理阶段,会把所包含的文件内容进行展开(注意次展开是指内容的拷贝,不同于C++内联函数的展开)。
当同一个文件被多次包含的时候,也会被多次展开,可能会导致所生成的文件内容冗余
5.2 包含文件的2中方式
1)#include < >
这是一种库文件包含方式,用于对于库里面头文件的包含;编译器只会直接到库里面查找;若是没有直接报错
2) #include" "
这是一种本地包含的方式;编译器会先在当前所在目录下进行查找;若是没有找到就会去库里面进
行查找,若不存在,最终报错。
可能有的老铁会有这样的问题:那对于库文件的包含是不是也可以用“”
 但是这样会降低效率
但是这样会降低效率
6· 预处理操作符 # 和 ##
先看看以下代码:


通过运行结果,我们可以得知:字符串可以进行自动拼接
是否可以借助宏进行字符串的拼接呢

6.1 #
# :这个符号作用就是把宏参数变成对应的字符串
注意:要求当字符串作为宏参数放到一个字符串里面
使用:

6.2 ##
## 作用:把位于他两边的符号合成一个符号
使用:

7· 命令行定义
7.1定义

在编译的时候指定数组 SZ大小 SZ= 10
指令: gcc test.c -D SZ=10 test
此时数组内容:

8· 预处理指令#include
8.1 #include
在预编译的阶段,# include 所包含的文件都会被进行展开(文件内容会被进行拷贝)
8.2 其他预处理指令

9· 指令#undef
作用:
用于移除一个宏定义
10· 条件编译
1)#if …… #endif

使用:

2)多分支条件编译

使用:

3)判断一个符号是否被定义过

使用:

4)判断一个符号是否没有定义

使用: